













谷歌发现某些搜索关键词可以很好地标示流感疫情的现状。GFT的工作原理就是使用经过汇总的谷歌搜索数据来估测流感疫情,其预测结果将与美国疾病预防控制中心(Centers for Disease Control and Prevention,CDC)的监测报告相比对。但是2013年2月,《自然》杂志发文指出,GFT预测的流感样病例门诊数超过了CDC根据全美各实验室监测报告得出的预测结果的两倍(但GFT的构建本来就是用来预测CDC的报告结果的)。
研究***作者大卫·拉泽(David Lazer)认为造成这种结果的两个重要原因分别是“大数据傲慢”(Big Data Hubris)和算法变化。
“大数据傲慢”指的是这样一种观点:即认为大数据可以完全取代传统的数据收集方法,而非作为后者的补充。这种观点的***问题在于,绝大多数大数据与经过严谨科学试验得到的数据之间存在很大的不同。
编写一个将5000万搜索关键词与1152个数据点相匹配的算法是非常困难的,很有可能会出现过度拟合(将噪声误认为信号)的情况:很多关键词只是看似与流感相关,但实际上却并无关联。事实上,在2013年的报道之前,GFT就多次在很长一段时间内过高地估计了流感的流行情况。 2010年的一项研究发现,使用CDC的滞后预测报告(通常滞后两周)来预测当前的流感疫情,其准确性甚至都高于GFT的预测结果。
谷歌搜索引擎的算法并非一成不变的,谷歌对算法会进行不断地调整和改进。而搜索引擎算法的改变和用户的搜索行为会影响GFT的预测结果,比如媒体对于流感流行的报道会增加与流感相关的词汇的搜索次数,进而影响GFT的预测。
另外,相关搜索(People also search for)的算法也会对GFT造成影响。例如搜索“发烧”,相关搜索中会给出关键词“流感”,而搜索“咳嗽”则会给出“普通感冒”。
除此以外,搜索建议(recommended search)也会进一步增加某些热门词汇的搜索频率。
因为GFT会在它的模型中使用相对流行的关键词,所以搜索引擎算法对GFT的预测结果会产生不利影响。奇怪的是,GFT在构建时是基于这样一种假设:特定关键词的相对搜索量和特定事件之间存在相关性,问题是用户的搜索行为并不仅仅受外部事件影响,它还受服务提供商影响。
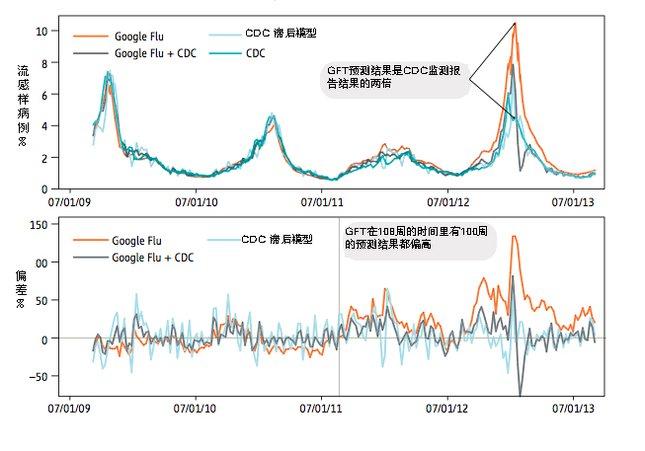
GFT在2012~2013的流感流行季节里过高的估计了流感疫情;在2011年~2012年则有超过一半的时间过高的估计了流感疫情。从2011年8月21日到2013年9月1日,GFT在为期108周的时间里有100周的预测结果都偏高。上图:对流感样病例门诊数的预测结果;下图:偏差%=(非CDC预测值-CDC预测结值)/CDC预测值,GFT的平均绝对偏差为0.486,CDC滞后模型的平均绝对偏差为0.311,GFT与CDC相结合的平均绝对偏差为0.232。以上统计结果P< 0.05。图片来源:The Parable of Google Flu:Traps in Big Data
拉泽和他的研究团队认为,如果谷歌可以公开衍生数据和汇总数据,那么研究者就可以更好地了解GFT背后的算法。此外,谷歌还需要解决可重复性的问题:利用谷歌的Correlate服务得到的与流感高度相关的关键词与GFT选取的关键词无法匹配。
另外,GFT的优势在于能够提供细化程度非常高的数据(数据粒度小)。因此与CDC相比,GFT的价值在于提供地区水平上的流感疫情预测。而且,GFT非常适合建立流感传播的生成式模型(Generative Model),并且对于预测几个月后的流感疫情具有较高的准确性。
数以百万的工程师和用户在不断改变着搜索引擎算法,而作为研究者则需要更好地理解这些变化,因为正是搜索引擎算法决定了我们最终得到的信息。
在论文的***作者指出,数据的价值并不仅仅体现在“大小”上。真正核心的改变在于利用创新的数据分析方法去分析数据,这样才能帮助我们更好的理解这个世界。













