













ns.conf 中注意修改的项目
public->log_level=debug #日志文件的级别 public->port = 8108 #nameserver监听端口 public->work_dir=/usr/local/tfs #工作目录,也就是tfs的安装目录 public->dev_name= eth0 #网络设备,即通信网卡,一般用内网 public->ip_addr = 192.168.119.145 #本机IP地址(vip),配置ha时为vip,没配置可以为主ns的ip
nameserver->ip_addr_list = 192.168.119.145|192.168.119.147 #nameserver IP地址列表(master, salve的ip地址,只能以’|'分隔) nameserver->block_max_size = 67108864 #Block size的***值, 单位(字节),必须 >= dataserver的mainblock_size,推荐设置一致。
nameserver->max_replication = 3 #Block ***备份数, default: 2,单台dataserver时,需要配置为1 nameserver->min_replication = 3 #Block 最小备份数, default: 2,#单台dataserver时,需要配置为1 nameserver->cluster_id = 1 # 集群号
ns.conf 内容 (其中有中文,要保存为UTF-8,不带标签)
[public] #log file size default 1GB #日志文件的size,默认 1GB log_size=1073741824
#保留日志文件的个数,默认 64 log_num = 64
#log file level default debug #日志文件的级别, default info,线上使用建议设为info,调试设为debug #dubug级日志量会很大 log_level=debug
#main queue size default 10240 #工作队列size, 默认 10240 task_max_queue_size = 10240
#listen port #nameserver监听端口 port = 8108
#work directoy #工作目录,也就是tfs的安装目录 work_dir=/usr/local/tfs
#device name #网络设备,即通信网卡,一般用内网 dev_name= eth0
#work thread count default 4 #工作线程池 default 4 thread_count = 4
#ip addr(vip) #本机IP地址(vip),配置ha时为vip,没配置可以为主ns的ip ip_addr = 192.168.119.145
[nameserver]
#系统保护时间,单位(秒), default: 300 #保护时间内不进行任何操作,包括添加block等 safe_mode_time = 300
#nameserver IP地址列表(master, salve的ip地址,只能以’|'分隔) #单台nameserver时,另一个ip配置为无效ip即可 ip_addr_list = 192.168.119.145|192.168.119.147
#Ip地址 mask #用于区分dataserver所在的子网,选择不同子网的dataserver备份数据 group_mask = 255.255.255.255
#Block size的***值, 单位(字节) #必须 >= dataserver的mainblock_size,推荐设置一致。 block_max_size = 83886080
#Block ***备份数, default: 2,单台dataserver时,需要配置为1 max_replication = 3
#Block 最小备份数, default: 2,#单台dataserver时,需要配置为1 min_replication = 3
#DataServer 容量使用的百分比, default: 98 use_capacity_ratio = 98
#Block使用的百分比, default: 95 block_max_use_ratio = 98
#heart interval time(seconds) #Dataserver 与 nameserver 的心跳时间, 单位(秒), default: 2 heart_interval = 2
# object dead max time(seconds) default # object 死亡的***时间, 单位(秒), default: 86400 object_dead_max_time = 3600
# cluster id defalut 1 # 集群号 cluster_id = 1
# block lost, replicate ratio # Block当前备份数与***备份数百分比,如果大于这个百分比,就开始复制 replicate_ratio_ = 50
#每个DataServer 主可写块的大小, default: 3 max_write_filecount = 16
#dataserver 与 nameserver 的心跳线程池的大小, default: 2 heart_thread_count = 2
#dataserver 与 nameserver 的心跳工作队列的大小, default: 10 heart_max_queue_size = 10
#replicate block wait time #block 缺失备份时, 需要等待多长时间才进行复制, 单位(秒), default: 240 repl_max_time = 60
#block进行压缩的比例, block 删除的文件的比例达到这个值时进行压缩 compact_delete_ratio = 15
#block进行压缩时, dataserver的***负载,超出这个值dataserver,不进行压缩 compact_max_load = 200
