我一定让很多浏览我blog关于描述 Arista’s VARP 和 Enterasys’ Fabric Routing 的读者感到困惑—- 我得到了很多关于文章中“关于其如何在生产环境下工作”的问题。 接下来我们将就这个问题的细节进行讨论。
简单网络拓扑
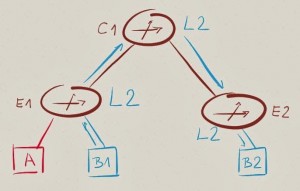
我们以一个简单的网络拓扑为例, 拓扑中包括两台边界交换机(E1和E2),一个单独的核心交换机(C1), 三台主机(A,B1和B2)分别隶属于两个子网(A和B)。
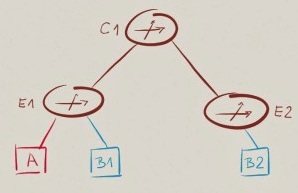
我们假设我们已经完成了一些针对于三层转发的优化配置, 所以E1和E2将负责子网A和B三层数据的转发(通常这种转发我们称之为路由)。
当A发送网络流量给B1或者B2时,E1将数据发送给子网B,相对应如果B2想与A通信,E2将会转发数据流给子网A。
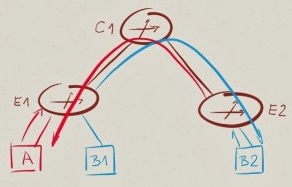
拓扑中谁做了些什么?
在上面拓扑环境中,真正我们应该关心的问题是:在数据转发路径中(E1-C1-E2),哪个交换机负责二层转发(通过查询目的MAC地址进行转发),哪个负责三层路由(通过目的IP地址进行路由)?
首先我们对子网内部数据转发进行分析: B1发送IP数据包给B2。 要想完成数据通信, B1必须将IP数据包封装进MAC数据帧里, 这时,目的MAC地址将会是什么呢?
B1封装数据帧时,目的MAC地址是B1通过向B2的IP发送ARP请求去获取的—-通常来讲, 也就是B2的MAC地址。数据帧在由B1到B2的路径上一直以B2的MAC地址作为目的MAC地址,与此同时,路径上(E1,C1,E2)的交换机在进行二层转发时也是根据B2的MAC地址进行转发的。 以上流程如果能够工作,那么E1,C1,E2必须同时属于VLAN-B。
现在我们来讨论跨子网数据转发:A发送IP流量给B2, A知道B2在一个与自身不同的子网中, 这时, A将查询它自身的IP路由表去找到B2 IP的下一跳地址。 这里,主机通常有一条默认路由,这条默认路由指向默认网关(GW-A – the VARP/VRRP IP,这个IP地址由E1与E2共同维护)—-A将发送IP数据包给网关GW-A,并以GW-A的MAC地址进行数据帧封装。对于GW-A MAC地址, E1和E2是共享这个MAC地址的;在E1收到这个数据包后, 其将进行三层转发。
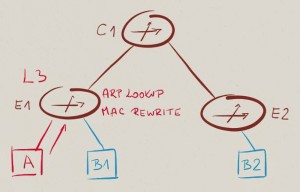
作为三层转发流程的一部分,E1自身递减了IP包的TTL并且重写MAC数据帧帧头。 重写后,目的MAC地址将变为新IP的下一跳对应的MAC地址—-在这个拓扑环境中, 这个下一跳为B2(这里注意:E1将会将IP包由子网A转发至子网B)。在之后的转发过程中,转发路径中的交换机(C1与E2)将遵循二层转发原则进行基于目的MAC地址转发数据。
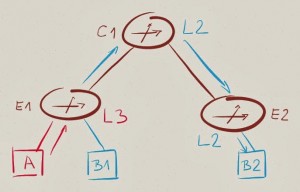
总结:E1 如果要与B2通信,其必须要有B2的ARP表项(否则E1将不知道B2的MAC地址),同时,与B2二层网络必须畅通(否则数据帧将无法到达B2)。
拓扑中,E1(作为入口交换机)进行三层(跨子网)基于目的IP地址的数据转发,其他交换机进行二层(子网内)基于目的MAC地址的数据转发。每个VLAN必须将覆盖所有边界及核心交换机。
最优化三层转发的扩展局限性
既然我们已经知道了转发流程的细节, 这里可以很容易想到这种最优化三层转发的扩展局限性:
每一个VLAN必须跨域所有在同一个路由域中的边界及核心交换机。整个路由域将成为一个单点失效域(single failure domain),换句话说也是一个无法扩展点。
每一个边界交换机必须知道所有活跃IP主机的MAC地址。
每一个边界交换机必须具有所有活跃IP主机的ARP表项。
此外,如果我们想用传统的配置机制(每一个边界交换机作为一个独立的可配置设备),每一个边界交换机需要在每一个子网中有一个网管IP地址。假设我们网络中有50台交换机,那么意味着我们将在每个/24 IPv4的子网中浪费50个地址(当然,这个问题在IPv6网络中我们应该不会那么担心)。
更多的细节:
从以上的讨论中,我想读者已经得到ARP表项的相关细节了, 而在我们对一个最优三层转发拓扑架构进行评估时,边界交换机支持我们去检查ARP表项(也就是IPv4 主机路由)。 QFX3500( QFX3500 has 8000 ARP entries)拥有8000条ARP表项的存储,QFX3600也一样。 Arista 7150较比QFX3500与3600而来,下一跳表项的存储空间达到了64K。如果需要更多数据,读者可以从Data Center Fabric Architectures webinar中得到前十名的设备提供商的大多数数据中心交换机的数据。