【51CTO精选译文】本文将为读者介绍如何构建一套文档批量扫描系统。为了实现这个目标,我们将使用众多Linux工具。这种方法具有的优点是,这个过程可以定制,以符合你特定的需求。这为你提供了一套可处理重大任务,又能灵活定制的系统。
我们将着眼于两种可能的最终产品:每一页都是原始页扫描件的PDF文件,以及含有原始页文本内容的文本文件。文本文件的内容可以搜索,我们探讨了将文本文件转换成PDF文件的若干方法。
本教程具有模块化特点。比如说,如果你在处理一组预先扫描的图像,那么就可以略过头几个步骤,直接进入到使用光学字符识别(OCR)软件处理图像,或者将它们转换成PDF文件。同样,如果你偏爱使用图形用户界面(GUI)工具来处理这个过程的某些环节,也没有什么可以阻止你。话虽如此,我们还是尽量让这个过程的每个环节都可以编写脚本,以便实现全面自动化。
我们通过充分使用基于命令行的工具,确保这个项目的每个阶段都是可以定制、可以编写脚本。
- 相关资源
- Linux机器
- 扫描仪
- 具体步骤
第1步:安装SANE
你可以使用程序包管理器,安装主要的扫描仪程序包SANE(Scanner Access Now Easy)。要是你已安装了SANE,但是扫描仪访问起来还是有困难,网上可能有面向该扫描仪的针对特定厂商的SANE后端工具。如果是这种情况,不妨用谷歌搜索一下。
第2步:找到扫描仪
在命令行键入scanimage -L命令,检查一下SANE能否与你的扫描仪兼容。要是你的扫描仪得到支持,文本输出就会含有设备名称。你需要的那部分就是冒号前面的第一个元素。
第3步:扫描图像
键入scanimage -d [设备名称] > test.pnm,快速测试扫描某个对象。这会使用默认设置来扫描一页内容。在图形查看器中打开扫描后的文件,检查一下。要是遇到了问题,可以添加-v选项,以便排查故障。
第4步:完善scanimage选项
如果你打算使用OCR处理文本,或者不需要颜色,那么300 DPI分辨率和黑白是两个典型的选项。首先,这缩小了文件尺寸。scanimage -d [设备名称] -format=tiff -mode Lineart -resolution和300 > [文件名称]是两个典型的选项。
第5步:创建扫描脚本
我们将使用进行扫描的命令行字符串创建第一个脚本。使用一个文本编辑器,创建一个名为scan.sh的文件。添加#!/bin/bash作为头一行。添加你所用的扫描仪系列作为第二行。保存该文件。在命令行键入chmod +x scan.sh,让这个脚本成为可执行脚本。将./scan.sh键入到终端,以便运行它。接下来,我们在必要的阶段可以创建诸如此类的额外脚本。你可以把这些脚本合并成一个长脚本,也可以单独调用不同的阶段。
第6步:计算裁剪尺寸
用不着为这个阶段的旋转文档而操心。你可以使用程序包管理器,安装GIMP。在GIMP中打开扫描后文档,从工具面板中选择裁剪工具。让裁剪区覆盖文档的有效部分,然后在裁剪对话框中记下裁剪尺寸。如果你打算把迎面页分割成不同页面,就要记下适当的页面尺寸。别在GIMP中进行裁剪,因为我们稍后会从命令行来进行裁剪。
第7步:安装ImageMagick
使用程序包管理器,将ImageMagick安装到你的系统上。我们使用convert命令,与这个图像处理器工具进行交互。我们可以用它来旋转和裁剪图像,还可以用它来分割页面。要注意:convert在选项前面使用了单破折号。
第8步:裁剪页面
利用通过使用GIMP获得的相关参数,执行裁剪任务。键入convert [图像名称] +repage -crop [x width]x[y width]+[x offset]+y[offset] [输出名称]。比如说,convert page1.png +repage -crop 2244×3113+1+1 page1_crop.png就会裁剪从上边和左边1个像素开始、尺寸为2244 x 3113的矩形页面。
第9步:旋转页面
如果你不得不双面扫描页面,不妨使用ImageMagick来旋转页面。convert [输入名称] -rotate 90 [输出名称]可以完成这项任务。
第10步:分割迎面页
