1:Spark Standalone Mode安装
A:部署包生成
首先,下载并解压缩Spark的源码,切换到解压缩所生成的目录,运行部署包生成程序make-distribution.sh:
- ./make-distribution.sh --hadoop 2.2.0 --with-yarn --tgz
spark源码根目录下的make-distribution.sh可以带以下参数:
--tgz:在根目录下生成 spark-$VERSION-bin.tar.gz,不加参数是不生成tgz文件,只生成/dist目录。
--hadoop VERSION:打包时所用的Hadoop版本号,不加参数时为1.0.4。
--with-yarn:是否支持Hadoop YARN,不加参数时为不支持yarn。
--with-tachyon:是否支持内存文件系统Tachyon,不加参数时为不支持,此参数spark1.0之后提供。
运行成功后,在根目录下生成类似spark-0.9.0-incubating-hadoop_2.2.0-bin.tar.gz的部署包,不过该部署包只带有最基本的Spark运行文件,不包含例程和源代码。如果需要例程和源代码,请使用官方提供的二进制部署包。
笔者在百度云盘上提供了spark0.90、spark0.91和spark1.0-SNAPHOT的部署包,其中spark1.0-SNAPHOT还提供了支持Tachyon的部署包。
B:规划
虚拟机hadoop1(IP地址为192.168.100.171)作为Master
虚拟机hadoop2(IP地址为192.168.100.172)、hadoop3(IP地址为192.168.100.173)、hadoop4(IP地址为192.168.100.174)、hadoop5(IP地址为192.168.100.175)作为slave
由于hadoop1、hadoop2、hadoop3、hadoop4、hadoop5之前已经安装了hadoop2.2.0集群,所以省却了安装JAVA、建立SSH无密码登录过程。当然,spark集群可以独立于hadoop集群外安装,不过需要安装JAVA、建立SSH无密码登录,具体过程可以参照hadoop2.2.0测试环境搭建。
C:在Master上生成安装目录
将生成的spark-0.9.0-incubating-hadoop_2.2.0-bin.tar.gz文件复制到Master(即hadoop1)上并解压
[root@hadoop1 hadoop]# tar zxf spark-0.9.0-incubating-hadoop_2.2.0-bin.tar.gz
[root@hadoop1 hadoop]# mv spark-0.9.0-incubating spark090
[root@hadoop1 hadoop]# cd spark090
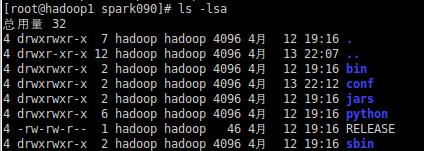
[root@hadoop1 spark090]# ls -lsa
D:配置集群文件
[root@hadoop1 spark090]# vi conf/slaves
[root@hadoop1 spark090]# cat conf/slaves
hadoop2
hadoop3
hadoop4
hadoop5
[root@hadoop1 spark090]# vi conf/spark-env.sh
[root@hadoop1 spark090]# cat conf/spark-env.sh
export SPARK_MASTER_IP=hadoop1
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1g
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}
E:派发安装文件到slaves
[root@hadoop1 spark090]# cd ..
[root@hadoop1 hadoop]# chown -R hadoop:hadoop spark090
[root@hadoop1 hadoop]# su - hadoop
[hadoop@hadoop1 ~]$ cd /app/hadoop/
[hadoop@hadoop1 hadoop]$ scp -r spark090 hadoop2:/app/hadoop/
[hadoop@hadoop1 hadoop]$ scp -r spark090 hadoop3:/app/hadoop/
[hadoop@hadoop1 hadoop]$ scp -r spark090 hadoop4:/app/hadoop/
[hadoop@hadoop1 hadoop]$ scp -r spark090 hadoop5:/app/hadoop/
F:启动集群
[hadoop@hadoop1 hadoop]$ cd spark090
[hadoop@hadoop1 spark090]$ sbin/start-all.sh
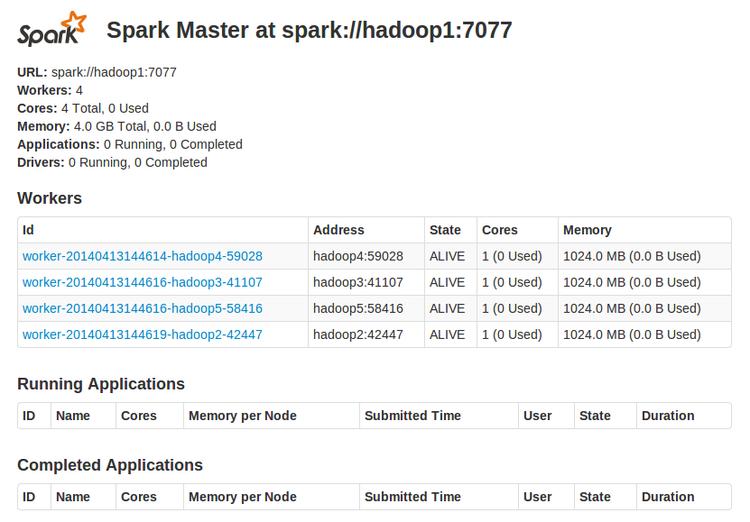
通过浏览器访问http://hadoop1:8080可以监控spark Standalone集群
2:关于spark-shell连接到spark Standalone集群
如果要启动spark-shell连接到spark Standalone集群,有两种方法:
a:使用MASTER=spark://hadoop1:7077 bin/spark-shell启动
b:配置在conf/spark-env.sh增加以下几行:
export SPARK_MASTER_IP=192.168.1.171
export SPARK_MASTER_PORT=7077
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}
然后使用使用./spark-shell启动
如果是远程客户端来连接到spark Standalone集群的话,部署目录要和集群的部署目录一致。
3:关于Spark Standalone Mode的运行
A:资源调度
Spark Standalone Cluster目前只支持FIFO方式调度,不过,允许多个并发用户,通过控制每个应用程序可获得的***资源数。默认情况下,一次只运行一个应用程序,应用程序使用集群中的所有内核,不过可以通过System.setProperty(“spark.cores.max”,“10”)设置使用的内核数,这个值必须在初始化SparkContext之前设置。
B:监控和日志
Spark Standalone Cluster可以通过Web UI来监控集群,Master和每个Worker都有各自的Web UI显示统计数据。
Spark运行的job明细在$SPARK_HOME/work(由参数SPARK_WORKER_DIR设定)。当一个job提交后,spark会分发给worker,在每个节点的$SPARK_HOME/work/jodID/executorID建立stdout和stderr目录作为job日志输出。
C:和Hadoop并用
Spark可以作为独立的服务,在已有的Hadoop集群设备上并行,并通过hdfs://URL存取Hadoop数据。当然,Spark也可以建成一个独立的集群,通过网络存取Hadoop数据,只不过会比本地硬盘存取速度要慢,对于处于本地网络的两个集群,这不是问题。
D:高可用
Spark存在单点故障的问题,要解决这个问题,有两个方案:通过 Zookeeper待机Master和本地文件系统的单点恢复,具体参考http://spark.incubator.apache.org/docs/latest/spark-standalone.html
4:测试
由于缺少例子,所以使用官方提供的二进制安装包重新部署了一下,并启动。
./run-example org.apache.spark.examples.SparkKMeans spark://hadoop1:7077 ./kmeans_data.txt 2 1
也可以直接在spark shell里调试程序。