













Coolhash当前性能指标:读写吞吐量超过百万,千万级别查询1秒完成,连续48小时打满CPU强压力运行稳定。redis官方公布读写性能在10万tps,leveldb官方公布写性能在40万tps,读在6万tps,redis和leveldb都是倾向k/v高速读写,但不具备高效检索功能,没有join关联设计。coolhash可以拿去pk世界上任何的数据库引擎产品。
下面以redis为例进行了详细测试和技术分析,leveldb的性能可详见其官方资料,在写性能上优于redis,但是读性能和多数据结构支持上不如redis,leveldb读代价高是因为需要在内存以及各级数据文件逐项查找并要优先考虑数据最新状态,另外redis还提供server和集群功能,leveldb不提供,redis是内存方式+内存快照持久化,而leveldb是Memtable+硬盘持久化,leveldb持久化不受内存限制,也做到了接近缓存的性能,未来k/v数据库的趋势最好能直接当作缓存使用,并能支持高效检索功能。
按照redis的常用方式,我们在一台服务器上进行redis“单server”和“多server”的测试:

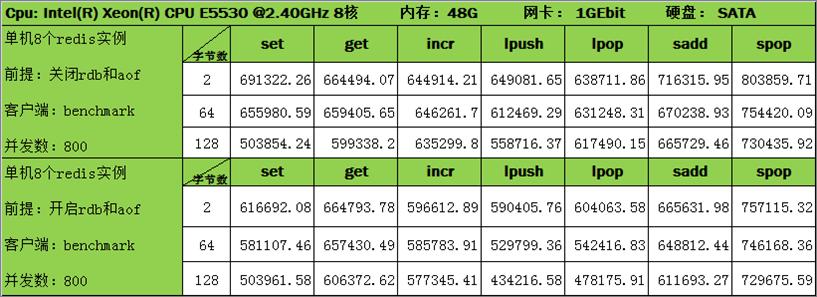
从上面两个图,我们可以看到:
-
redis是一个单进程单线程的实现,单server的读写TPS大概在8—12万(跟redis官网公布的数据一致),为了充分利用能够资源,redis官方建议一台机器部署多个redis server。
-
上面第二个图的TPS超过了8-12万的限制,这实际上是在一台服务器上部署了多个redis server,并将该服务器总的吞吐量算到一个redis server上得到的。但是写的时候是客户端各自写不同的redis server,多个redis server之间的数据是彼此独立的,在不同的内存空间中,如果分开计算每个redis server的写入总量除以时间,TPS还是在8-12万左右。
我们再到24核/256g/SATA硬盘的pc server上测试一下redis的benchmark,200个客户端共写入2000万数据,发现性能变化不大,还是在10万左右的TPS,又测试了20个客户端写入2000万数据,12万TPS:
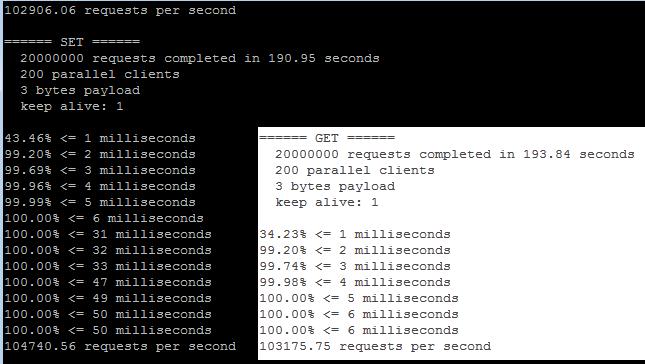
Redis很优秀,但是也有一些局限:
-
redis不是一个并行数据库,由单进程单线程实现,已经做到了单进程极限,性能很难再突破。如果要重新改写redis,代价很大,而且只有redis作者有能力做,其他外围的捐献者动不了。redis官方采取一种曲线救国方式,不改变单进程模式,采取外围做集群,部署多个server来提高CPU利用率,redis3.0的集群方案使用一种hash slot算法(不是一致哈希),用多个redis server做数据分片存储,按照crc16/16384取模方式,让客户端根据hash slot的配置寻址,扩容按照slot单位做数据迁移达到负载均衡。由于在同台服务器也存在多server实例集群,会牵扯出很多server的master-slave复制和数据迁移一致性等复杂性,也容易引起后端的IO争用,特别是在AOF模式时。
-
redis是一种内存快照方式,也就意味着它的持久化大小受内存限制,不是真正的数据库持久化存储,内存是昂贵的,为了扩大内存存储,往往需要更多的服务器搭建缓存集群,redis作者曾想增加一种diskstore的全持久化+cache方式,采用SHA1算法来建立存储结构,来改进内存快照方式的种种不足,但是涉及到对redis底层持久化方式的重构,这个计划从11年提出,截至到目前3.0版本,仍然还没有提供。
-
redis的存储方式不是按照数据库存储索引结构设计,无法做到高性能的按范围、按key/value的模糊检索,更多只能在内存中进行全局数据的遍历过滤,没有高效的查询功能,redis更适合做缓存读写,不适合当作数据库存储使用。
国内的redis使用团队更多也是在运维工具、监控管理、主备、故障恢复等等方面改进,不具备对上面redis的3点内核局限的重构能力。
我们接下来在同机环境(24核/256g/SATA硬盘)测试coolhash,实际上coolhash也可以像上面redis那样在一台服务器上部署多个server实例,但是我们这里启动一个coolhash就够了。coolhash是一个并行数据库引擎和数据库server,可以通过调整“coolhash数据工人数量、客户端并发数量、每客户端读写数量”三个指标项达到一台服务器的最佳吞吐量性能。
