













一、简介
Larbin是一个用C++开发的开源网络爬虫,有一定的定制选项和较高的网页抓取速度。
Larbin爬虫结构图及主要模块对应关系如下图所示:
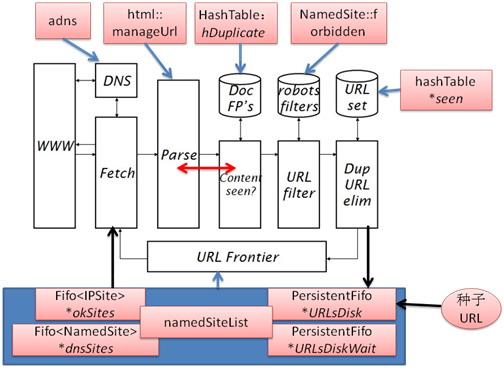
Larbin的运行过程可以描述如下:种子URL文件最初初始化*URLsDisk,读取到namedSiteList中,通过adns库调用,逐渐往Fifo<NamedSite> *dnsSites和Fifo<IPSite>*okSites内装入链接,而Fetch模块直接从Fifo<IPSite> *okSites中获得用于抓取的URL,为抓取到的网页建立hash表,以防止网页的重复抓取。然后通过html类的方法从下载到的网页中析取出新的URL,新加入前端队列的URL要求符合robots filter,并通过hash表对URL去重。一次抓取结束后进行相关的读写操作,然后通过poll函数选择适合的套接字接口,开始新的抓取。这样抓取就可以一直循环下去,直到用户终止或者发生中断。
更多关于Larbin项目的细节(包括源码)可以参看这里。
二、安装
这里以在CentOS 6.2下源码安装larbin-2.6.3.tar.gz为例说明之。
解压到指定目录后,如果直接./configure,一般会出现缺少依赖makedepend的错误,如下安装改依赖即可:
#yum install makedepend
#./configure
- 1.
- 2.
./configure成功后,如果直接make同样会出现错误,主要如下:
parse.c:113: error: conflicting types for ‘adns__parse_domain’
internal.h:569: note: previous declaration of ‘adns__parse_domain’ was here
- 1.
- 2.
根据提示直接去adns目录找到internal.h注释掉该函数即可。
再次make,依然出现错误,这次主要是因为代码用老式C代码编写,具体表现如下:
input.cc:6:22: error: iostream.h: No such file or directory
- 1.
采用如下命令替换 iostream.h为 iostream:
#sed -i -e 's/iostream.h/iostream/g' `grep -rl iostream.h *`
- 1.
注意上面包含grep的不是单引号而是Esc键下面那个符号`。
再次make,出现大量错误,原因同上,表现如下:
hashTable.cc:32: error: ‘cerr’ was not declared in this scope
hashTable.cc:41: error: ‘cerr’ was not declared in this scope
hashTable.cc:42: error: ‘endl’ was not declared in this scop
- 1.
- 2.
- 3.
执行如下命令将cerr和endl替换为std::cerr和std::endl:
#sed -i -e 's/cerr/std::cerr/g' `grep -rl cerr *`
#sed -i -e 's/endl/std::endl/g' `grep -rl endl *`
- 1.
- 2.
再次make就不会有问题了,编译完后在当前目录下会产生larbin可执行文件。
#./larbin
larbin_2.6.3 is starting its search
- 1.
- 2.
看到上面屏幕输出说明成功启动larbin了。
三、配置
上面方式启动larbin会使用默认配置文件larbin.conf,当然也可以如下来指定配置文件:
#./larbin -c conf_file
- 1.
larbin的配置是通过options.h和larbin.conf结合来完成的,前者修改后需要重新编译,后者修改后只需要重启即可。
在options.h中以下参数最好打开:
#define SIMPLE_SAVE //简单保存抓取页面,存在save/dxxxxx/fyyyyy文件中,每个目录下2000个文件
#define FOLLOW_LINKS //继续抓取子链接
#define CGILEVEL 1 //是否获得CGI
#define DEPTHBYSITE //进入新的URL时是否初始化深度
#define RELOAD //设置此项时可以从上次终止处继续爬取,使用-scratch 选项从上次结束处重启
#define CRASH //用于报告严重的bugs用,以gmake debug模式编译时使用
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
配置完别忘了make。
在larbin.conf中以下参数最好打开:
httpPort 8081 //用于查看爬行结果的web服务端口
inputPort 1976 //用于设置爬行url的telnet服务端口
pagesConnexions 100 //并行抓取网页的连接数
dnsConnexions 5 //并行DNS解析的数量
depthInSite 5 //对一个站点的爬取深度
waitDuration 60 //访问同一服务器的时间间隔,不可低于30s,建议60s
startUrl http://slashdot.org/ //起始抓取页面
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
关于配置的详细可以参见这里。
配置好就可以启动服务开始抓取了。
关于起始抓取url除了可以设置外,还可以通过telnet localhost 1976来设置,在终端提示符下输入:
priority:1 depth:3 test:0
http://www.baidu.com
- 1.
- 2.
这里把优先级设为了1,保证你输入的URL比一般的URL优先被抓取,如果输入了很多URL,把优先级设为0,防止run out of memory。
depth指定抓取链接的深度,一般不要超过5。
test设为0表示如果一面网页之前已经抓取过了,并且现在又要抓取,那就抓取,test设为1可以防止重复的抓取。
这里设置的效果同larbin.conf中的startUrl。
四、使用
运行:./larbin(或“nohup ./larbin &”,可使larbin在后台运行)
中止:Ctrl+C
重启:./larbin -scratch
注意停止larbin的时候不要用Ctrl+z,那样当你再次./larbin或者./larbin -scratch的时候,会出现端口已被占用,无法重新启动。
另外,可通过http://localhost:8081来访问larbin,从页面上获取一些关于larbin运行的信息。














