在日前于旧金山举办的Spark 2014峰会上,Databricks公司CEO Ion Stoica通过主题演讲公布了Databricks云——这是一套以Apache Spark开源处理引擎为核心构建而成的云平台,专门负责大数据处理工作。
Spark项目在一个月之前才刚刚完成了其v1.0版本,这是一套集群计算框架、设计目的在于以Hadoop分布式文件系统(简称HDFS)为基础取代原本的Hadoop MapReduce。借助对内存内集群计算的支持能力,Spark得以在内存机制的辅助下将Hadoop MapReduce的性能表现提升达100倍,而磁盘配合时的性能提升也能达到原先的10倍。

“对于企业用户来说,将自身在大数据领域所投入的资金充分转化为实际价值仍然是一项非常困难的任务,”Stoica表示。“这类集群很难设置与管理,而且要从数据中提取出可资利用的实际价值需要配合各种不同类型的工具方案,这无疑使整项工作难上加难。我们Databricks的愿望是能够显著简化大数据处理方式,帮助用户将精力集中在数据向实际价值的转化身上。Databricks云能够将Spark的强大能力与零管理托管平台结合起来,并提供常见工作流程所必需的初始应用程序集合,这一切将有助于我们把发展愿景变成现实。”
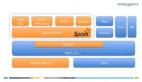
Databricks云还能够为交互式查询(通过Spark SQL)、流数据(Spark Streaming)、机器学习(MLlib)以及图形计算(GraphX)以原生方式提供支持,同时利用单一API跨越全部数据传输通道。Stoica表示,这套经过配置的全新Spark集群可谓一大转折点,用户只需为集群设定好必要的资源容量、其它工作该平台都能独力完成——包括在运行过程中对服务器进行配置、简化数据导入与缓存机制、在安全性角度对Spark进行补丁安装与更新。
该平台还包含三款内置应用程序:
Notebooks。这是一套富界面,用于执行数据发现与浏览任务。Notebooks能够以交互式方式绘制查询结果、以脚本方式执行整套工作流并实现高级协作功能。
Dashboards。Dashboards允许用户从之前创建的Notebooks当中选择任意输出结果,进而将其创建成仪表板形式并加以管理。Dashboards随后会将结果输出到单一页面中的仪表板内,同时提供WYSIWYG编辑器、从而将内容向更为广泛的受众加以提交。
Job Launcher。Job Launcher应用程序允许任何使用者运行任意Apache Spark作业并在执行过程中予以触发,这能大大简化创建数据产品的实际流程。
“我们了解到,大多数企业用户都在抱怨大数据处理并不是单一一项分析工作;真正的执行流程需要将数据存储、ETL(即提取、转换与加载)、数据浏览、仪表板与报告、高级分析以及数据产品创建等步骤结合起来,”Stoica指出。“利用当前的技术成果完成上述工作可以说相当困难。我们打造的Databricks云正是为此而生,它能够在设备之上建立起终端到终端通道,同时支持全部强化性以及功能补充性Spark应用程序。它的设计目的在于将原本被大数据处理的超高复杂性吓退的新用户们重新回到这块***价值的分析舞台上来。”Stoica指出,上述内置应用程序还仅仅是个起点。Databricks云以100%纯开源Apache Spark项目为基础开发而成,这意味着全部现有以及未来将要出现的“经过Spark认证”的应用程序都将能够运行在这套开箱即用的平台之上——其中也包括十几款Databricks于今年二月启动其应用认证计划以来获得肯定的Spark应用程序。
此外,Stoica还谈到,大家完全可以反其道行之。任何在Databricks云上开发而成的Spark应用程序也将能够运行在全部“经过认证的Spark发行版”当中,也就是说用户不会被锁定在某种特定托管平台身上。Databricks于上周正式启动了其发行版认证计划,并强调称目前已经有五家供应商通过了认证过程,它们分别是:Datastax、Hortonworks、IBM、甲骨文以及Pivotal。
“我们衷心期待着能够将Databricks云打造成一整套丰富多彩的生态系统,”Stoica表示。
Databricks云目前正与几家用户配合进行封闭beta测试,并计划于今年八月开放限定可用beta测试,Stoica解释称。他同时补充道,该平台将采用分层定价模型作为基础计费机制,根据使用量核算使用成本。初期该平台将只在Amazon Web Services(简称AWS)上与用户见面,不过Stoica强调未来有计划将其扩展到其它云供应商的基础设施当中。
原文链接: