任何有多年客户端开发经验的开发者都应该知道复杂的文字渲染是怎么工作的。至少在2010年以前,我刚开始写libhwui的时候(这是一个基于 Android2.0的2D绘画库),我就意识到处理文字有时会比其他方面更复杂,特别是当你尝试用GPU在屏幕上进行绘制的时候。
文字与Android
Android上的文字渲染加速器硬件最初是由Renderscript团队写的,然后被很多工程师改进和优化,包括我和好友Chet Haase。在网络上,可以很容易找到很多关于怎么使用OpenGL ES渲染文字的教程。如果觉得还不够,可以看看关于游戏的文章,只看关于文字渲染部分就行。
本文说不是很新奇的知识,只是对于很多开发者来说,通过本文可以从深层次上了解如何实现一个基于GPU的文字渲染系统,文章***还介绍了一些比较容易实现的优化方法。
用OpenGL渲染文字的常用方法是计算包含所需字形的所有纹理集。这个操作通常是使用一些相当复杂的算法进行离线操作,这样可以在构造字形的时候更加高效。在创建这样一个纹理集之前,首先需要知道应用程序在运行时要使用的字体,包括字体样式、大小以及其它属性。
在Android上,提前进行字体纹理生成不是一个实用的方案。Android上的UI工具并不能知道应用系统会使用什么字体和字形,并且应用还可以在运行时载入自定义的字体,这是主要的限制。Android字体渲染还必须遵循以下条例:
- 它必须在运行时建立字体缓存;
- 它必须能够处理大量的字体;
- 它必须可以处理大量的符号;
- 它必须要尽可能减少字体上的资源消耗;
- 必须运行要快速;
- 在低端和高端机器上也能够良好运行;
- 能***与其它组件结合(驱动程序或GPU)。
字体渲染器的实现
在进入底层OpenGL字体渲染器工作原理之前,我们先从应用层使用的高级别的API开始。这些API对于理解libhwui很重要。
文字API
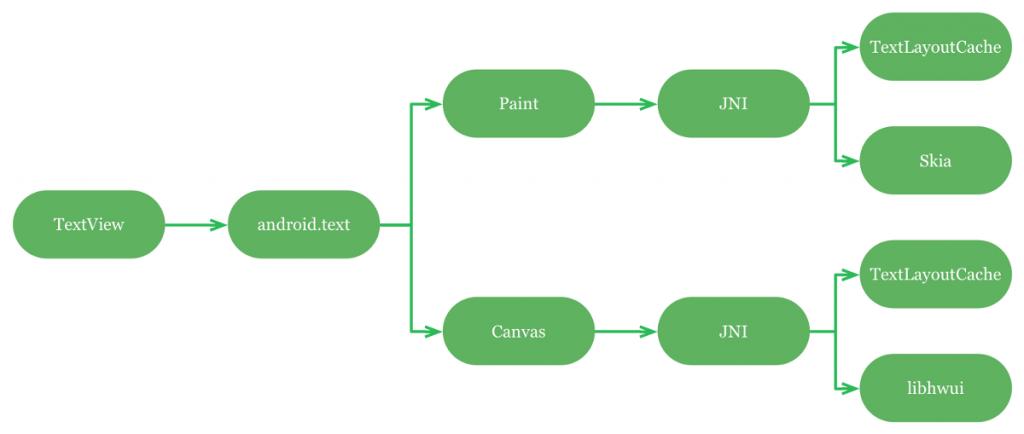
用于布局和绘制文字主要有4个API:
- android.widget.TextView:一个可以处理文字布局和渲染的视图组件。
- android.text.*:一个可以创建风格化文字和布局的类集合。
- android.graphics.Paint:用于测量文字。
- android.graphics.Canvas:用于渲染文字。
TextView和android.text的都是在Paint和Canvas上的高级API。Android3.0以后,Paint和Canvas直接被实现在Skia之上,这是一个开源的渲染库。SKia提供了一个很好的Freetype抽象实现,这是一个很热门的开源字体栅格化程序。

对于Android4.4,情况变得有些复杂。Paint和Canvas都使用了一个内部的JNI API,叫做TextLayoutCache。它可以处理复杂的文字布局(CTL)。这个API依赖Harfbuzz,一个空间开源的字形引擎。TextLayoutCache的输入是一个字体和一个Java的UTF-16的字符串,输出是一个带有x/y坐标的字形列表。
TextLayoutCache是支持非拉丁语言的要点,比如阿拉伯语言、希伯来语、泰国语等,本文不会解释TextLayoutCache和 Harfbuzz的工作原理,但本人强烈建议读者去学习学习CTL。如果在开发应用的时候需要支持非拉丁语言环境,那么就要学习它了。如果你曾经参与过 OpenGL渲染文字的文章中的讨论,就会发现这种特殊的问题是很少见的。绘制文字比简单排布字形更复杂。某些语言中,比如阿拉伯语是从右到左的,还有泰 语甚至需要把字形排布在前一个字形的上面或者下面。
