













免责声明:我是一个工程师,拥有10年以上的 WEB 后端开发经验,大部分职业生涯都在编写 Python代码。所以本文大部分文字描述可能跟软件开发的其他领域无关,同样的,也跟使用 JVM 或 CLR 的开发者无关,他们只是用不同的方式解决问题。
开发Web应用程序看起来与我们10年前做的有很大的不同。现在,我们用微服务建立的一切。它彻底改变了我们的应用程序的架构。
| 2014年,如果你还在构建完整巨大的 web 应用程序,你需要改变这一行为,否则很快会被解雇 |
虽然我们的应用程序的设计发生了很大变化,但是我们的工具没有。这里我要介绍未来我会如何编写微服务。但是,首先,让我们来看看我们有什么。
全局解释锁
对于声名狼籍的Python GIL,Python的支持者说的比较多的是其他的脚本语言也有(Ruby,Perl,Node.js,还有一些)。对于不好的语言解释器的设计,这是圣战的源头,但这对于web应用从来不是问题。我们总是以来许多进程共享一个数据库。
在微服务面前,全局解释锁更加不是问题了。在大多数情况下,单个微服务甚至比十年前的典型web应用还小。尽管很小,它每秒也可以处理大量的请求,大多数是因为它针对查询的类型,进行了高度的定制化和很好的调整。
而当构建的微服务需要等待其他服务回复的时间时,这开始成为一个问题。好戏由此开场。。。
| “异步I / O,或非阻塞I/ O是输入/输出处理的一种形式,它允许其他进程继续在传输完成之前。”- 维基百科 |
任何异步库基本是从左侧到右侧的流程来调整代码的:
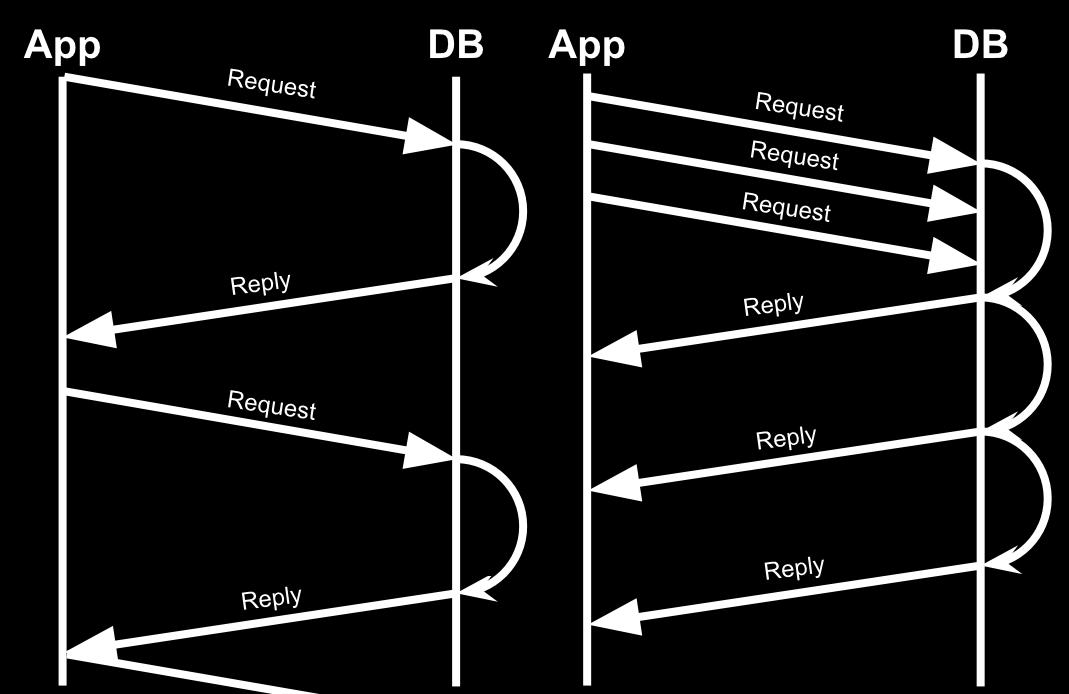
同步(左)与异步(右)请求进程对比图
Python的异步I/O支持是相当的好。有一堆库可以做这个工作(Twisted, Tornado, Gevent, Eventlet,这里仅列举几个)。每个库都支持很多协议。你可以使用MySQL, Mongo, PostgreSQL, Redis, Memcache, ElasticSearch...,几乎每个DB,和许多其他得服务。一些奇异的协议,像SSH或者Beanstalk只在几个库中支持。不过这些都不是问题,写另一个协议或从一个I/O框架移植到另一个也不是很难。
当然,每一个I/O库都支持客户端和服务端HTTP。想必,这就是为什么HTTP是最常见的用于微服务之间通信的协议。不过大多数框架也支持各种其他协议(msgpack-rpc, thrift, zeromq, ice,这里仅列举几个)。
有很多框架存在,彼此在不同协议的使用便捷性和其他种类的并发抽象上的有所不同。当然对不同协议的支持已经变得越来越流行。直到Twisted在2002年发布,这种状况才有所改变。是的,即使当python支持了yield和stackless及greenlets出现,便捷性确实大大增加了,但是这也仅仅是增加一点点的便捷性。真正的改变是在2002年。
但是有些事情是大多数Python框架的弱项。当你在一个线程中操控很多个客户端的请求时,你有可能把它们管道进单个连接中。也就是说,如果你在前端有三个GET请求,你可能向MySQL数据库发送三次请求,但不等待回复。一旦收到(数据库)的数据就尽快回复客户端。就像上面图中表示的,但是使用了单个DB连接。大多数python框架现在,在请求开始时从连接池中拉取一个连接,在请求结束时释放连接,这样高效的保证连接数目与同时请求数目相等。
