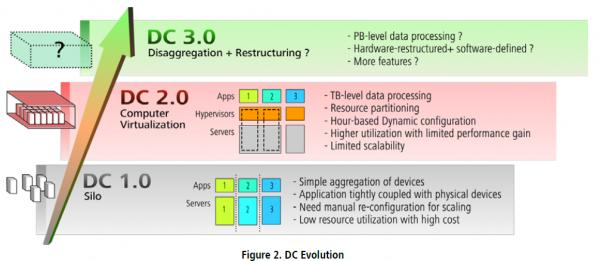
只要亚马逊的James Hamilton发言,凡是对数据中心技术有点兴趣的人都会洗耳恭听。在今年的AWS re:Invent大会上,亚马逊副总裁兼杰出工程师Hamilton描述了历时五年对驱动亚马逊网络服务(AWS)的数据中心生态系统进行的自上下而的全面整改。
网络方面需要搞定
Hamilton一开始表示,网络是需要改进的头号目标。与网络有关的成本急剧上升,而计算成本却一路下跌。首要原因是,亚马逊的工程师们无法改动现成的网络设备和现有协议,以满足负载需求。于是这家公司弄清楚了要做哪些工作,并与一家原始设计制造商(ODM)签订了合约,制造定制的网络设备。此外,亚马逊聘请了一队人马,开发一套新的协议堆栈,以减少网络层次体系和网络延迟。
值得关注的是,Hamilton在整个发言期间数次提到现成的设备从来不是企业数据中心的上好选择。现成设备旨在满足一大批客户的要求,继承了软硬件臃肿的毛病,这个问题让企业根本无法对特定的操作进行各种简化。
亚马逊数据中心生态系统概况
随后,Hamilton详细介绍了AWS当前的数据中心生态系统,首先从该公司的全球基础设施开始说起。
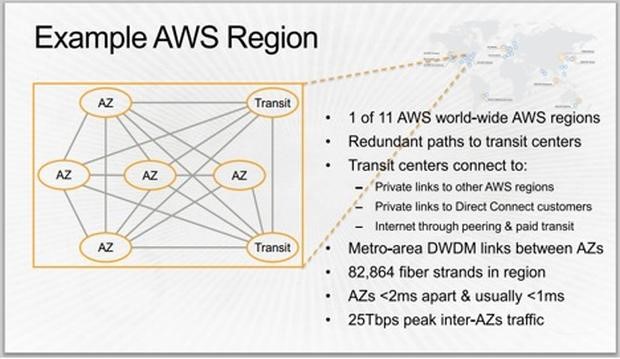
图A
AWS地区(图A):亚马逊将全球分成11个地区。这么做为亚马逊客户带来了下列优点:
- 简化了遵从数据存储方面的政府法规这项任务。
- 缩短了客户的网络与亚马逊的转运中心(Transit Center)之间的延迟。
Hamilton表示,亚马逊还很早就决定在各地区之间铺设专用光纤,这消除了争夺资源的现象,提高了可靠性,缩短了延迟,并且便于容量规划。
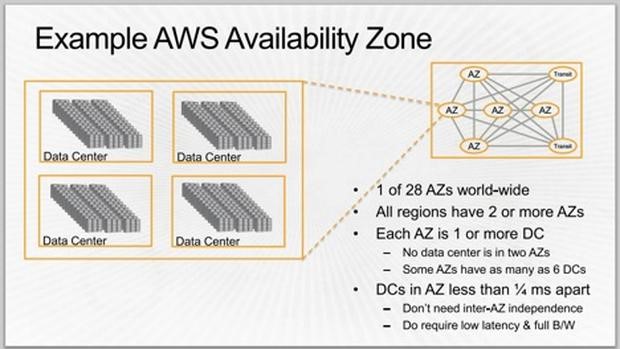
图B
AWS可用区域(图B):28个可用区域分布在AWS的11个地区,这意味着亚马逊至少建有28个数据中心。每个可用区域都有冗余路径通向转运中心和同一地区的其他可用区域,使用密集波分复用(DWDM)链路。亚马逊要求可用区域之间的延迟低于2毫秒,可用区域之间的光纤链路必须处理每秒25 Tb的流量负载。
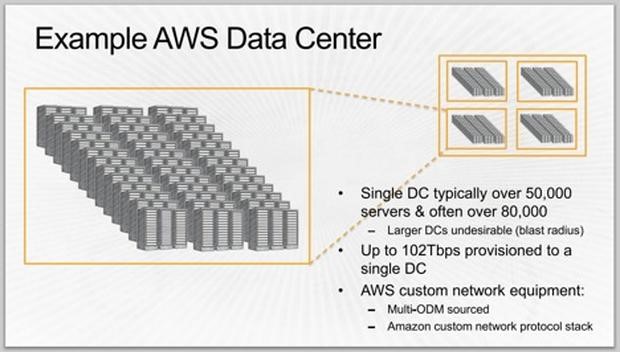
图C
