用户行为类数据的特点在于用户数量庞大,但每个用户的行为数量较小,针对用户行为的计算较为复杂,用户之间的关联计算相对较少。
用户数量庞大。通话记录中的电话号码、访问日志中的用户编号、账户信息中的银行账户、交易记录中股票账户、保单信息中的被保险人,这些都是用户行为类数据中的用户。用户的数量通常都很庞大,多的可达亿级或更多,少的也有***。
每个用户的行为数量较小。相对于庞大的用户数量,每个用户的行为通常较少。对单个电话号码来说,平均每月的通话记录只有数百条,每年也不超过一万条。即使是网站的活跃用户,他们每天最多也只能产生上百条行为记录,每年不超过十万条。
用户行为的计算较为复杂。计算用户的两次登录间隔天数、反复购买的商品、累积在线时间,这些都是针对用户行为的计算,通常具有一定的复杂性。
用户之间的关联计算较少。用户的行为相对独立,一般不需要知道其他用户即可实现计算。相应的,用户之间的关联计算则较少,比如:某人通话记录中接听电话的一方的通话时长;社交网站上某个用户的朋友购买了哪些商品,这些计算存在但不多。
根据用户行为类大数据的特点不难看出,其最直观最容易写出的算法可以这样设计:每次将某一用户的所有数据一次性加载到内存中来计算,而不要反复访问硬盘读取某个用户的部分数据,也不要将大量用户的数据同时加载到内存中。
将某一用户的所有数据加载到内存中来计算。这样做是因为用户之间的关联计算少,而单个用户行为的计算较为复杂,计算同一个用户的数据可以让程序员减少不相干数据的干扰。比如计算某用户反复购买的商品。首先,将某用户的数据按商品分组汇总出每件商品的购买次数;再按次数逆序排序;过滤掉只购买了一次的商品,剩下的就是反复购买的商品及购买次数。再比如计算某用户的累积在线时长。该用户会访问多次,每次都会形成一对登录和退出,因此先要过滤出所有的登录和退出记录;再针对每一次访问,用退出时刻减去登录时刻,这就是单次时长;将多个单次时长相加,就是累积时长。
另外,因为每个用户的行为数量相对较少,完全可以全部加载进内存进行自由灵活的计算。
不要反复访问硬盘读取用户的部分数据。由于用户的行为计算比较复杂,同一个用户的各条数据之间是存在关联关系的,读取一个用户的部分记录去计算会导致算法难写,而且性能很低。
不要将大量用户的数据同时加载到内存中。由于用户数量庞大,显然不可能将全部用户的数据一次性加载到内存中来,必须要分批读取。分批的标准上面已经分析出来了:按用户分批。至于用户之间计算结果的合并,可以留到***一步再做,由于用户之间关联计算少,这个合并非常简单。比如计算所有用户反复购买的商品或累计在线时长,只要计算出每个用户反复购买的商品或累计的在线时长,再将所有用户的计算结果简单合并就可以。另外还可以看出,由于是用户之间的关联少,因此此类算法很适合使用并行计算,即每个节点机分配一定数量的用户,这样既不会增加难度又能大幅提高性能。
将同一用户的所有数据加载到内存中来计算,这就需要事先将数据按用户分成多个组。比如按零售店会员分组,每个组就是某个会员对应的多条采购记录;或按用户编号分,每个组是某个用户对应的网页访问记录。分组的实质是排序,即将数据按用户排序,使同一个用户的数据挨在一起。可以想象到,对亿级的用户、每用户万级的数据排序将是个非常缓慢的过程。事先排序可以加速分组的过程。
将数据事先按用户排序,不同的计算目标都使用同样排序好的数据。将排序的时间花在前面而且只花一次,这就可以避免计算时的大排序,参数不同的同一个计算目标也可以重复计算而不必重复排序,不同的计算目标还可以省去相同的排序过程。
