













Hadoop的RPC的通信与其他系统的RPC通信不太一样,作者针对Hadoop的使用特点,专门的设计了一套RPC框架,这套框架个人感觉还是 有点小复杂的。所以我打算分成Client客户端和Server服务端2个模块做分析。如果你对RPC的整套流程已经非常了解的前提下,对于Hadoop 的RPC,你也一定可以非常迅速的了解的。OK,下面切入正题。
Hadoop的RPC的相关代码都在org.apache.hadoop.ipc的包下,首先RPC的通信必须遵守许多的协议,其中最最基本的协议即使如下:
- /**
- * Superclass of all protocols that use Hadoop RPC.
- * Subclasses of this interface are also supposed to have
- * a static final long versionID field.
- * Hadoop RPC所有协议的基类,返回协议版本号
- */
- public interface VersionedProtocol {
- /**
- * Return protocol version corresponding to protocol interface.
- * @param protocol The classname of the protocol interface
- * @param clientVersion The version of the protocol that the client speaks
- * @return the version that the server will speak
- */
- public long getProtocolVersion(String protocol,
- long clientVersion) throws IOException;
- }
他是所有协议的基类,他的下面还有一堆的子类,分别对应于不同情况之间的通信,下面是一张父子类图:
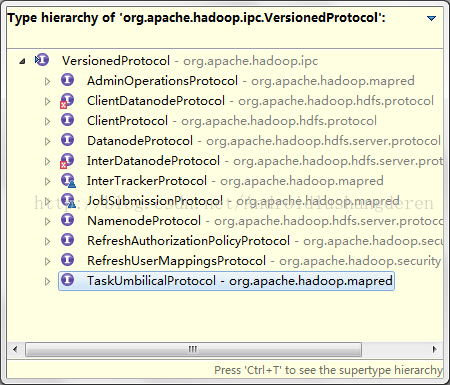
顾名思义,只有客户端和服务端遵循相同的版本号,才能进行通信。
RPC客户端的所有相关操作都被封装在了一个叫Client.java的文件中:
- /** A client for an IPC service. IPC calls take a single {@link Writable} as a
- * parameter, and return a {@link Writable} as their value. A service runs on
- * a port and is defined by a parameter class and a value class.
- * RPC客户端类
- * @see Server
- */
- public class Client {
- public static final Log LOG =
- LogFactory.getLog(Client.class);
- //客户端到服务端的连接
- private Hashtable<ConnectionId, Connection> connections =
- new Hashtable<ConnectionId, Connection>();
- //回调值类
- private Class<? extends Writable> valueClass; // class of call values
- //call回调id的计数器
- private int counter; // counter for call ids
- //原子变量判断客户端是否还在运行
- private AtomicBoolean running = new AtomicBoolean(true); // if client runs
- final private Configuration conf;
- //socket工厂,用来创建socket
- private SocketFactory socketFactory; // how to create sockets
- private int refCount = 1;
- ......
从代码中明显的看到,这里存在着一个类似于connections连接池的东西,其实这暗示着连接是可以被复用的,在hashtable中,与每个Connecttion连接的对应的是一个ConnectionId,显然这里不是一个Long类似的数值:
- /**
- * This class holds the address and the user ticket. The client connections
- * to servers are uniquely identified by <remoteAddress, protocol, ticket>
- * 连接的唯一标识,主要通过<远程地址,协议类型,用户组信息>
- */
- static class ConnectionId {
- //远程的socket地址
- InetSocketAddress address;
- //用户组信息
- UserGroupInformation ticket;
- //协议类型
- Class<?> protocol;
- private static final int PRIME = 16777619;
- private int rpcTimeout;
- private String serverPrincipal;
- private int maxIdleTime; //connections will be culled if it was idle for
- //maxIdleTime msecs
- private int maxRetries; //the max. no. of retries for socket connections
- private boolean tcpNoDelay; // if T then disable Nagle's Algorithm
- private int pingInterval; // how often sends ping to the server in msecs
- ....