coolhash通过一组数据工人并行的完成任务,我们先测试一个coolhash启动多少个数据工人最合适,下面在一台服务器上运行coolhash并分别启动1-96个工人,再用另外一台服务器模拟了200个客户端并发,每个客户端写入10万数据,累计2000万数据,数据格式key=n(0<n<2000万),value=n(0<n<2000万),平均大小在几十字节左右,比上面redis的benchmark的每条数据3字节要大,客户端和服务器在同一个局域网内,通过IP访问。(注意:不要简单的在一个jvm里以多线程模拟并发,如果客户端包存在公共变量,容易引起混乱,应该启动200个独立客户端)
测试1:x个数据工人,200个客户端并发,每个客户端写入10万数据
| 数据工人 | 1个工人 | 8个工人 | 24个工人 | 32个工人 | 96个工人 |
| 耗时 | 400秒 | 40秒 | 20秒 | 23秒 | 25秒 |
| cpu最高峰 | 10% | 20% | 75% | 85% | 90% |
| TPS | 5万/秒 | 50万/秒 | 100万/秒 | 87万/秒 | 80万/秒 |
分析:可以清晰的看到并行数据库的优势明显,如果只有一个数据工人,也就是单进程模式,它的TPS是很难超出10万的,如果是8个数据工人并行作业,性能一下子就能从400秒减少到40秒,提升10倍,但也不是数据工人越多性能越好,我们看到24-32个工人是个顶峰,如果再增加工人数虽然能提升cpu使用率,但是调度开销大,后端硬盘io等跟不上,导致性能反而有所下降。
根据上面的结论,我们配置coolhash启动24个数据工人最合适,接下来再进一步调整“客户端并发数”和“每个客户端写入数量”,来达到一台服务器的最佳性能。
测试2:24个数据工人,x个客户端并发,每个客户端写入10万数据
| 客户端数 | 1并发 | 10并发 | 20并发 | 50并发 | 100并发 | 200并发 |
| 写入总量 | 10万 | 100万 | 200万 | 500万 | 1000万 | 2000万 |
| 耗时 | 1秒 | 3秒 | 5秒 | 10秒 | 18秒 | 20秒 |
| TPS | 10万/秒 | 33万/秒 | 40万/秒 | 50万/秒 | 55万/秒 | 100万/秒 |
分析:如果每个客户端写相同数量的数据,随着并发数的提高,总体的吞吐量会高于单客户端呈线性增长趋势,但是受服务器cpu、内存、io等性能限制,不会一直增长,会倾向于一个平衡值。每台服务器并不是能承受无限大的并发数量,如果超出了承受限制,客户端会长时间等待,容易产生socket连接超时。合理的控制并发数量能提升服务器的吞吐性能,下面我们增大每个客户端的写入数量,减少总的并发数,并观察效果。
测试3:24个数据工人,20个客户端并发,每个客户端写入x万数据
| 每客户端写 | 10万/每 | 50万/每 | 100万/每 | 200万/每 | 300万/每 |
| 写入总量 | 200万 | 1000万 | 2000万 | 4000万 | 6000万 |
| 耗时 | 4秒 | 6秒 | 10秒 | 15秒 | 22秒 |
| 写TPS | 50万/秒 | 167万/秒 | 200万/秒 | 267万/秒 | 272万/秒 |
分析:可以看到同样写入2000万数据,采用20并发*100万比200并发*10万的性能提升了一倍,能达到200万以上TPS。这是因为客户端建立连接后,一次提交100万条数据的写入请求,相比每条数据连接server,能很大节省网络开销和硬盘IO开销。由此我们也能得到,并不是并发连接越多越好,而是控制一定数量的连接池性能会更好。
接下来我们再以使用相同参数,测试一下读的性能。
测试4:24个数据工人,20个客户端并发,每个客户端读出x万数据
| 每客户端读 | 10万/每 | 50万/每 | 100万/每 | 200万/每 | 300万/每 |
| 读出总量 | 200万 | 1000万 | 2000万 | 4000万 | 6000万 |
| 耗时 | 4秒 | 6秒 | 11秒 | 20秒 | 30秒 |
| 读TPS | 50万/秒 | 167万/秒 | 182万/秒 | 200万/秒 | 200万/秒 |
分析:coolhash是一个读写平衡的数据库引擎,可以看到读和写的性能相差不大,都能达到200万的TPS。
