【51CTO独家特稿】今天天气不错,PM2.5只有50多,顺路在KFC吃了个早餐,到公司已经9:50了,打开电脑,接了杯水刚坐到工位被同事叫住了,告诉我A机房的公网流量出口快跑满了,看能不能找几个流量大的站点迁移到B机房。我的***反应就是说好扩充的流量为什么没有到位?(注:流量及硬件采购不属于运维部工作范畴)
我从心里很抵触做这种事情,原因很简单:几百个域名,分布到不同的IDC,从DNS管理解析到后端Web集群访问,都不是一个小数量级的。在自动化平台、管理平台不完善的情况下,做这种迁移后患无穷。片刻思考及分析后,迅速着手迁移。因为现在A机房公网流量已经达到极限,核心站点已经出现访问缓慢、无法加载的现象。
这种类型的迁移有两不碰:
- 不碰核心站点,重要性不言而喻;
- 不碰小流量站点,因为迁移访问量较小的站点需要迁移多个站点才能有冗余流量,明显耽误时间。
在无可视化数据平台、完全靠自己对业务的了解程度的情况下,分别迁移了像个人中心、企业中心、发布、无线M。迁移过程很简单,将A机房服务器上的Nginx配置分发到B机房服务器,随后更改DNS解析,A机房流量平稳下降,核心业务逐渐恢复正常。可当A机房流量刚降下时,B机房流量又接近上升到极限,因为此刻是每天中的流量峰值阶段,加上春节后的流量增长幅度,都已远远超过节前预估。
此时,大BOSS走近运维部开始“骂街”了:“就你们这么拖,花那么钱打再多广告有什么用,这种影响(网站打不开)是毁灭性的...”
做运维,练的就是心态,要足够淡定,无论遇到多大的事情都不能手忙脚乱。在我身后站着CEO、总经理、总监的情况下,我很淡定的将B机房部分域名迁移到C机房。至此,A、B、C三个机房流量平稳,所有业务已基本恢复正常。
吃一堑长一智,出了问题并不可怕,可怕的是我们从问题中学不到什么,怕的是类似的问题重现!面对如上这么大的一次故障,我们从中学到了些什么呢?
1、缺少数据可视化平台
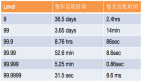
虽然有zabbix来监控服务器流量,但是zabbix只能监控到服务器整机物理流量,无法监控到某个域名的当前流量。若有一套能实时查看所有域名流量,通过纵向(每台服务器流量多少,当前HTTP并发多少)、横向(每个服务器上运行了多少个域名、每个域名流量多少、域名访问来源是什么)做可视化展示的系统,也不至于遇到问题才开始着手分析,若是对业务没有足够的了解,就很可能在解决问题时雪上加霜。
2、自动化平台建设不完善
当把某个域名从A机房迁移到B机房时,用的是命令行拷贝,费时费力,还容易发生误操作,缺少基于web形式的自动化管理平台。近期会做一个基于Nginx的管理系统,该系统可显示当前Nginx主机上正在使用的域名、单机总流量、并发、单个域名流量等,比如想把A机房服务器上的域名迁移到B机房服务器上,只需在web平台上选择一下源服务器和目标服务器然后点击确认就可以了。若做到这样,业务切换时间可大幅缩短。
3、资源扩充滞后
首先,由于流量扩容及硬件采购均不属于运维部工作范畴,加上流程上的影响,所以在效率上有着严重的滞后,这也是本次故障的直接原因之一;其次,多个机房公网交换设备均是千兆网口,且流量饱和度已达70%,若有大于30%的访问量增长,后果就可想而知了,这也是很大的潜在隐患。面对这种问题,网络组同学已连夜对机房公网交换设备做了升级。
【作者简介】
| 姓名 | 陆文举(@陆文举) |
| 职位 | 58同城 运维主管 |
| 技术特长 | 大规模web运维 |
| 关注方向 | 运维自动化、可视化 |