这里用了3个属性组成唯一的标识属性,为了保证可以进行ID的复用,所以作者对ConnectionId的equal比较方法和hashCode 进行了重写:
- /**
- * 作者重写了equal比较方法,只要成员变量都想等也就想到了
- */
- @Override
- public boolean equals(Object obj) {
- if (obj == this) {
- return true;
- }
- if (obj instanceof ConnectionId) {
- ConnectionId that = (ConnectionId) obj;
- return isEqual(this.address, that.address)
- && this.maxIdleTime == that.maxIdleTime
- && this.maxRetries == that.maxRetries
- && this.pingInterval == that.pingInterval
- && isEqual(this.protocol, that.protocol)
- && this.rpcTimeout == that.rpcTimeout
- && isEqual(this.serverPrincipal, that.serverPrincipal)
- && this.tcpNoDelay == that.tcpNoDelay
- && isEqual(this.ticket, that.ticket);
- }
- return false;
- }
- /**
- * 重写了hashCode的生成规则,保证不同的对象产生不同的hashCode值
- */
- @Override
- public int hashCode() {
- int result = 1;
- result = PRIME * result + ((address == null) ? 0 : address.hashCode());
- result = PRIME * result + maxIdleTime;
- result = PRIME * result + maxRetries;
- result = PRIME * result + pingInterval;
- result = PRIME * result + ((protocol == null) ? 0 : protocol.hashCode());
- result = PRIME * rpcTimeout;
- result = PRIME * result
- + ((serverPrincipal == null) ? 0 : serverPrincipal.hashCode());
- result = PRIME * result + (tcpNoDelay ? 1231 : 1237);
- result = PRIME * result + ((ticket == null) ? 0 : ticket.hashCode());
- return result;
- }
这样就能保证对应同类型的连接就能够完全复用了,而不是仅仅凭借引用的关系判断对象是否相等,这里就是一个不错的设计了。
与连接Id对应的就是Connection了,它里面维护是一下的一些变量;
- /** Thread that reads responses and notifies callers. Each connection owns a
- * socket connected to a remote address. Calls are multiplexed through this
- * socket: responses may be delivered out of order. */
- private class Connection extends Thread {
- //所连接的服务器地址
- private InetSocketAddress server; // server ip:port
- //服务端的krb5的名字,与安全方面相关
- private String serverPrincipal; // server's krb5 principal name
- //连接头部,内部包含了,所用的协议,客户端用户组信息以及验证的而方法
- private ConnectionHeader header; // connection header
- //远程连接ID
- private final ConnectionId remoteId; // connection id
- //连接验证方法
- private AuthMethod authMethod; // authentication method
- //下面3个变量都是安全方面的
- private boolean useSasl;
- private Token<? extends TokenIdentifier> token;
- private SaslRpcClient saslRpcClient;
- //下面是一组socket通信方面的变量
- private Socket socket = null; // connected socket
- private DataInputStream in;
- private DataOutputStream out;
- private int rpcTimeout;
- private int maxIdleTime; //connections will be culled if it was idle for
- //maxIdleTime msecs
- private int maxRetries; //the max. no. of retries for socket connections
- //tcpNoDelay可设置是否阻塞模式
- private boolean tcpNoDelay; // if T then disable Nagle's Algorithm
- private int pingInterval; // how often sends ping to the server in msecs
- // currently active calls 当前活跃的回调,一个连接 可能会有很多个call回调
- private Hashtable<Integer, Call> calls = new Hashtable<Integer, Call>();
- //最后一次IO活动通信的时间
- private AtomicLong lastActivity = new AtomicLong();// last I/O activity time
- //连接关闭标记
- private AtomicBoolean shouldCloseConnection = new AtomicBoolean(); // indicate if the connection is closed
- private IOException closeException; // close reason
- .....
里面维护了大量的和连接通信相关的变量,在这里有一个很有意思的东西connectionHeader,连接头部,里面的数据时为了在通信最开始的时候被使用:
- class ConnectionHeader implements Writable {
- public static final Log LOG = LogFactory.getLog(ConnectionHeader.class);
- //客户端和服务端通信的协议名称
- private String protocol;
- //客户端的用户组信息
- private UserGroupInformation ugi = null;
- //验证的方式,关系到写入数据的时的格式
- private AuthMethod authMethod;
- .....