也就是说,当直接或间接调用Canvas.drawText()函数的时候,OpenGL 渲染器不会收到你发送的参数,而是收到一串数字、符号标识,还有x/y 坐标集合。
点阵化和缓存
字体渲染器的每一个绘制方法都是和字体相关的。字体用于缓存个别字形符号,而字形符号又被存储在缓存结构中(缓存结构可以包含不同字体的字形符 号)。缓存结构是持有多个缓冲区的一个重要的对象,有block集合、pixel缓冲区、OpenGL结构处理器,还有点阵缓冲区(也就是网格)。
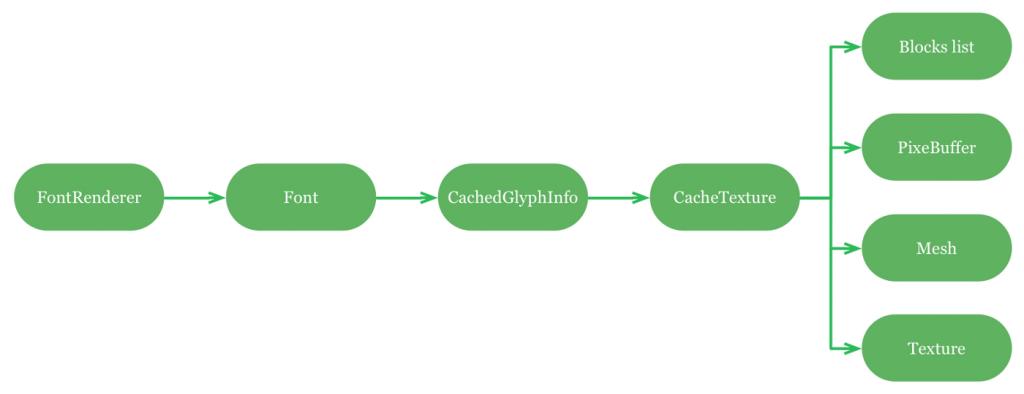
这个对象存储的数据结构比较简单:
- 在字体渲染器中字体是存储在一个LRU缓存中的;
- 字形符号分别存储在对应的map字体集合中(key就是字形文件的identifier);
- 缓存结构使用一个块链表集合来记录空间的大小;
- 像素缓冲区是一个uint8_t或者uint32_t类型的数组(作alpha值和RGBA的缓存);
- 网格其实就是一个顶点数组,带有两个属性:x/y位置和u/v坐标;
- 一个GLuint的处理器。
字体渲染器对不同类型的缓存结构提供了几种缓存纹理实例,也就是根据不同的大小区分,这个大小可能会根据不同设备而有所不同,这里这里说的是默认的大小(缓存的数量是硬编码的):
- 1024*512 alpha缓存。
- 2048*256 alpha缓存。
- 2028*512alpha缓存。
- 1024*512alpha缓存。
- 2048*256alpha缓存。
当缓存纹理对象创建之后,其对应的缓冲区不会自动分配空间,除了1024*512的alpha缓存总是自动分配外,其它的都是根据需要来分配空间。
字形符号以列的形式打包在纹理中,只要字体渲染器遇到没有缓存的符号,它就会向缓存纹理请求响应的类型(存储在以上的有序列表中),然后缓存该符号。
这是上述的blocks列表使用到的地方,这个列表包含了当前已分配的列和所有未分配的空间。如果字形符号和已经存在的列匹配,那该字形符号就会被加到该列的底部。
如果所有列都被占用,从左边的剩余空间开辟新列。因为所有字体都是等宽的,渲染器会把每个字形的宽度弄成4像素的倍数(默认是4像素)。这是对列的重利用和字形打包的一个折衷,这个打包目前还不是很好,但是实现起来比较快。
所有的字形符号都存储在一个含有1个像素边框的结构中,这样在双线过滤采样的时候可以避免伪迹的产生。
在文字带有缩放变形操作的渲染中,了解文字何时被渲染也是非常重要的。这个变形操作直接到Skia/Freetype来处理,这就意味着字形符号是 在缓存结构中变形存储的。这样可以改善渲染的质量。幸运的是,文字一般很少做缩放动画效果,就算是使用了,也只是设计很少的字形符号。本人做过很多实验, 也没有找到一个实际使用的场景。
还有其它关于paint的属性会影响字形符号的栅格化和存储的:粗体、斜体、还有X缩放(在Canvas上做矩阵变换)、字体风格以及线条宽度等。
栅格化的可选方案
事实上,还有其它的方式去在GPU上处理文字字形符号。可以直接被渲染程向量,但是这样做开销很大。我调查过标记距离字段的方法,但是简单实现的时候遇到了精度的问题(创建曲线的时候会不稳定)。
本人建议读者可以看看Glyphy这个项目。这是一个开源库,作者是Harfbuzz。项目在标记距离字段技术上进行延伸,同时也解决了精度的问题。我暂时没有花太多时间看这个项目。但是上一次在做着色器的时候,发现这种技术在Android上是被禁止使用的。
预缓存技术
字形符号缓存是一定要做的。如果做预缓存的话,效果会更好。因为libhwui是一个延迟的渲染器(和Skia的快速模式正好相反),所有屏幕上出现的字形都是一帧一帧开始的。在一系列的显示操作(批处理和合并操作)中,字体渲染器需要尽可能多地缓存字形符号。
