在上篇文章中你已经看到了在你的devbox创建一个单点Hadoop 集群是多么简单。
现在我们提高门槛,在Docker上创建一个多点hadoop集群。在开始前,确保你有***的Ambari镜像:
- docker pull sequenceiq/ambari:latest
一行命令
一旦你得到了***的镜像,你就可以启动Docker容器。我们已经创建了几个shell 函数来帮你输入Docker命令,从而避免输入像docker run [options] image [command]这样冗长的命令。
有了这些功能,创建3个节点的hadoop簇,只需要下面一行代码搞定:
- curl -Lo .amb j.mp/docker-ambari && . .amb && amb-deploy-cluster
默认参数值都是可以根据需要更改的,像是blueprint,簇大小,等等 … 在shellj.mp/docker-ambari功能函数的头文件有参数列表.
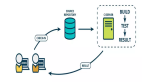
它是按照下面步骤来实现的:
-
在Docker (后台运行) 容器的守护进程上运行sambari-server start (记得还有 anambari-agent start)
-
运行sn-1 守护进程容器并用ambari-agent start连接到服务器
-
运行AmbariShell 以及其终端控制台 (监控子进程)
-
AmbariShell 会把内置的多节点blueprint发送至 /api/v1/blueprintsREST API
-
AmbariShell 依照blueprint的设置自动分配宿主信息
-
通过发送至/api/v1/clustersREST API的内容创建簇
-
自定义
如果你有自己定义好的脚本,可以放在 gist然后运行 AmbariShell. 先启动 AmbariShell:
- amb-start-cluster 2
- amb-shell
AmbariShell启动的前提:
-
Ambari REST API 将帮助你建立多个hadoop端.
AmbariShell 的 hint命令能帮助开发人员实现自动补全等功能.
自动补全包括:
-
补全命令行 (例如,没有这个帮助下 cluster命令是不可用的)
-
添加需要的参数
-
添加备选参数: --后加上<TAB>
-
添加变参,像是参数名,宿主名等等 …
总结
基本上我们开始使用Docker的时候就已经使用多端的hadoop功能了 – 笔记本上运行3到4簇面临的极限问题比 Sandbox VM少得多.
我们使用了docker的模式简化了hadoop的使用模式 – 可以在 LinkedIn找到我们关于Cloudbreak的***进展 – 开源云端的Hadoop as a Service API应用并构建在 docker上.
希望本文能帮你简化你的开发流程 – 如有什么关于docker上使用hadoop问题,欢迎沟通。
英文原文:Multi-node Hadoop cluster on Docker
译文出自:http://www.oschina.net/translate/multinode-hadoop-cluster-on-docker