对于多数数据库来说,成千上万个连接仍然是个问题。即使的典型的Sharding也无济于事,因为对每个shard来说也是相同数目的连接。很多用户采用了特殊的微服务(microservice)。这不仅仅是数据库的问题,许多微服务(microservice)也同样遇到这样问题。
幸好asyncio架构允许更容易的构建流水线(pipelining),所以越来越多的asyncio协议采用这种技术。不幸的是连接代价巨大的数据库(比如MySQL和PostgreSQL)使用了不支持(该技术)的C库,而且没有人有足够的重视来写一个更好的。
使用像Resque一样的发布-订阅
当前,许多工程团队围绕着发布-订阅来构建微服务(microservices)架构。比如,他们运用RabbitMQ或者其竞争者之一的产品将所有内容发布成消息(message)。他们相信这是简化他们的建构:
1.单总线(Single Bus),无须再考虑这个
2.能够无需等待回复即可发布消息。不需要任何异步库即可高效的获取异步I/O
当部分工程师们以为这就是答案的时候,我认为这不适合普遍的情况。
| 我认为将我的设计决策限制在使用特定插件及特定的消息调度算法不会解决我的所有网络问题。 |
另一个颇具魅力的微服务架构是Zeromq。如果你对它不熟悉,你应该尽快了解它。Zeromq只不过是巧合的使用MQ(消息队列)作为后缀,毕竟它不像 RabbitMQ,Kafka以及其他的那样拥有中心消息队列。它是以socket形式工作在steroids。也就是说,它看起来就像常规的socket,确实会自动发送消息(分割TCP数据流为帧),重新连接,点对点平衡加载等等。
在 Zeromq 世界里有三种方式供你的服务于其他连接:
1.发布-订阅,工作方式基本上和其他发布-订阅应用程序相同
2.请求-回复,基本与RPC工作方式相同
3.Push-Pull,请求却不需要回复,或者发布-订阅发送消息到单一接收端(基于轮叫)
Nanomsg 做到了更多事情,它不仅支持上面提到的所有方式,而且增加了更多的通信模式(单就nanomsg而言):
1.监督者-应答者(Surveyor-respondent),允许向多点发送请求而且接收来至所有的请求
2.总线(Bus),允许向任何点发送消息
更多的是:nanomsg的前景在于通信模式是插件式的,也就是说,在未来更多的通信模式会被增加到库中。
| 我相信更多的通信模式会出现,而使用发布-订阅或者HTTP难逃厄运 |
像nanomsg和zeromq作为脚本语言的优势是:它们在一个单独的线程中操控I/O。所以当你使用python做一些事情操控全局解释器锁(GIL)时,你的zeromq线程保持你的连接,清空消息缓冲器,接收和建立连接等等。
真实世界中的微服务
当聪明的黑客们创建了像 zeromq 、 nanomsg 和发布-订阅总线( publish-subscribe buses )这样优秀的项目的时候,实干的工程师们却仍然使用旧的技术干活。
到目前为止我还没有看到使用 zeromq 作为数据库存取通讯方式的数据库。嗯,现在是有很少一些使用了 zeromq 的开源服务。基本上所有现代的数据库在通讯方式的实现上目前分成了以下两个阵营:
1.创建并使用自身协议
2.使用 HTTP 协议
在这个方面数据库算是个比较突出的例子。另外的例子比如 Docker , Docker 使用了基于 unix sockets 的 HTTP 协议作为其通讯协议,然而,当她需要使用全双工流( full-duplex streams )来替代请求-回应( request-reply )模式的时候,就只能很不优雅地打破了其使用的协议的语义( protocol semantics )。
HTTP协议
我不得不说一些关于HTTP的事情。
对HTTP的支持普遍存在,但是使用python会很低效。不仅是因为不能像zeromq那样在其他线程处理事务,对HTTP解析也很缓慢。常常持久连接(keep-alive connection)也不受支持。
同时HTTP是复杂的,如果你认为不是这样,你就错了。来看个简单的例子吧。你可能写出下面的代码:
- def simple_app(environ, start_response):
- status = '304 Not Modified'
- headers = [('Content-Length', '5')]
- start_response(status, headers)
- return [b'hello']
理论上服务器会返回一个写有“hello”的页面(在wsgiref下测试),但是实际上:
| The 304 response MUST NOT contain a message-body, and thus is always terminated by the first empty line after the header fields |
(304响应必须不包含消息体,因此通常会被头域后的第一个空行终止) |
意思是说“hello”行会被客户端在下次请求时识别成响应的第一行。这在一些设置中会导致缓存污染和安全漏洞。有多少使用HTTP的程序员意识到了这个现象呢?还有更多莫名其妙的细节。
| HTTP不要在内部消息中使用,因为它容易使用但不简单,甚至复杂到使用了5个RFC也只描述了基本内容。即使误解最简单的内容可能会导致安全漏洞。 |
说实话,大多数微服务(microservice)使用了HTTP的子集,比如只认可200的响应码(其他的都作为失败),不使用特别的数据头或类似的,这可能不会出问题。当然这不是真正意义上的HTTP(但是经常用来负载均衡的代理则需要真正的HTTP,比如HAProxy),而且需要对HTTP特性非常熟悉的人才能构建安全的HTTP子集。
那么Zeromq怎么样
首先,它不是那种多功能的软件:
1.它很难拓展(hack on)(使用了复杂的C++ Actor模型)
2.嵌入进一些程序的效果欠佳(也就是说它没有使用好fork)
3.对故障切换(failover)和服务发现(service discovery)整合欠佳
4.对非幂等(non-idempotent)请求和有状态路由(stateful routing)操控欠佳
Nanomsg在(1)表现相对要好但远未达到完美。而在当前的设计中(2)还不能解决。(3)nanoconfig库为nanomsg解决,但却比nanomsg本身受到了更少的关注。(4)在nanomsg中可能最终解决但现在还没有。
第二个大问题是工程师们还不太适应它的思考方式,例如对同样的连接,redis协议使用发布-订阅(pub-sub)和请求-响应(req-rep),mongo使用push-pull和请求-响应(req-rep),而zeromq不允许。nonomsq特别想修正工程师们头脑中的这种想法,但这条路还很长。
别误解我,zeromq很好。nanomsq从这个失误中学到了很多,当它可用于生产环境时,它将是我用于服务间消息传递的第一选择。
#p#
但是微服务怎么了?
