代码托管地址: Apache
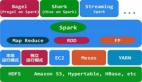
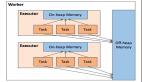
Spark是个开源的数据分析集群计算框架,最初由加州大学伯克利分校AMPLab开发,建立于HDFS之上。Spark与Hadoop一样,用于构建大规模、低延时的数据分析应用。Spark采用Scala语言实现,使用Scala作为应用框架。
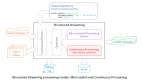
Spark采用基于内存的分布式数据集,优化了迭代式的工作负载以及交互式查询。与Hadoop不同的是,Spark和Scala紧密集 成,Scala像管理本地collective对象那样管理分布式数据集。Spark支持分布式数据集上的迭代式任务,实际上可以在Hadoop文件系统 上与Hadoop一起运行(通过YARN、Mesos等实现)。