与之前一样,使用GIMP的裁剪功能,算出裁剪页面的确切尺寸。convert page1.tiff +repage -crop 2233×1579+0+1529 page1_a.tiff以及随后的convert page1.tiff +repage -crop 2233×1546+0+0 page1_b.tiff,可以从两个迎面页创建两个不同的文件。
第11步:创建预先处理的脚本
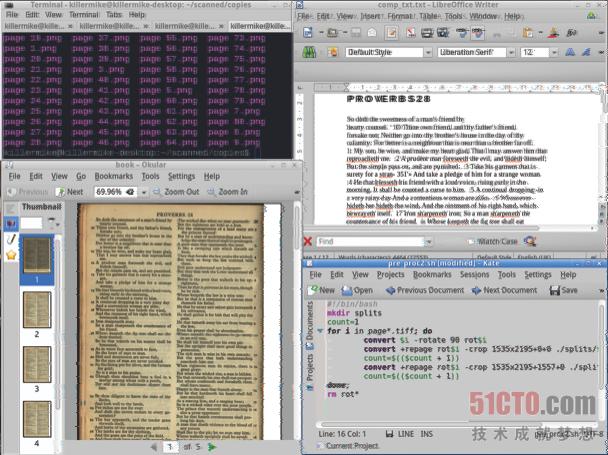
上面是一个示例的预先处理脚本。它创建了一个名为splits的目录,然后旋转每个扫描件,之后将其分割成按顺序编号的两个页面。最后,它删除经过旋转的文件。保存它,然后键入chmod +x命令,让它成为可执行脚本。
第12步:扫描仪批处理模式
使用针对多个页面的-batch系列选项。要是你没有送纸器,那就添加-batch-prompt选项,以便每次扫描之间加以提示。此外,可以添加-batch=./$page_%03d.tiff,提供以"page"开头、以带三个0的数字结尾的文件名称。
第13步:在扫描仪中预先裁剪
你也许能够在扫描仪中裁剪页面,这可以带来更小的文件和更快的操作,因为扫描头没必要扫过很远的距离。使用GIMP中的裁剪工具,在对话框中将单位由px(像素)改成mm(毫米),算出你所需要的尺寸和偏移量。要是结果证明以这种方式获得的信息不准确,不妨考虑改用原始的办法,使用直尺。在scanimage命令行上,额外标志的格式是-l [左边] -x [宽度] -t [上边] -y [高度].
第14步:双面文档
如果你要扫描双面文档,使用之前所说的batch选项,但要添加-batch-double选项,以便将页面数递增2个。在第二次扫描时,针对另一面,再次进行同一番操作,不过添加-batch-start=2,让编号递增。
第15步:将扫描件转换成PDF
你可以使用ImageMagick,将装满扫描后图像的目录转换成PDF"书册"。convert *.tiff output.pdf这个命令会创建一个多页文档。如果你需要插入标题页,将其命名为page000.tiff,然后放到该目录中。
第16步:借助Tesseract,使用OCR处理文本
不妨在测试页上试一下OCR引擎。为此,键入tesseract [输入文件名称] [输出文件]。别给输出文件名称添加文件扩展名,因为文件扩展名会由Tesseract来添加。请注意:Tesseract可以检测出多列文本和迎面页。
第17步:OCR批处理
使用下列Bash代码,使用OCR处理装满扫描后页面的目录:for i in *.tiff ; do tesseract $i outtext$i; done;最终结果是一组文本文件。使用cat *.txt >[输出文本文件],将这些文件结合起来。
第18步:文本格式化
默认情况下,Tesseract会将回车符插入到之前源文本中出现的同一个位置。你可以使用下面这个命令:fmt -u [输入文件] > [输出文件],重新为文本文件制作格式。
第19步:在LibreOffice中编辑文本
只要将从前几个步骤所得的输出结果剪贴到LibreOffice Writer中。在这个阶段,你可以控制编辑,并手动编辑节头等参数。你甚至可以插入来自原文档的图像。
第20步:从LibreOffice导出PDF文件
LibreOffice有一些内置工具,可用于创建PDF文件。如果你最终敲定了布局和格式,就进入到File(文件)>Export as PDF(导出为PDF文件)。由此处,点击Export(导出),为文档取个名称。
第21步:可以编写脚本的PDF创建
使用程序包管理器,安装iconv、ps2pdf和enscript这几个程序包。键入iconv -f UTF-8 -t ISO-8859-1 -c [输入文本文件][输出文本文件],准备好文本文件。键入enscript [文本文件] -p [输出postscript文件.ps]。键入ps2pdf [.ps文件],将PostScript转换成PDF。
原文链接:http://www.linuxuser.co.uk/tutorials/automatic-mass-scanning-of-documents-tutorial