好吧,最简单的原因是,仅仅使用zeromq你甚至不能构建一个很小的服务。但是如果你的DB支持HTTP,你就可以使用HTTP在客户端和服务端两端构建服务。听起来很简单(但是记住HTTP很复杂)。
另外一个问题是I/O模型。当你的代码是单线程的,你就不能在不使用连接的情况下,依然保持连接心跳。即使你使用异步循环,它也可能因做其他运算而停顿很久。
有时你想给连接发请求,但是连接实际上已经关闭了。有种广泛使用的方法,读取连接数据,检出是否可用,因为通常发送请求后很难恢复:
- if s.read() == b'':
- self.reconnect()
- s.write(request)
- response = s.read()
这意味着连接仅当你发送请求时才开始建立,而不是当zeromq或nanomsg中那样只要准备好了。
而且这样也不好做服务发现,现在你有三种简单的选择:
1.每次请求前检查服务名字(如解析DNS)
2.下次连接请求时解析服务名字
3.永不更新服务(即,直到进程重启)
大部分用户选择(3)。有时(2)可以直接用(work out of the box, 开箱即可用),但是它只有机器不可达后故障切换时才会发生。(1)相当低效,几乎不可用。
I/O内核设计
(I/O内核线程与Python线程使用RPC交互)
所以,我建议重新设计所有IO子系统,即,用C(或其他无GIL的语言)写个库来处理IO,这样IO与程序主线程无关了。它应该与python主线程使用类似消息(messaging)的机制来通信。但是,不能发送Python对象,也不要在I/O线程内持有GIL。
I/O内核要支持多种协议,每个协议应该:(a)处理握手,(b)把流切分成消息,这样完整的消息才会被转发给主线程。如果可以设计连接细节,比如自动故障切换(automatic failover)的主从关系(master/slave relations),就更好了。
I/O线程应该可以解析名字,处理连接请求,能够订阅DNS名字变化,以及其他的一些高级特性。
注意,这些不仅仅对python有用,也适用于其他有GIL的脚本语言。事实上,对无GIL的语言,也能很好地工作,但可能没那个必要。
先前的做法
这个思路部分存在于很多产品中:
1.上文提到的zeromq和nanomsg使用不同的线程来处理I/O
2.Kazoo(python版的zookeeper)使用单独的(python式的)线程处理重连、ping连接
3.Twisted把阻塞计算转移到线程池(尽管我们需要相反的东西,这已经算是工作量解除了)
也许还有更多的例子,我仍然没有看到用单独线程来创建统一的I/O内核的尝试。如果你知道,告诉我。
这种模式和最近出现的Ambassador模式很像。Ambassador是个进程,存在于每台机器,进行服务发现,但是通过自身代理所有连接,即,所有服务都连接到localhost上Ambassador监听的端口,然后Ambassador把连接转发到真正的服务上去。类似的,I/O内核也应该代替主线程进行服务发现、与服务进行通信(协议仍然与Ambassador使用的那个有很大不同)。
意义所在
| 难道是为了性能上能提升几毫秒? |
对。事实上,当使用多个服务来处理单个前端请求时,毫秒级的延迟累积地相当快。而且,这种技术可以在CPU使用率接近100%时,能挽救非线性增长的延迟。
| 还是为了保持持久连接?如果你足够小心地经常放弃CPU,它们在传统的异步I/O上也工作得很好。 |
对。如果你在用异步I/O,那你已经非常出色了,因为很多人根本没有看到这种必要。但是服务发现需要多少异步库才算合理?(我的回答是:一个都不需要)
| 但用异步I/O也能进行服务发现。 |
