1.反射型xss的介绍
xss代码出现在URL中,浏览器访问这个url后,服务端响应的内容中包含有这段xss代码,这样的xss被称作反射型xss.
2.工具的介绍
reflected_xss工具目前可以用来检测网站中是否可能存在反射型xss,程序是用python写的.
我用的python版本是2.7.3,系统上需要有python的requests模块.
工具有四个文件
spider.py用来爬取网页中的符合规则的url,可以指定爬取深度,然后生成一个urllist文件
reflect_xss.py检测urllist文件中的每一个url是否可能存在反射型xss漏洞
filter.py中的函数会被spider.py调用,过滤掉一些不带参数的url和重复的url.
config文件中,目前只有两个选项:timeout和sleep.
timeout是请求最多等待响应的时间.发送响应时,超过timout秒后就当作请求超时了.
sleep是每次请求url的间隔时间,因为有的网站会限制ip访问速度.
3.工具工作的流程
spider.py接受一个url参数,根据这个url发送请求,接收到响应后,把响应中符合规则的url提取出来,保存到urllist文件中.如果有指定爬取深度的话,会递归的爬取规则的url.这个规则是用正则写的,目前的规则是爬取到的url都应该是一个网站下的,并且url必须是带参数了的.
比如,spider.py “http://127.0.0.1/test.php?x=1″ 能够保存的url都是以http://127.0.0.1开头的,并且url中有一个?号.
reflect_xss.py会检查urllist文件中的每一个url是否存在反射型xss.检测流程是:分析每一个url的参数,将”参数”挨个替换成”参数+xss payload”,然后发送出去,分析响应的内容中是否有xss payload字符串.其中的xss payload可以自定义,keywords文件中的每一行都会被当作一个xss payload.可以向keywords文件添加或删除xss payload.
4.工具用法演示
先来大致看下当前目录下的文件吧
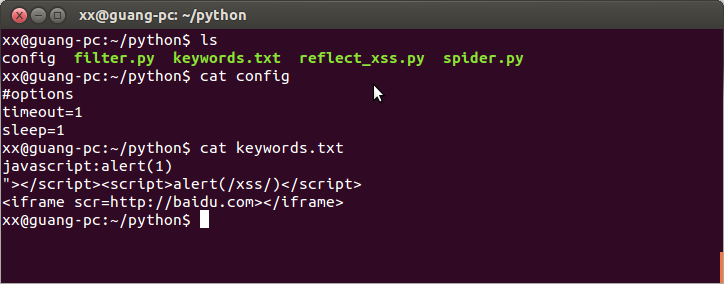
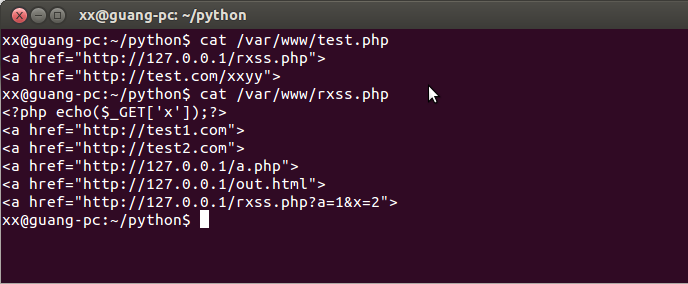
再来看看我用来在本机测试的两个文件吧.
只有http://127.0.0.1/rxss.php?a=1&x=2这个url是符合规则的,所以一会儿爬虫爬完了,urllist中应该只有这一条url.
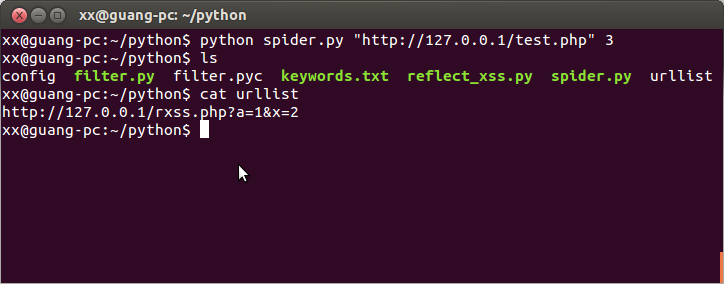
spider.py就是我们的小爬虫.
直接运行spider.py可以看到用法.
爬虫爬完了,生成了一个urllist文件,文件中只有一条url,一会儿就来检测这条url是否可能存在反射型xss缺陷
这个url参数最好还是要带上双引号,就跟用sqlmap的时候一样.
reflect_xss.py就是用来检测的.
直接python reflect_xss.py 运行程序就可以检测了.
如果有发现可能存在反射型xss,会在当前目录下生成一个Found文件,文件记录了有缺陷的url.

检测的时候,如果发生了异常,会被记录到当前目录下的error.log日志文件.这里没什么异常,所以没有记录.这个日志文件记录的比较简洁明了,我就不多做介绍了.