起到标识验证的作用。一个Client类的基本结构我们基本可以描绘出来了,下面是完整的类关系图:
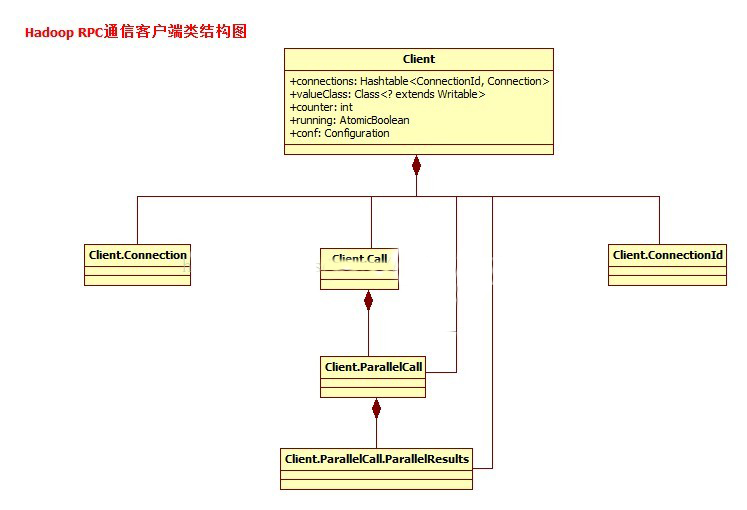
在上面这幅图中,你肯定会发现我少了一个很关键的类了,就是Call回调类。Call回调在很多异步通信中是经常出现的。因为在通信过程中,当一个对象通 过网络发送请求给另外一个对象的时候,如果采用同步的方式,会一直阻塞在那里,会带来非常不好的效率和体验的,所以很多时候,我们采用的是一种叫回调接口 的方式。在这期间,用户可以继续做自己的事情。所以同样的Call这个概念当然也是适用在Hadoop RPC中。在Hadoop的RPC的核心调 用原理, 简单的说,就是我把parame参数序列化到一个对象中,通过参数的形式把对象传入,进行RPC通信,最后服务端把处理好的结果值放入call对象,在返 回给客户端,也就是说客户端和服务端都是通过Call对象进行操作,Call里面存着,请求的参数,和处理后的结构值2个变量。通过Call对象的封装, 客户单实现了完美的无须知道细节的调用。下面是Call类的类按时:
- /** A call waiting for a value. */
- //客户端的一个回调
- private class Call {
- /回调ID
- int id; // call id
- //被序列化的参数
- Writable param; // parameter
- //返回值
- Writable value; // value, null if error
- //出错时返回的异常
- IOException error; // exception, null if value
- //回调是否已经被完成
- boolean done; // true when call is done
- ....
看到这个Call回调类,也许你慢慢的会明白Hadoop RPC的一个基本原型了,这些Call当然是存在于某个连接中的,一个连接可能会发生多个回调,所以在Connection中维护了calls列表:
- private class Connection extends Thread {
- ....
- // currently active calls 当前活跃的回调,一个连接 可能会有很多个call回调
- private Hashtable<Integer, Call> calls = new Hashtable<Integer, Call>();
作者在设计Call类的时候,比较聪明的考虑一种并发情况下的Call调用,所以为此设计了下面这个Call的子类,就是专门用于短时间内的瞬间Call调用:
- /** Call implementation used for parallel calls. */
- /** 继承自Call回调类,可以并行的使用,通过加了index下标做Call的区分 */
- private class ParallelCall extends Call {
- /每个ParallelCall并行的回调就会有对应的结果类
- private ParallelResults results;
- //index作为Call的区分
- private int index;
- ....
如果要查找值,就通过里面的ParallelCall查找,原理是根据index索引:
- /** Result collector for parallel calls. */
- private static class ParallelResults {
- //并行结果类中拥有一组返回值,需要ParallelCall的index索引匹配
- private Writable[] values;
- //结果值的数量
- private int size;
- //values中已知的值的个数
- private int count;
- .....
- /** Collect a result. */
- public synchronized void callComplete(ParallelCall call) {
- //将call中的值赋给result中
- values[call.index] = call.value; // store the value
- count++; // count it
- //如果计数的值等到最终大小,通知caller
- if (count == size) // if all values are in
- notify(); // then notify waiting caller
- }
- }
因为Call结构集是这些并发Call共有的,所以用的是static变量,都存在在了values数组中了,只有所有的并发Call都把值取出来了,才 算回调成功,这个是个非常细小的辅助设计,这个在有些书籍上并没有多少提及。下面我们看看一般Call回调的流程,正如刚刚说的,最终客户端看到的形式就 是,传入参数,获得结果,忽略内部一切逻辑,这是怎么做到的呢,答案在下面:
在执行之前,你会先得到ConnectionId:
- public Writable call(Writable param, InetSocketAddress addr,
- Class<?> protocol, UserGroupInformation ticket,
- int rpcTimeout)
- throws InterruptedException, IOException {
- ConnectionId remoteId = ConnectionId.getConnectionId(addr, protocol,
- ticket, rpcTimeout, conf);
- return call(param, remoteId);
- }
接着才是主流程:
- public Writable call(Writable param, ConnectionId remoteId)
- throws InterruptedException, IOException {
- //根据参数构造一个Call回调
- Call call = new Call(param);
- //根据远程ID获取连接
- Connection connection = getConnection(remoteId, call);
- //发送参数
- connection.sendParam(call); // send the parameter
- boolean interrupted = false;
- synchronized (call) {
- //如果call.done为false,就是Call还没完成
- while (!call.done) {
- try {
- //等待远端程序的执行完毕
- call.wait(); // wait for the result
- } catch (InterruptedException ie) {
- // save the fact that we were interrupted
- interrupted = true;
- }
- }
- //如果是异常中断,则终止当前线程
- if (interrupted) {
- // set the interrupt flag now that we are done waiting
- Thread.currentThread().interrupt();
- }
- //如果call回到出错,则返回call出错信息
- if (call.error != null) {
- if (call.error instanceof RemoteException) {
- call.error.fillInStackTrace();
- throw call.error;
- } else { // local exception
- // use the connection because it will reflect an ip change, unlike
- // the remoteId
- throw wrapException(connection.getRemoteAddress(), call.error);
- }
- } else {
- //如果是正常情况下,返回回调处理后的值
- return call.value;
- }
- }
- }
在这上面的操作步骤中,重点关注2个函数,获取连接操作,看看人家是如何保证连接的复用性的:
- private Connection getConnection(ConnectionId remoteId,
- Call call)
- throws IOException, InterruptedException {
- .....