AWS数据中心(图C):Hamilton提到亚马逊选定的数据中心规模为25兆瓦到30兆瓦,相当于50000台到80000多台服务器。据Hamilton声称,这个规模是最优规模:再增大规模,亚马逊的投资回报率就要下降。此外,万一出现灾难性故障,更庞大的数据中心无异于增加了风险。每个数据中心经过精心配置,以处理每秒102 Tb的负载。
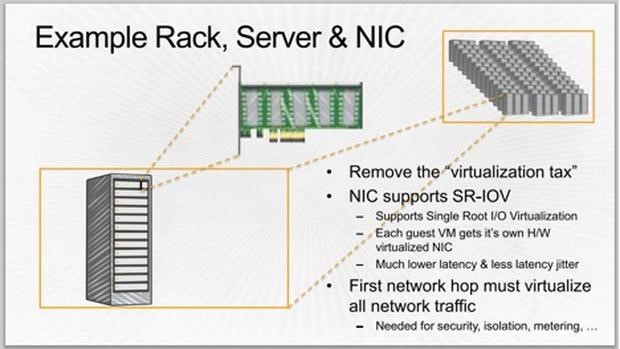
图D
AWS机架、服务器和网卡(图D):除了网络延迟外,Hamilton表示他们还发现服务器软件堆栈方面的延迟无法接受:
- 软件堆栈包括应用程序、访客操作系统、虚拟机管理程序和网卡,延迟为数毫秒。
- 流量通过网卡传输,延迟为数微秒。
- 流量通过光纤链路从一台服务器传输到另一台服务器,延迟为数纳秒。
为了消除软件堆栈延迟,现在亚马逊为每个访客提供了一块虚拟网卡,采用单个Root输入/输出虚拟化(SR-IOV)技术。Hamilton解释,使用SR-IOV方面的难点在于,弄清楚如何隔离每个虚拟网卡、防止分布式拒绝服务攻击(DDoS)以及监控容量。

图E
AWS定制服务器和存储设计(图E):之前提到了现成的网络设备对亚马逊来说是一大阻碍。Hamilton表示,现成的网络设备对服务器来说同样是一大阻碍,于是公司决定制造专有的服务器、处理器和机架:
- 服务器由亚马逊负责设计、OEM厂商负责制造。
- 处理器采用了亚马逊与英特尔共同开发的定制设计。
- 亚马逊机架里面装有864个硬盘,重量超过2000磅。

图F
AWS电力基础设施(图F):制造专有的网络设备、服务器、处理器和机架似乎并不是非同寻常。可有谁想到建造变电站?规划和建造变电站似乎是个漫长的过程,实在太漫长了,而亚马逊在不断建造数据中心。于是,亚马逊管理层认为,建造自己的变电站、消除瓶颈对公司最有利。
至于电力方面,与谷歌和微软一样,亚马逊也青睐电力采购协议(Power Purchasing Agreements)以及相关的可再生能源证书(Renewable Energy Certificate)。
Hamilton的结束语
Hamilton在发言结束时谈到了亚马逊的“创新步伐”。AWS在迅速发展,这就带来了一些管理方面的问题:在竞争激烈的市场如何保持灵活。Hamilton语气欢快地声称,AWS正以更快的步伐交付更多的服务,可靠性也有所增强。
英文原文链接:http://www.techrepublic.com/article/a-look-at-amazons-world-class-data-center-ecosystem/