我的邮箱是:happy7513159@qq.com 欢迎交流
下载地址:http://vdisk.weibo.com/lc/3GawHF1w1aTxKu2BJjr 密码:CMB6
核心代码:
spider.py:
#!/usr/bin/env python
#coding=utf-8
import requests
import re
import string
import sys
import filter
headers={'Connection':'keep-alive',"User-Agent":"Mozilla/5.0 (X11; Linux i686) AppleWebkit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36","Origin":"http://www.oschina.net",'Accept-Encoding':'gzip,deflate,sdch','Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4','X-Requested-With':'XMLHttpRequest','Accept':'application/json,text/javascript,*/*;q=0.01'}
def saveurl(urlset):
try:
f=open("urllist","a")
for url in urlset:
#unicode字符码写入文件,添加换行
f.write(url.encode('UTF-8')+"n")
#except:
# print "Failed to write urllist to file!"
finally:
f.close()
def main(requestsurl,depth):
try:
#print "%d"%depth
depth=depth+1
urlset=parseContent(requests.get(requestsurl,timeout=2,headers=headers).text)
saveurl(urlset)
if depth==string.atoi(sys.argv[2]):
pass
else:
for u in urlset:
main(u,depth)
except:
pass
def parseContent(content):
strlist = re.split('"',content)
urlset = set([])
for strstr in strlist:
#python正则匹配时,需要\\表示
#if re.match('http://.*com(/|w)+', str):
#这个正则有点简单,只匹配了当前网站
#if re.match('http://'+domain, str):
rules="http://"+domain+"[^,^ ^ ^']*"
#strstr是unicode对象
result=re.compile(rules).findall(strstr.encode("utf-8"))
#result是一个数组
if len(result)==0:
pass
else:
for i in result:
urlset.add(i)
return list(urlset)
if __name__=="__main__":
if len(sys.argv)!=3:
print "usage:"+sys.argv[0]+" http://test.com/"+" depth"
print "example:"+sys.argv[0]+' "http://127.0.0.1/a.php?c=1"'+" 3"
else:
domain=sys.argv[1].split('/')[2]
#保存最开始的url
tmp=[]
tmp.insert(0,sys.argv[1]);
saveurl(tmp)
#开始抓取
main(sys.argv[1],0)
filter.filter()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
reflect_xss.py
#!/usr/bin/env python
#coding=utf-8
import requests
import sys
import time
import re
#global payloads
#payloads=['"><sCript>alert(1)</sCript>','<img src=@ onerror=x>']
jindu=0
def readconf(keyname):
isFound=0
try:
f=open("config","r")
lines=f.readlines()
for line in lines:
if line.startswith(keyname):
isFound=1
return line.split('=')[1]
if isFound==0:
errorlog("Warn:Can not to read key "+keyname+" from configure file")
return False
except:
errorlog("Warn:can not to read configure file ")
return False
def errorlog(str):
str=str+"n"
t=time.strftime('%m-%d %H.%M.%S--->',time.localtime(time.time()))
f=open("error.log","a")
f.write(t+str)
f.close()
def findlog(url):
try:
f=open("Found","a")
f.write(url+"n")
except:
errorlog("Fail:open 'Found' file")
finally:
f.close()
def main(payload,canshu,checkurl):
global jindu
url=checkurl.replace(canshu,canshu+payload)
#print "checking: "+url
#TODO timeout,防止ip被屏蔽应该有
if readconf("sleep"):
time.sleep(float(readconf("sleep")))
#可能有Timeout异常
try:
a=requests.get(url,timeout=1)
if a.text.find(payload)!=-1:
#print "Find!!!!"
#print url
#print "-----------------------"
findlog(url)
else:
if jindu%10==0:
print time.strftime('%H:%M.%S->',time.localtime(time.time()))+"checking the "+str(jindu)+"th"+" url:"+url
except:
errorlog("Fail:request.get "+url)
jindu=jindu+1
def parse(url):
#url=http://test.com/test.php?a=1&b=2&c=3
#canshus=["a=1","c=3"]
#有可能url是http://test.com这种,没有参数
#这种情况,返回一个空对象
try:
canshus=url.split("?")[1].split("&")
return canshus
except:
kong=[]
return kong
pass
def readfile(filename):
#这个global的位置放在上面效果就不一样,不懂为什么
#global payloads
try:
aa=open(filename,"r")
f=aa.readlines();
for i in range(0,len(f)):
#过滤掉n
f[i]=f[i].rstrip("n")
return f
except:
print "Failed to access "+'"'+filename+'" '"file!"
finally:
aa.close()
if __name__=="__main__":
if len(sys.argv)!=1:
print 'usage:'+sys.argv[0]+" url depth"
print 'example:'+sys.argv[0]+'"http://url/test.php?x=1&y=2" 3'
else:
#global payloads
payloads=readfile("keywords.txt")
urls=readfile("urllist")
for checkurl in urls:
for payload in payloads:
for canshu in parse(checkurl):
if len(canshu)!=0:
main(payload,canshu,checkurl)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.