这是互联网上最无聊的工作之一,一队谷歌员工日复一日盯着电脑屏幕,审查着一张张街景图片,不断的问自己:“我看到的是个地址吗?” 然后点击Yes,点击Yes,点击No。
这就是谷歌公司地图服务构建工作中极其关键的一部分。对于地图制图者来说,知道一栋建筑的准确地址实在是太有用了。但这却并没有让那些可怜的谷歌员工生活更美好,因为他们必须分清谷歌街景车捕捉到的一串数字究竟是一个手机号,还是一个涂鸦,或是一个合法的地址。
几个月之前,他们的苦恼一下子烟消云散,因为谷歌工程师们训练了公司的计算机,这些机器可以来处理这项费力不讨好的任务。过去,计算机总是搞不定这样的高级图像识别,而谷歌公司最终用他们称为“谷歌大脑”(Google Brain)的、***的人工智能系统攻克了这个难题,谷歌现在可以在一小时之内将法国街景中的地址全部转录。
“谷歌实际上不是一个搜索公司,它是一个机器学习公司。”
自从三年前谷歌公司神秘的X实验室(X Labs)诞生以来,谷歌大脑项目就在公司内部活跃起来,使得它的软件工程师团队有用武之地,可以应用最***的机器学习算法来解决不断增多的问题。而且从很多方面看,就像过去十年中谷歌的搜索算法和数据中心专长帮助其打造起取得巨大成功的广告业务一样,这一项目很可能为谷歌在未来十年进军其它领域带来领先优势。
“谷歌实际上不是一个搜索公司,它是一个机器学习公司。”图像搜索创业公司Clarifai的CEO马修·蔡勒(Matthew Zeiler)这样表示,他曾在谷歌大脑项目实习过两次。他表示,谷歌最重要的几个项目,如无人驾驶汽车、广告、谷歌地图,一直都从这类研究中获益。“实际上机器学习驱动着公司的一切。”
不仅是谷歌地图,安卓的语音识别软件及Google+图像搜索也受益于谷歌大脑。但按照项目背后主要的思想家之一杰夫·迪恩(Jeff Dean)的说法,这仅仅是个开始。他认为谷歌大脑项目能帮助公司的搜索算法并提升谷歌翻译的性能。“谷歌现在有30或40个小组在使用我们的基础设施,”迪恩表示。“有些小组用它进行生产,有些则对它进行探索,并将它和现有的系统比较,总的说来,对于很多类型的问题能都取得很好的效果。”
这一项目是向称为“深度学习”的新型人工智能转变过程中的一部分。Facebook正在做类似的工作,微软、IBM等其它公司亦是如此。但是谷歌似乎技术更先进——至少现在是这样。
人工智能即服务
2011年,谷歌大脑项目启动,这只是个内部代号,不是官方称谓,当时斯坦福大学的吴恩达教授加入了谷歌公司具有“探月”意义的Google X实验室团队,来进行深度学习的实验。一年之后,谷歌将安卓语音识别错误率令人惊叹地降低了25%。不久,谷歌开始将它所能找到的深度学习专家全部招致麾下。去年,谷歌请来了世界上***的深度学习专家之一的杰夫·辛顿(Geoff Hinton)。接着又在一月,耗资4亿美元收购了颇具神秘色彩的深度学习公司DeepMind。
利用深度学习技术,计算机科学家建立软件模型可以在一定程度上模拟人类大脑的学习模型。然后,这些模型可以用大量的新数据进行训练,不断微调,最终应用到全新的任务中去。举个例子,谷歌图像搜索建立了一个图像识别模型,它也可以帮助谷歌地图团队解决问题。为谷歌搜索引擎建立的文本分析模型也可以为Google+所用。
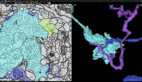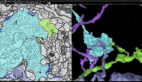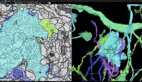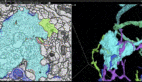
谷歌大脑可以看懂的街景图像示例。
谷歌在公司内部网上建立了几个AI模型,而迪恩和他的团队编写了后端软件,使得谷歌的服务器群能处理这些数据并将结果显示在软件界面上,让开发者可以看到他们AI代码的运行情况。迪恩说:“看起来就像是个核反应堆的控制面板。”
而有些项目,如安卓语音识别,杰夫·迪恩的团队就需要进行一些大改动以使机器学习模型能适应手头的任务。但也许,使用谷歌大脑软件的队伍中有半数都只是简单的下载源代码、微调配置文件,接着就把数据输入到谷歌大脑中。迪恩表示:“如果你想要在这一领域做前沿研究,并超越现有的技术,为新问题建立合适的模型,那么你必须要在机器学习领域接受过多年的训练。但是如果你只想应用一下这个技术,而你要处理的问题和深度模型已解决的问题有点类似,那么,人们已经用它取得了很大的成功,你也无需是个深度学习专家。”
新版MapReduce
这样的内部代码共享也对另一项谷歌领先的技术MapReduce产生了重大影响。十年前,迪恩作为团队一员编写了MapReduce,使它成为了利用谷歌数以万计服务器的可行之路,并训练它们来解决如为万维网建立索引这类单一问题。MapReduce的代码最终在内部公开,而谷歌思维敏捷的工程师们就想出了如何训练它来解决新的大数据计算问题的方法。MapReduce背后的思想最终写成了开源项目Hadoop的代码,将谷歌曾经独享的超强数据处理技术拱手献给世界。
随着谷歌宏伟的人工智能项目细节不断流出,谷歌大脑也许***也会成为开源项目。今年一月,谷歌发表了一份关于谷歌地图的论文,考虑到谷歌有分享其研究成果的记录,很可能有更多的论文将会发表。
考虑到深度学习算法要解决的问题范围非常广,谷歌与迪恩以及他团队的代码还有大量工作要做。他们发现,使用的数据越多,这些模型就会变得更精确。那也许是谷歌下一个宏大目标:建立十亿级数据点的人工智能模型,而不是***的。就像迪恩所说的:“我们正在尝试将可扩展性推进到下一个级别,可以训练准确的、真真正正的大数据模型。”
原文链接: ROBERT MCMILLAN 翻译: 伯乐在线 - toolate