coolhash提供了高效的查询检索功能,可以支持key和value的同时模糊查询,下面按照600万—3亿不同的数据总量进行模糊查询,数据格式为key=n(0<n<3亿),value=n(0<n<3亿),模糊查询value包括“8888888”的数据:
CoolHashResult hr = chc.find("*", ValueFilter.contains(“8888888”))
#p#
测试5:24个数据工人,x个客户端模糊查询x万数据
单个客户端模糊查询:
| 数据总量 | 600万 | 2000万 | 6000万 | 1亿 | 3亿 |
| 耗时 | 0.9秒 | 1秒 | 1.7秒 | 2秒 | 6秒 |
多个客户端高并发模糊查询:
| 客户端数 | 1并发 | 10并发 | 20并发 | 50并发 | 100并发 | 200并发 |
| 600万 | 0.9秒 | 2秒 | 4秒 | 9秒 | 14秒 | 18秒 |
| 2000万 | 1秒 | 4秒 | 9秒 | 21秒 | 37秒 | 45秒 |
分析:对于千万级别的数据,客户端一次任意模糊查询的耗时都是在1秒完成,如果超过1亿需要2秒,3亿需要6秒(在没有额外构建索引情况下)。如果是100个客户端并发模糊查询,按照上面表格里100并发查询2000万数据,平均耗时37秒,每次查询耗时37/100=0.37秒,每秒查询次数100/37=2.7次,每秒查询数据范围大小100*2000万/37秒=5400万。这里测试key是“*”代表所有,如果key根据业务特点进行了分层设计,以“user.*.name”这样形式模糊查询,范围会缩小,速度会更快。
测试6:压力测试,200高并发下每客户端读取10万数据连续48小时不间断,服务端cpu、内存、带宽资源高压力运行稳定无异常。
下面归纳一下coolhash和redis的基本区别:
| redis | coolhash | |
| 实现语言 | c | java |
| 大小 | 2.3万行代码 | 小于1万行(含fourinone) |
| 运行环境 | Linux | Linux/windows |
| 数据库类型 | k/v缓存数据库 | k/v持久化数据库 |
| 实现模式 | 单进程模式,所有操作单线程完成 | 多进程模式,并行数据库,所有操作并行完成 |
| 持久化模式 | 内存快照,aof日志 | 硬盘持久化+cache |
| 存储大小 | 受内存大小限制 | 无限制,取决硬盘大小 |
| 数据类型支持 | String,Hash,List,Set,Sorted set等,List是一个双向链表实现,可用于实现消息队列。 | 基本数据类型:“String、short、int、long、double、float、Date”,高级数据类型:大部分的java集合都能支持(List、Map、Set等),以及任意可序列化的自定义java类型,底层数据类型:二进制型 |
| 存储结构 | redisDb内存结构,Key和key之间无联系,无上下层结构 | 按照数据库索引存储结构设计,CoolHash算法实现,支持key的树型层次结构 |
| 查询检索 | 没有针对范围检索设计 | Key索引+并行计算高效查询,查询性能在秒级 |
| 关联设计 | 没有针对join设计 | Key指针设计,并可连续指,支持建立1对1、1对n、n对n的复杂关联关系 |
| 读写性能 | 单server吞吐量10万tps(内存) | 单server可达到百万以上tps(硬盘) |
| 事务处理 | 支持,但没有事务隔离级别 | 支持ACID,实现TRANSACTION_SERIALIZABLE隔离级别 |
| Server支持 | 支持 | 支持 |
| 命令行支持 | 支持 | 不支持 |
| 主备支持 | 直接支持,通过redis.conf配置主备 | 不直接支持,提供fttp分布式备份api开发包支持 |
| 集群支持 | 3.0版直接支持,通过hash slot算法 | 不直接支持,提供分布式缓存集群和fttp等开发包支持 |
总结:
-
首先不能简单的以实现语言来衡量性能,认为c实现的就一定比java高效,数据库引擎的效率提升更多取决于底层算法改进和设计突破,c在底层和操作系统交互上有优势,但是取决于开发者,一个蹩脚的c工程师写出的代码只会低效和漏洞百出。
-
redis的优势在于快速的缓存读写、丰富的数据类型支持,以及完善的主备复制和集群实现,劣势在于单进程模式、内存限制、查询检索等方面。
-