当然。但是没人这样做。我认为应该趁机也解决这个问题。
下面是我设想的I/O内核应该做的任务:
检测和统计
对CPU密集型的任务来说,定期发送统计会比较困难。这个需要被修复。主线程应该递增在某个内存区域的计数器,而完全与I/O线程无关。
而且我们获取请求-响应计时器的精确时间戳。通常它们对python主循环的工作量评估严重不准。
在正确的服务发现帮助下,我们甚至可以在真正的用户试图在此worker上执行请求前,知道哪些必要的服务不可用。
调试
假设你可以让Python在任何时间获取状态。首先,我们总会有一批在处理中的请求。而且,我们可以像统计一样,贴上一些标记点。最后,我们可以使用类似错误处理器(faulthandler)所用的一种方法来找出主线程的栈。
关键在于,有个线程可以回应调试请求,甚至是当主线程在做CPU密集型的事情,或者因为某些原因挂起时。
管道
请求应该尽可能通过管道传输,即,不管哪个前端请求需要数据库请求,我们通过一个数据库连接发送全部。
这样,db连接数就可以很少,而且允许我们统计哪份副本较慢。
名字发现
我们不仅要解析DNS名字(不管我们选择的是什么名字解析方案),还要当名字变化时获取更新,比如zookeeper中的设置watch。
这个过程必须对应用透明,并且在应用开始请求前,连接已经存在。
统一
既然I/O内核就位,各个python的I/O框架只需要支持内核支持的协议。所有的新协议应该在内核里完成。这促使框架在方便上和效率上竞争,而不是协议的支持上。
节流(Throttling)
即使在Java和Go这些可以自由使用线程的语言里,也需要控制客户端的连接数。该设计,不管到底哪个库才是网络请求的真正执行者,允许控制应用中单个位置处的请求数目。
设计随想
下面是关于设计I/O内核的一些随想(没有顺序),有些可能在最终设计时会被去掉。
1.I/O内核应该是单线程的。因为不太可能用Python代码重载用C实现的I/O线程。相比于nanomsg或者zeromq,设计选择更加简单。
2.所有I/O应该在使用最小互锁(minimal interlocking)的I/O线程内完成。因为唤醒其他线程比执行python字节码的开销要小(这样设计也更简单)。
3.相较于持有GIL(全局解释锁,global interpreter lock),从其他python对象复制数据代价更小。但是,如果可行,应该直接分配非python的缓冲区,并直接将数据串行化进去。
4.所有支持的协议至少应该可以用C切分成帧。这样不完整的包不会到达python代码,其他解析应该在主线程内用python对象直接完成。
5.服务发现(service discovery)应该可插拔(pluggable)。最可能的选项应该最先被实现(比如DNS名称查询)。
6.服务发现应该可以被简单地集成到任何协议。事实上,对协议的实现者来说,使用服务发现比忽略它更简单。
结束
当然建立这样的工具不是一个周末就可以完成的事情。这是一份艰苦的工作,而且是无限长的旅程。
直到现在也适合重新思考为什么我们使用Python操控网络。最近的工具比如稳定的libuv和Rust语言可以极大的简化建立I/O内核。当然可以明智的使用go-python来原型化(prototype)代码,但这容易做但是不是长久之计。
论及的方案,使用起来很简洁。期望在未来我们能使用python建立高效,高性能的服务,尤其是在动态网络配置方面,从而在性能差异明显的问题上不需要使用其他语言重写所有内容。
原文链接http://www.oschina.net/translate/the-future-of-asynchronous-io-in-python


