- /* we could avoid this allocation for each RPC by having a
- * connectionsId object and with set() method. We need to manage the
- * refs for keys in HashMap properly. For now its ok.
- */
- do {
- synchronized (connections) {
- //从connection连接池中获取连接,可以保证相同的连接ID可以复用
- connection = connections.get(remoteId);
- if (connection == null) {
- connection = new Connection(remoteId);
- connections.put(remoteId, connection);
- }
- }
- } while (!connection.addCall(call));
有点单例模式的味道哦,还有一个方法叫sendParam发送参数方法:
- public void sendParam(Call call) {
- if (shouldCloseConnection.get()) {
- return;
- }
- DataOutputBuffer d=null;
- try {
- synchronized (this.out) {
- if (LOG.isDebugEnabled())
- LOG.debug(getName() + " sending #" + call.id);
- //for serializing the
- //data to be written
- //将call回调中的参数写入到输出流中,传向服务端
- d = new DataOutputBuffer();
- d.writeInt(call.id);
- call.param.write(d);
- byte[] data = d.getData();
- int dataLength = d.getLength();
- out.writeInt(dataLength); //first put the data length
- out.write(data, 0, dataLength);//write the data
- out.flush();
- }
- ....
代码只发送了Call的id,和请求参数,并没有把所有的Call的内容都扔出去了,一定是为了减少数据量的传输,这里还把数据的长度写入了,这是为了方 便服务端准确的读取到不定长的数据。这服务端中间的处理操作不是今天讨论的重点。Call的执行过程就是这样。那么Call是如何被调用的呢,这又要重新 回到了Client客户端上去了,Client有一个run()函数,所有的操作都是始于此的;
- public void run() {
- if (LOG.isDebugEnabled())
- LOG.debug(getName() + ": starting, having connections "
- + connections.size());
- //等待工作,等待请求调用
- while (waitForWork()) {//wait here for work - read or close connection
- //调用完请求,则立即获取回复
- receiveResponse();
- }
- close();
- if (LOG.isDebugEnabled())
- LOG.debug(getName() + ": stopped, remaining connections "
- + connections.size());
- }
操作很简单,程序一直跑着,有请求,处理请求,获取请求,没有请求,就死等。
- private synchronized boolean waitForWork() {
- if (calls.isEmpty() && !shouldCloseConnection.get() && running.get()) {
- long timeout = maxIdleTime-
- (System.currentTimeMillis()-lastActivity.get());
- if (timeout>0) {
- try {
- wait(timeout);
- } catch (InterruptedException e) {}
- }
- }
- ....
获取回复的操作如下:
- /* Receive a response.
- * Because only one receiver, so no synchronization on in.
- * 获取回复值
- */
- private void receiveResponse() {
- if (shouldCloseConnection.get()) {
- return;
- }
- //更新最近一次的call活动时间
- touch();
- try {
- int id = in.readInt(); // try to read an id
- if (LOG.isDebugEnabled())
- LOG.debug(getName() + " got value #" + id);
- //从获取call中取得相应的call
- Call call = calls.get(id);
- //判断该结果状态
- int state = in.readInt(); // read call status
- if (state == Status.SUCCESS.state) {
- Writable value = ReflectionUtils.newInstance(valueClass, conf);
- value.readFields(in); // read value
- call.setValue(value);
- calls.remove(id);
- } else if (state == Status.ERROR.state) {
- call.setException(new RemoteException(WritableUtils.readString(in),
- WritableUtils.readString(in)));
- calls.remove(id);
- } else if (state == Status.FATAL.state) {
- // Close the connection
- markClosed(new RemoteException(WritableUtils.readString(in),
- WritableUtils.readString(in)));
- }
- .....
- } catch (IOException e) {
- markClosed(e);
- }
- }
从之前维护的Call列表中取出,做判断。Client本身的执行流程比较的简单:

Hadoop RPC客户端的通信模块的部分大致就是我上面的这个流程,中间其实还忽略了很多的细节,大家学习的时候,针对源码会有助于更好的理解,Hadoop RPC的服务端的实现更加复杂,所以建议采用分模块的学习或许会更好一点。
本文出自:http://blog.csdn.net/Androidlushangderen/article/details/41751133