coolhash是一个并行数据库引擎,在很多地方采用了大胆创新的设计,并获得了很好的性能体验,改进后的哈希算法能实现更快的读写吞吐量,key层次结构和key指针等设计能实现更高效的查询检索和join关联。由于只做数据库引擎,暂不提供主备和集群功能,但是fourinone提供了大部分分布式技术简单实现的开发API,开发者可以利用这些自己去实现。
-
随着数据库实现技术的发展,kv缓存和kv持久化存储的性能越来越接近,边界会越来越模糊,也会越来越涵盖关系数据库的功能。存储硬件技术也在发展,未来在内存+ssd混合存储上还会有更好的性能突破。
以上测试程序和运行包都来源于fourinone4.0版本,可以到以下地址下载:
-
google code svn:http://fourinone.googlecode.com/svn/trunk/
-
国内oschina code:https://git.oschina.net/fourinone/fourinone/blob/master/fourinone-4.05.06.zip
CoolHash数据库demo目录内容:
-
RunServer.java:启动服务端
-
RunClient.java:启动客户端
-
CoolHashTestRun.java:启动多个并发客户端
CoolHash作者声明:欢迎各位朋友理性验证和讨论,不欢迎不理会各种喷子言论。
这里有很多人是redis和leveldb的使用者和封装者,其中一部分人会看coolhash不爽,甚至失去理性变成喷子,对coolhash大加攻击和诋毁,希望coolhash只是玩具,希望coolhash没有场景...但是喷子们要清楚自己的位置,redis和leveldb不是你的作品,你只是站在洋人前面狐假虎威而已,核心层面的东西你甚至不具备发言权。长期以来国内工程师都是以学习和使用国外开源软件为生存技能,能理解这些人也只是混口饭吃。
很多人软件思想意识落后,“软件傻瓜化”超出了他的理解范围,看到demo简单,便误认为框架源码也肤浅,看到demo里没有synchronized,便以为框架没有同步,有人甚至怀疑源码是假的。demo简单是为了保护用户的自信心和驾驭感,用户只需要看到一个美丽的躯壳,血肉模糊的东西留给框架戴着口罩拿着手术刀去做,这实际上对设计者提出了更大的难度,所以源码要实现那么多功能,还要做到体验傻瓜化,一定是非常精密的逻辑组成,源码不可能像demo那样通俗易懂。
一些人一来就对fourinone源码指手画脚,评头论足,大部分批评只停留在“编程规范、格式、变量名、包名、调了哪些工具类”这些层面,这些人需要多花时间提升自己的技术积累、设计能力、算法能力,才能真正理解源码的各种行为,作者到过国内各种IT企业,非常清楚国内工程师的技术能力能到什么程度,国内的开源软件大部分是基于国外开源软件封装后的二次开源,真正意义上的原创很少,大部分中国IT企业处在产业链末端,没有核心技术,依靠外包劳动力,工程师的技术寿命很短,平均只有3-5年,然后周围环境会暗示他转向管理或者业务,只有这样才能得到领导认可,技术积累太短暂,技术人员没有悟性,也缺乏兴趣,过于依赖国外,是不可能在核心软件层面有真正的原创。
一些人对coolhash很质疑,认为很少人很少代码实现不了高性能,实际上早在几年前,fourinone就在一片质疑声中被要求压测,结果出乎意料在计算性能上优于hadoop,现在coolhash只是重演了创新能力而已。建议各种质疑者跟风者先放下政治偏见、利益冲突、情感排斥,耐心的动手去试试。对于技术上缺乏分辨力的人,建议你认准三点,一看上手是否容易;二看功能是否强大;三看性能是否高效,只要满足这三点就没有人可以忽悠得了你,然后你再结合源码去反思是如何做到的。
曾国藩说过“窃喜洋人之智巧中国亦能为之,彼不能傲我以其所不知矣!”
文人不相轻,技术归技术,本文对redis和leveldb的作者充满尊敬和虚心学习,Salvatore Sanfilippo(antirez) 说过代码像一首诗,Jeffrey Dean更是google map/reduce的作者,他们都表现出很高的职业素养和天赋,是这些人推动着世界软件技术的发展,也成为中国架构师内心难以跨越的丰碑。是存在差距,但是可以站着学习,而不是跪着膜拜,一味跟从只会丧失判断力和创新力,香港的年轻人曾经不相信大陆的taobao会比eBay强大,QQ会比MSN强大,直到MSN垮了仍然不相信是真的,没有信心,没有努力,梦想只会变成做梦。


















