在之前谈到的保序回归加速话题中,我们聊起如何利用Cython改进回归算法的性能表现。我觉得将Python优化代码的性能表现与原生Julia方案加以比对能够进一步明确大家对于速度提升的直观感受。
今天的文章将承接上一篇,因此大家在进行阅读前,不妨先对前文进行一番回顾、旨在掌握相关背景信息。
我们将借用前文中提到的两种算法,并在这里就性能表现在Julia与Python之间展开一番比拼。
线性PAVA
相关Cython代码可以通过Github上的scikit-learn进行下载,而Julia代码则来自GitHub上的Isotonic.jl。
Julia代码采用的是最为简单的PAVA表达,不掺杂任何花哨的内容与修饰;@inbounds宏的作用是客观比较Cython的执行效果并关闭bound check。
- function isotonic_regression(y::Vector{Float64}, weights::Vector{Float64})
- @inbounds begin
- n = size(y, 1)
- if n <= 1
- return y
- end
- n -= 1
- while true
- i = 1
- pooled = 0
- while i <= n
- k = i
- while k <= n && y[k] >= y[k+1]
- k += 1
- end
- # Find a decreasing subsequence, and update
- # all points in the sequence to the weighted average.
- if y[i] != y[k]
- numerator = 0.0
- denominator = 0.0
- for j in i : k
- numerator += y[j] * weights[j]
- denominator += weights[j]
- end
- for j in i : k
- y[j] = numerator / denominator
- end
- pooled = 1
- end
- i = k + 1
- end
- if pooled == 0
- break
- end
- end
- end
- return y
- end
- isotonic_regression(y::Vector{Float64}) = isotonic_regression(y, ones(size(y, 1)))
linear_pava.jl hosted with ❤ by GitHub
- @cython.boundscheck(False)
- @cython.wraparound(False)
- @cython.cdivision(True)
- def _isotonic_regression(np.ndarray[DOUBLE, ndim=1] y,
- np.ndarray[DOUBLE, ndim=1] weight,
- np.ndarray[DOUBLE, ndim=1] solution):
- cdef:
- DOUBLE numerator, denominator
- Py_ssize_t i, pooled, n, k
- n = y.shape[0]
- # The algorithm proceeds by iteratively updating the solution
- # array.
- # TODO - should we just pass in a pre-copied solution
- # array and mutate that?
- for i in range(n):
- solution[i] = y[i]
- if n <= 1:
- return solution
- n -= 1
- while 1:
- # repeat until there are no more adjacent violators.
- i = 0
- pooled = 0
- while i < n:
- k = i
- while k < n and solution[k] >= solution[k + 1]:
- k += 1
- if solution[i] != solution[k]:
- # solution[i:k + 1] is a decreasing subsequence, so
- # replace each point in the subsequence with the
- # weighted average of the subsequence.
- # TODO: explore replacing each subsequence with a
- # _single_ weighted point, and reconstruct the whole
- # sequence from the sequence of collapsed points.
- # Theoretically should reduce running time, though
- # initial experiments weren't promising.
- numerator = 0.0
- denominator = 0.0
- for j in range(i, k + 1):
- numerator += solution[j] * weight[j]
- denominator += weight[j]
- for j in range(i, k + 1):
- solution[j] = numerator / denominator
- pooled = 1
- i = k + 1
- # Check for convergence
- if pooled == 0:
- break
- return solution
_isotonic.pyx hosted with ❤ by GitHub
Active Set
Active Set的行数与Cython代码基本相当,而且在结构上可能更为简洁(通过显式复合type ActiveState实现)、旨在维持给定主动双重变量中的参数。Active Set会将重复代码拆分为独立函数,从而由LLVM对其实现内联——这一点很难借由Cython中的任何参数实现。
Julia中的检索机制也会对算法作出一定程度的精简。
- immutable ActiveState
- weighted_label::Float64
- weight::Float64
- lower::Int64
- upper::Int64
- end
- function merge_state(l::ActiveState, r::ActiveState)
- return ActiveState(l.weighted_label + r.weighted_label,
- l.weight + r.weight,
- l.lower,
- r.upper)
- end
- function below(l::ActiveState, r::ActiveState)
- return l.weighted_label * r.weight <= l.weight * r.weighted_label
- end
- function active_set_isotonic_regression(y::Vector{Float64}, weights::Vector{Float64})
- @inbounds begin
- active_set = [ActiveState(weights[i] * y[i], weights[i], i, i) for i in 1 : size(y, 1)]
- current = 1
- while current < size(active_set, 1)
- while current < size(active_set, 1) && below(active_set[current], active_set[current+1])
- current += 1
- end
- if current == size(active_set, 1)
- break
- end
- merged = merge_state(active_set[current], active_set[current+1])
- splice!(active_set, current:current+1, [merged])
- while current > 1 && !below(active_set[current-1], active_set[current])
- current -= 1
- merged = merge_state(active_set[current], active_set[current+1])
- splice!(active_set, current:current+1, [merged])
- end
- end
- for as in active_set
- y[as.lower:as.upper] = as.weighted_label / as.weight
- end
- end
- return y
- end
- active_set_isotonic_regression(y::Vector{Float64}) = active_set_isotonic_regression(y, ones(size(y, 1)))
active_set.jl hosted with ❤ by GitHub
- @cython.boundscheck(False)
- @cython.wraparound(False)
- @cython.cdivision(True)
- def _isotonic_regression(np.ndarray[DOUBLE, ndim=1] y,
- np.ndarray[DOUBLE, ndim=1] weight,
- np.ndarray[DOUBLE, ndim=1] solution):
- cdef:
- Py_ssize_t current, i
- unsigned int len_active_set
- DOUBLE v, w
- len_active_set = y.shape[0]
- active_set = [[weight[i] * y[i], weight[i], [i, ]]
- for i in range(len_active_set)]
- current = 0
- while current < len_active_set - 1:
- while current < len_active_set -1 and \
- (active_set[current][0] * active_set[current + 1][1] <=
- active_set[current][1] * active_set[current + 1][0]):
- current += 1
- if current == len_active_set - 1:
- break
- # merge two groups
- active_set[current][0] += active_set[current + 1][0]
- active_set[current][1] += active_set[current + 1][1]
- active_set[current][2] += active_set[current + 1][2]
- active_set.pop(current + 1)
- len_active_set -= 1
- while current > 0 and \
- (active_set[current - 1][0] * active_set[current][1] >
- active_set[current - 1][1] * active_set[current][0]):
- current -= 1
- active_set[current][0] += active_set[current + 1][0]
- active_set[current][1] += active_set[current + 1][1]
- active_set[current][2] += active_set[current + 1][2]
- active_set.pop(current + 1)
- len_active_set -= 1
- for v, w, idx in active_set:
- solution[idx] = v / w
- return solution
_isotonic.pyx hosted with ❤ by GitHub
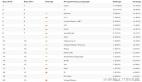
性能表现
可以看到,在与Cython实例进行比对时,我们发现即使是同样的算法在Julia中的平均执行速度也会更快。

对于上述Active Set实例,Julia在处理回归计算时的表现都能实现5倍到300倍的速度提升。
对于线性PAVA实例,Julia的速度提升效果则为1.1倍到4倍之间。
这样的结果证明,Julia在性能敏感型机器学习应用领域具有显著吸引力。
大家可以点击此处了解更多关于上述性能测试结果的获取方法。