问题描述
Linux服务器内存使用量超过阈值,触发报警。
问题排查
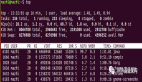
首先,通过free命令观察系统的内存使用情况,显示如下:
- total used free shared buffers cached
- Mem: 24675796 24587144 88652 0 357012 1612488
- -/+ buffers/cache: 22617644 2058152
- Swap: 2096472 108224 1988248
其中,可以看出内存总量为24675796KB,已使用22617644KB,只剩余2058152KB。
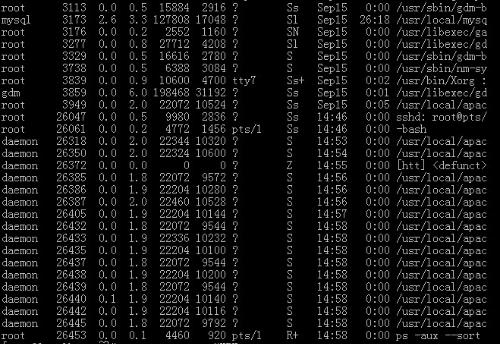
然后,接着通过top命令,shift + M按内存排序后,观察系统中使用内存***的进程情况,发现只占用了18GB内存,其他进程均很小,可忽略。
因此,还有将近4GB内存(22617644KB-18GB,约4GB)用到什么地方了呢?
进一步,通过cat /proc/meminfo发现,其中有将近4GB(3688732 KB)的Slab内存:
- ......
- Mapped: 25212 kB
- Slab: 3688732 kB
- PageTables: 43524 kB
- ......
Slab是用于存放内核数据结构缓存,再通过slabtop命令查看这部分内存的使用情况:
- OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
- 13926348 13926348 100% 0.21K 773686 18 3494744K dentry_cache
- 334040 262056 78% 0.09K 8351 40 33404K buffer_head
- 151040 150537 99% 0.74K 30208 5 120832K ext3_inode_cache
发现其中大部分(大约3.5GB)都是用于了dentry_cache。
问题解决
1. 修改/proc/sys/vm/drop_caches,释放Slab占用的cache内存空间(参考drop_caches的官方文档):
- Writing to this will cause the kernel to drop clean caches, dentries and inodes from memory, causing that memory to become free.
- To free pagecache:
- * echo 1 > /proc/sys/vm/drop_caches
- To free dentries and inodes:
- * echo 2 > /proc/sys/vm/drop_caches
- To free pagecache, dentries and inodes:
- * echo 3 > /proc/sys/vm/drop_caches
- As this is a non-destructive operation, and dirty objects are notfreeable, the user should run "sync" first in order to make sure allcached objects are freed.
- This tunable was added in 2.6.16.
2. 方法1需要用户具有root权限,如果不是root,但有sudo权限,可以通过sysctl命令进行设置:
- $sync
- $sudo sysctl -w vm.drop_caches=3
- $sudo sysctl -w vm.drop_caches=0 #recovery drop_caches
操作后可以通过sudo sysctl -a | grep drop_caches查看是否生效。
3. 修改/proc/sys/vm/vfs_cache_pressure,调整清理inode/dentry caches的优先级(默认为100),LinuxInsight中有相关的解释:
- At the default value of vfs_cache_pressure = 100 the kernel will attempt to reclaim dentries and inodes at a “fair” rate with respect to pagecache and swapcache reclaim. Decreasing vfs_cache_pressure causes the kernel to prefer to retain dentry and inode caches. Increasing vfs_cache_pressure beyond 100 causes the kernel to prefer to reclaim dentries and inodes.
具体的设置方法,可以参考方法1或者方法2均可。
参考资料
- https://www.kernel.org/doc/Documentation/sysctl/vm.txt
- http://major.io/2008/12/03/reducing-inode-and-dentry-caches-to-keep-oom-killer-at-bay/
- http://linux-mm.org/Drop_Caches
以下记录的是进一步排查的进展情况。
更深层次的原因
上文排查到Linux系统中有大量的dentry_cache占用内存,为什么会有如此多的dentry_cache呢?
1. 首先,弄清楚dentry_cache的概念及作用:目录项高速缓存,是Linux为了提高目录项对象的处理效率而设计的;它记录了目录项到inode的映射关系。因此,当应用程序发起stat系统调用时,就会创建对应的dentry_cache项(更进一步,如果每次stat的文件都是不存在的文件,那么总是会有大量新的dentry_cache项被创建)。
2. 当前服务器是storm集群的节点,首先想到了storm相关的工作进程,strace一下storm的worker进程发现其中有非常频繁的stat系统调用发生,而且stat的文件总是新的文件名:
sudo strace -fp <pid> -e trace=stat
3. 进一步观察到storm的worker进程会在本地目录下频繁的创建、打开、关闭、删除心跳文件,每秒钟一个新的文件名:
sudo strace -fp <pid> -e trace=open,stat,close,unlink
以上就是系统中为何有如此多的dentry_cache的原因所在。
一个奇怪的现象
通过观察/proc/meminfo发现,slab内存分为两部分:
SReclaimable // 可回收的slab SUnreclaim // 不可回收的slab
当时服务器的现状是:slab部分占用的内存,大部分显示的都是SReclaimable,也就是说可以被回收的。
但是通过slabtop观察到slab内存中最主要的部分(dentry_cache)的OBJS几乎都是ACTIVE的,显示100%处于被使用状态。
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME 13926348 13926348 100% 0.21K 773686 18 3494744K dentry_cache 334040 262056 78% 0.09K 8351 40 33404K buffer_head 151040 150537 99% 0.74K 30208 5 120832K ext3_inode_cache
为什么显示可回收的,但是又处于ACTIVE状态呢?求Linux内核达人看到后热心解释下:(
会不会由于是ACTIVE状态,导致dcache没有被自动回收释放掉呢?
让系统自动回收dcache
上一小节,我们已经提到,服务器上大部分的slab内存是SReclaimable可回收状态的,那么,我们能不能交给操作系统让他在某个时机自动触发回收操作呢?答案是肯定的。
查了一些关于Linux dcache的相关资料,发现操作系统会在到了内存临界阈值后,触发kswapd内核进程工作才进行释放,这个阈值的计算方法如下:
1. 首先,grep low /proc/zoneinfo,得到如下结果:
low 1
low 380
low 12067
2. 将以上3列加起来,乘以4KB,就是这个阈值,通过这个方法计算后发现当前服务器的回收阈值只有48MB,因此很难看到这一现象,实际中可能等不到回收,操作系统就会hang住没响应了。
3. 可以通过以下方法调大这个阈值:将vm.extra_free_kbytes设置为vm.min_free_kbytes和一样大,则/proc/zoneinfo中对应的low阈值就会增大一倍,同时high阈值也会随之增长,以此类推。
$ sudo sysctl -a | grep free_kbytes vm.min_free_kbytes = 39847 vm.extra_free_kbytes = 0
$ sudo sysctl -w vm.extra_free_kbytes=836787 ######1GB
4. 举个例子,当low阈值被设置为1GB的时候,当系统free的内存小于1GB时,观察到kswapd进程开始工作(进程状态从Sleeping变为Running),同时dcache开始被系统回收,直到系统free的内存介于low阈值和high阈值之间,停止回收。
原文链接:http://www.cnblogs.com/panfeng412/p/drop-caches-under-linux-system.html
http://www.cnblogs.com/panfeng412/p/drop-caches-under-linux-system-2.html