使用预缓存技术的主要优势在于,可以完全或者最小化纹理加载的时间。纹理加载操作是消耗非常大的,它会推延CPU或者GPU。甚至在帧渲染过程中,改变纹理还会在GPU体系结构带来更多内存的压力。
ImaginationTech的PowerVRml SGX GPUs使用了延迟叠加技术架构,可以提供很多有趣的特性。但如果在渲染帧时需要修改纹理,会强制要求驱动程序对纹理进行复制。因为字体结构相当大,如果不好好处理纹理加载的话,很容易就内存耗尽了。
这样的场景确实发生在Google Play的一个应用中。这个APP是一个简单的计算器,仅使用一些数学符号和数字进行简单的绘制按钮。字体渲染器在某的时候甚至渲染不出***帧。因为按钮 是连续进行绘制的,每一个按钮都会触发一个纹理加载,然后复制整个字体缓存。系统根本没有这么多内存去存储这么多缓存的备份。
清空缓存
因为用作字形缓存的纹理是非常大的,它们有时会被系统回收再利用,以便为其它程序更多的RAM。
当用户隐藏当前的应用时,系统给应用发送一条消息要求释放尽可能多的内存。很明显,这就需要销毁***的字形缓存结构。在Android中,这个大缓存结构就是所有字形的缓存。除了默认***个创建的以外(1024*512的默认缓存)。
纹理结构在没有存储空间的时会被清空。字体渲染器使用LRU算法对素有字体进行记录,仅仅是记录而已。如果需要,就会根据最近最少使用的纹理来清除内存。目前没有提供这个操作,但是它确实是一个不错的优化策略。
批处理和合并操作
Android4.3引入的绘制批处理和合并操作是一项重要的优化,彻底减少了大量往OpenGL驱动发送指令的问题。
为了进行合并操作,字体渲染器在进行多种绘制调用的时候会缓存文字,每个缓存纹理都会拥有一个客户端的2048 quads的数组(1 quad = 1 glyph)。当调用lilbhwui中的一个文字绘制API时,字体渲染器获取合适的网格为每个字形符号进行位置和u/v坐标的绘制。网格在批处理的末 端被发送到GPU上(由延迟显示系统决定)。或者当一个quad的缓冲区满了的时候,可能会出现多网格渲染同一个字符串的情况——一个字符缓存占用一个网 格。
这个优化过程很容易实现,对显示效果帮助也很大。因为字体渲染器使用多缓存结构,所以在一个字符串的渲染过程汇总,可能字形符号会来自不同的纹理。 如果没有批处理好合并操作的话,每个绘制调用都要传递给GPU。字体渲染器就需要不断切换不同的缓存结构,这样会带来很大的消耗。
在测试字体渲染器的时候,我已经在一个测试App中发现了这个问题。这个App只是简单地用不同的样式和大小渲染一句“hello world”。其中字母“o”被存储在不同的纹理中,和其它的字符不一样。这种情况导致字体渲染器开始时只绘制了“hell”,然后渲染“o”,然后再渲 染“w”,然后在渲染“o”,接着才是“rld”。这5个绘制调用和5个纹理进行绑定连接后,只有其中两个是实际需要的,现在渲染器先绘制“hell w rld”,然后在一起绘制两个“o”,这就是批处理和合并操作的好处了。
优化纹理加载
之前提到过字体渲染在更新缓存纹理的时候(记录每个纹理中的脏数据块)会尽可能加载少一点数据。但是很不幸,这个方法还是有两个限制。
首先,OpenGL ES2.0不允许随意上传一个矩形区域。glTextSubImage2D 会让你指定矩形的x/y坐标和宽高来更新矩形里面的纹理。并且它会把矩形的宽当做内存里的数据幅度,这个可以通过创建一个合适大小的CPU缓冲区来解决, 但是也需要事先知道这个矩形的到底有多大。
有一个很好的折衷,就是加载包含脏数据块(矩形)的最小像素带。因为这个像素带和纹理一样宽,这样就可以节省空间。比每次都要更新整个纹理效果好得多。