但是,不幸的是,一般的计算工具难以实现上述算法,无法有效利用事先排序的数据。比如SQL(含Hive)和MapRreduce。
SQL的困难。SQL的集合是无序的,事先按索引重新插入排好序的数据往往不能被优化器正确优化,具有很大的偶然性,无法保证查询时可以按排好的次序查询出需要的数据。
Hive具有SQL的语法风格,同时也支持并行计算,但它却并不适合用户行为类大数据计算。这是因为用户行为的计算较为复杂,需要窗口函数甚至存储过程来解决,而Hive只支持基本的SQL语法,不支持窗口函数和存储过程。
用户行为的计算之所以较为复杂,是因为需要对同一个用户的多条数据之间进行计算,这种计算大多和顺序相关。SQL对有序计算的支持有限,只有窗口函数可以实现部分简单的有序计算,但对于复杂的业务逻辑仍然显得非常繁琐,而且经常因为大排序造成低下的性能。使用程序性的存储过程编写复杂代码可以实现复杂的有序计算,但很难复用SQL的集合运算能力,所有处理都有从基础运算自己编写,而且其性能通常比SQL更低。
MapReduce的困难。MapReduce支持大数据并行计算,同时它是用程序性的JAVA语言来编写的,这一点和存储过程有相似性。但是,MapReduce所使用的 JAVA语言缺乏针对结构数据计算的类库,所有的底层功能都要自己实现:分组、排序、查询、关联等等,对于有序计算这较复杂的算法所要书写的代码更多、编写难度更大、维护更加困难。同样的,MapReduce也无法利用已经排序好的数据,在shuffle阶段还需要得做大排序。
SQL和MapReduce无法利用事先排序好的数据,难以高性能地将同一用户的所有数据加载到内存中来计算,用户类大数据计算因此会遇到性能、扩展性和开发难度的挑战。
如何利用事先排序好的数据,以此简化代码书写难度并提高计算性能?
集算器是支持多节点并行计算的程序设计语言,并提供丰富的有序计算。如果数据事先排好序,集算器支持通过游标来按组读取数据,每次读取一组数据进内存,避免反复的外存访问,整个数据只要遍历一次即可,从而使性能大大提高。针对组内计算复杂,集算器具有完备的批量化数据计算类库,可以轻松实现各类复杂的有序计算。。
集算器支持灵活自由的多节点并行计算,可以进一步优化性能。方法之一将用户按某种方式分段,以此实现分布存储后的高效并行处理。比如将会员零售数据按照会员编号的前两位分成100段存储于HDFS,每段存储十万会员的一亿条数据。或者将网站日志按照用户ID的首字母和年份分段,每段存储几百万用户的数据。或者将通话记录按照区号和用户数量合并为30段,每段存储一个州或几个州的用户。经过分段处理后,每段数据都是排好序的,可被节点机的一个线程独立处理,这样的并行计算性能更高。
针对上面的难点,下面用”每个用户在每种产品上的累积在线时间”为例来说明集算器的一般解决办法。
大分组的困难:事先排序数据,以供多种计算目标使用。在节点机运算时可以直接按用户分组取数,有效利用已经有序的数据以提高性能。

组内计算复杂:esProc具有完备的批量化数据计算类库,可以轻松实现各类复杂的有序计算。
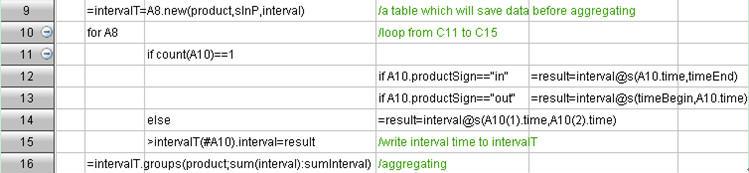
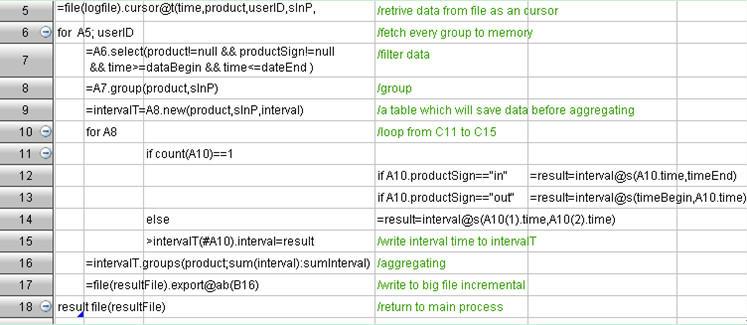
完整的代码如下:
原文链接:http://www.36dsj.com/archives/6812