辛普森悖论在数据集方面看上去广泛,而且没有被分解成有意义的片段。辛普森悖论是研究中被忽略的“混淆变量”结果。混淆变量本质上是一个与核心研究无关的变量,它随着自变量的改变而改变。
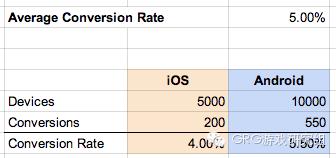
例如,一个移动应用程序的用户群,其中1万人使用Android设备,5千人使用iOS设备。用户的总体转化率是5%,iOS设备的转化率是4%,Android设备的转化率是5.5%:
假设相同的货币化(也就是Android用户和iOS用户在游戏中花的钱一样多),资源有限的产品经理可能根据这些数据会做出一些极端的决定,也许会优先考虑安卓功能的开发,甚至干脆取消iOS项目。
然而当数据按照设备再次细分,用户群的不同的情况如下:
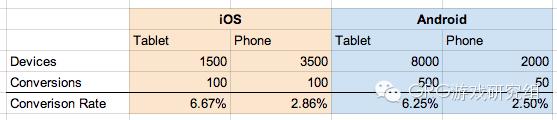
现在发现iOS平板的转换率比Android平板高一点,iOS手机的转换率同样比Android手机高。如果看到了这一点,产品经理可能会对未来的产品做一系列不同的决策。
在这种情况下,设备类型是一个混淆变量:当数据按照设备类型细分,子群体具有完全无法相比的统计特性。
iOS能在设备转化方面打败Android,但是在整体水平上却输给Android的原因是,每个平台的设备类型不同:平板的转化率比手机的转化率高,在这个用户群中,iOS平板占iOS设备的比例(30%)低于Android平板所占的比例(80%),尽管Android平板上的转化率比IOS低。 把数据混合到一起就变成一个很大的问题,去比较两组与完全不同的属性的东西 —— 就像是去比较苹果和橙子的区别一样。
混淆变量经常用于分析免费增值产品,有以下几个原因:
1. 基数大小。免费增值产品因为固有的低转化率需要大量用户基数来产生收入。这些庞大的用户通常由来自世界各地,来自不同地区,并且使用设备广泛。这种多样性的呈现致使比较后的平均值几乎没有任何意义;
2. LTV曲线。免费增值产品受益于长尾货币化曲线。为了娱乐而消费的使用者,消费的指标可能很接近,因此可以作为分界的界限。
3. 大部分用户不会消费。先前提到的免费增值产品的固有低转化率 作为一个基本的区分两类用户而存在 :付费和非付费。基于这个原因,把非付费用户群作为一个整体的任何指标都是有缺陷的,因为它把所有指标都倾斜到了绝大多数永远不会付费的用户(这就是为什么最低可行的指标模型包括ARPU和ARPPU)
避免辛普森悖论的关键——关于用户基础的结论,不反映现实的不同类型的用户与产品的交互——是明智地应用维度分析。用户细分在数据分析中是非常重要的,特别是对免费增值产品,“普通用户”不仅不存在,而且他的特征作为一个警示,避免开发人员被误导。当一个用户群以广泛多元化的特征存在时,通用数据是无用的。
当考到产品开发路线图时,用户分类是至关重要的:如果数据分析表明哪些特性由于确定非常有价值而优先开发,那么它同时也决定了应该给哪些人做推销以增长用户群。也正因此,从聚类分析得出似是而非的结论,不仅会造成开发错误功能,也会把更多错误的用户加入到用户群中。
为了避免这种情况,用于优先功能开发的基本维度(“过滤器”,或用户特性),应该在用户分类方面建立粗糙集。对于移动产品,最基础的设置一般包括:
-
位置(国家)
-
设备(平台、外形,设备型号)
-
采集源;
-
早期行为线索( 如盈利/ 参与里程碑);
-
加入日期(用于控制季节性)
-
对于一些收购渠道(如Facebook),其他人口统计数据点,如年龄,性别等可能也是重点。
用这些维度进行分析比先前引用的“iOS和Android”的例子提供了更为可靠的见解。最终分析的目标是为真正使用它的人改善产品。如果这个分析在一个错误的前提下进行,那么用户的真正问题并不会得到解决。