第二个问题是纹理加载属于异步调用,这样可能造成相当长的CPU延迟(甚至可能会达到1毫秒,依赖纹理的大小、驱动程序还有GPU)。像之前说的那 样,如果使用预缓存应该是没有问题的。但是如果使用的是“重字体”的场景,或者是区域化语言的场景的话(较多的使用字形符号比如中文),那么问题就还是会 出现的。
令人欣慰的是,OpenGL3.0为这两个问题提供了解决方案,这样就可以直接使用一个像素存储的属性来加载数据矩形了。GL_UNPACK_ROW_LENGTH这个属性指定了内存源数据的宽度。需要注意的是,这个属性会影响到当前OpenGL上下文的全局状态。
加载纹理时,CPU延迟可以通过使用像素缓冲对象(PBOs)来避免。就像所有OpenGL里的缓冲区对象一样PBO会驻留在GPU中,但也可以映 射到内存中。PBOs有很多有趣的属性,但是我们关心的是一个在主存中取消映射关系后还可以进行异步加载纹理的属性,此时操作队列变成:
glMapBufferRange → write glyphs to buffer → glUnmapBuffer → glPixelStorei(GL_UNPACK_ROW_LENGTH) → glTexSubImage2D
调用glTexSubImage2D可以立即返回,而不用阻塞渲染器,字体渲染器可以在内存中映射整个缓冲区,而且似乎不会出现问题。这对于缓存纹理的更新操作是一个不错的方案。
这两种OpenGL ES3.0的优化方法会出现在Android4.4中。
阴影效果
一般文字在渲染的时候都会带有阴影效果,这是一个相当耗费资源的操作。在临近的字形符号可以进行相互模糊操作之后,字体渲染器不再进行独立的预模糊 操作。有很多中方法可以实现模糊化,但是为了在同一帧中把这些调配操作和纹理采样操作最小化,阴影效果会被简单存储为纹理,在多帧切换的时候可以保存。
因为应用程序可以轻易地拖垮GPU,所以我们还是得依靠CPU来对文字进行模糊化。最简单和高效的方式就是使用Renderscript的C++ API,只需要简单几行代码就可以实现核心功能。最简单的方法是在初始化Renderscript的时候指定RS_INIT_LOW_LATENCY标记 来强制运行在CPU上。
未来的优化操作
有一个优化方法我希望可以在我离开Android团队之前实现。文字预缓存、异步和部分纹理更新都是一些重要的优化操作。但是栅格化文字符号一直都是一个很耗费资源的操作,在systrace可以很容易看到(启用gfs标识然后看precacheText事件)。
对预缓存的一个简单的优化方式就是,把这个操作放到另一个工作线程去执行,把栅格化操作放到后台。这个技术已经被用到一些复杂的路径栅格化操作中,但是没有添加到OpenGL架构之中。
改进批处理和合并操作也是一个可能的优化方式,用于绘制文字的颜色一般是被发送到一个fragment阴影统一操作。这样可以减少发送到GPU的顶 点数据,但副作用会产生很多不需要的批处理指令:一个批处理操作只能包含一种文字颜色。如果文字颜色也存储为顶点属性,那么就可以网GPU传递更少的数 据。
源代码
如果想详细地看看字体渲染器的实现,可以浏览libhwui的GitHub,可以从FontRender.cpp开始,因为很多惊喜都在这里发生,它的支持类可以在font或者sub目录找到。对了,PixelBuffer.cpp这个文件也不错,可以看看。这就是一个像素缓冲区的抽象实现,可以用于CPU(uint8_t类型的数组)或者GPU缓冲区(PBO)。
***的话
本文只是对Android的字体渲染器进行简单介绍,还有很多实现的细节没有考虑到,或者很多问题以后会说明,所以有什么问题可以尽管向我提问。
原文链接: medium 翻译: chris