# object 死亡的***时间, 单位(秒), default: 86400 object_dead_max_time = 86400
# object 清理的时间, 单位(秒), default: 300 object_clear_max_time = 300
#nameserver上出现租约等待时, 阻塞线程***个数, 这个值***是工作线程的一半 max_wait_write_lease = 15
#租约删除的最长时间, 单位(小时), default: 1 lease_expired_time = 3
#***租约超时时间 max_lease_timeout = 3000
#清理租约的阀值, default: 102400 cleanup_lease_threshold = 102400
#创建计划的间隔时间, 单位(秒), default: 30 build_plan_interval = 10
#计划超时时间, 单位(秒), default: 120 run_plan_expire_interval = 120
#创建计划的百分比, 计划数量 = dataserver 数量 * build_plan_ratio build_plan_ratio = 25
#定时dump统计信息的间隔时间, 单位(微秒), default: 60000000 dump_stat_info_interval = 60000000
#创建计划等待时间, 主要用有很多紧急复制时,单位(秒), default: 2 build_plan_default_wait_time = 2
#负载均衡时block相关的个数(这个参数有点问题, 以后会改成百分比), default: 5 balance_max_diff_block_num = 5
#每次新增Block的个数, default: 3 add_primary_block_count = 3
#存储block桶的个数, default: 32 block_chunk_num = 32
#每个任务处理的预期时间, 单位(微秒), default: 200 task_percent_sec_size = 200
#每个任务队列的***size task_max_queue_size = 10000
#同步日志缓冲区slot的大小, 超出这个值会写入磁盘, default: 1 oplog_sync_max_slots_num = 1024
#同步日志线程池的大小, default: 1 oplog_sync_thread_num = 1
———-启动nameserver————– 执行scripts目录下的tfs /usr/local/tfs/scripts/tfs start_ns
查看监听端口:netstat -ltnp
———-停止nameserver————–
/usr/local/tfs/scripts/tfs stop_ns
—————验证—————–
[root@localhost scripts]# netstat -tnlppa |grep 147
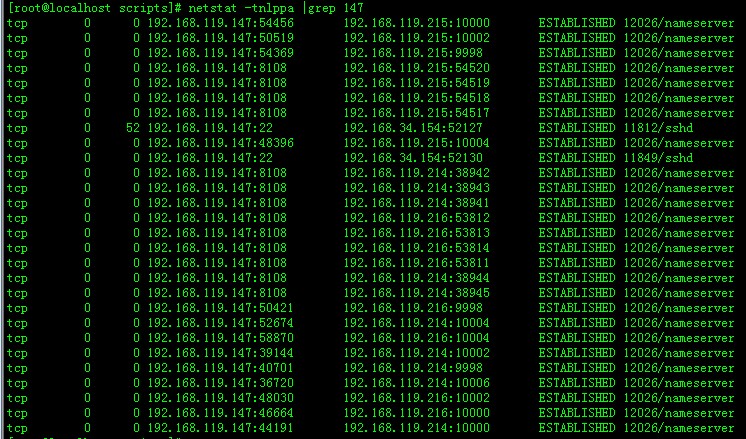
——–列出dataserver的block块———— 首先保证服务已经全部启动! 确认防火墙没有阻止到连接! 查看dataserver连接情况: 在nameserver端执行ssm命令查看检查到的dataserver的一些基本情况。 /usr/local/tfs/bin/ssm -s 192.168.119.147:8108 (要使用主ns的IP与端口,请注意根据实际情况修改) server -b \\随即列出dataserver的block块
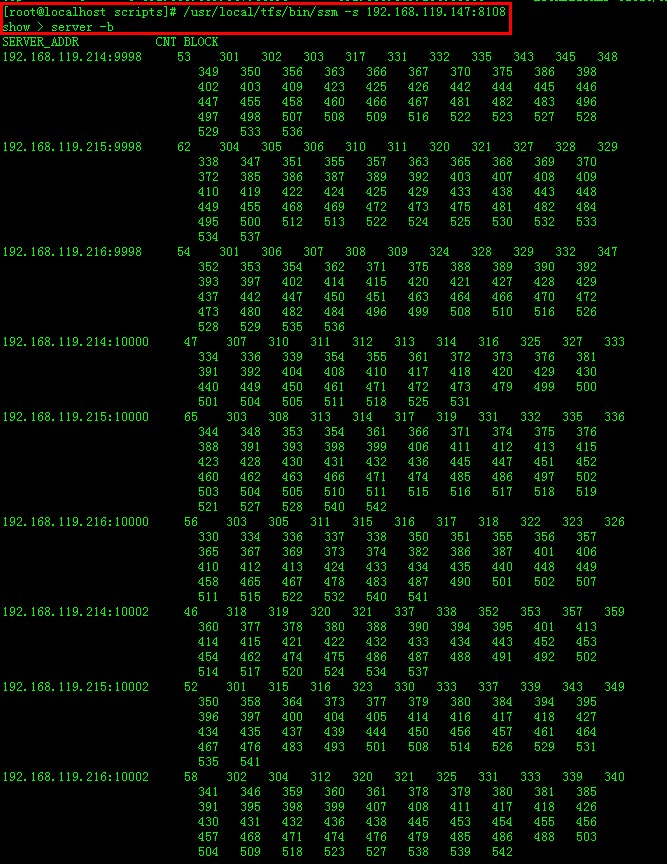
server -w \\随机列出dataserver的可写块
图:略。 machine -a \\列出dataserver的使用报道。

这里需要注意如果用server -b 、-w后面的BLOCK数字,如果是0,说明没有可写块。检测ns ads ds的配置文件,包括备份个数、主块大小知否一致. 如果看到上面的信息,那基本没问题了。
———–用tfstool上传一张图片————- “客户端首先向nameserver发起写请求,nameserver需要根据dataserver上的可写块,容量和负载加权平均来选择一个可写的 block。并且在该block所在的多个dataserver中选择一个作为写入的master,这个选择过程也需要根据dataserver的负载以 及当前作为master的次数来计算,使得每个dataserver作为master的机会均等。master一经选定,除非master宕机,不会更 换,一旦master宕机,需要在剩余的dataserver中选择新的master。返回一个dataserver列表。 客户端向master dataserver开始数据写入操作。master server将数据传输为其他的dataserver节点,只有当所有dataserver节点写入均成功时,master server才会向nameserver和客户端返回操作成功的信息。“
也就是说客户端发起一个请求,nameserver先根据dataserver的 容量和负载 来选择一个dataserver来做为所有dataserver的master(除非master宕机,不会更换,宕机则自动重新选择)然后根据 ns.conf的配置的备份数全部写入,才向nameserver和客户端返回操作成功信息。
/usr/local/tfs/bin/tfstool -s 192.168.119.147:8108 (这是备ns,不是主,还未配置HA呢,使用它的上传失败了) /usr/local/tfs/bin/tfstool -s 192.168.119.145:8108 (这是主ns ,请注意根据实际情况修改)
这里我使用put上传/opt/666.jpg这张图。TFS目前限制了文件大小为2M,适合于一些小于2M数 据的存放。终端默认上传命令put ,超过2M用putl,回车后会返回一大堆字符,注意看***一行是fail还是success,如果是fail,请检测下配置文件、端口等。如果是 success则说明已经上传上去。
上传666.jpg大小 是58407字节
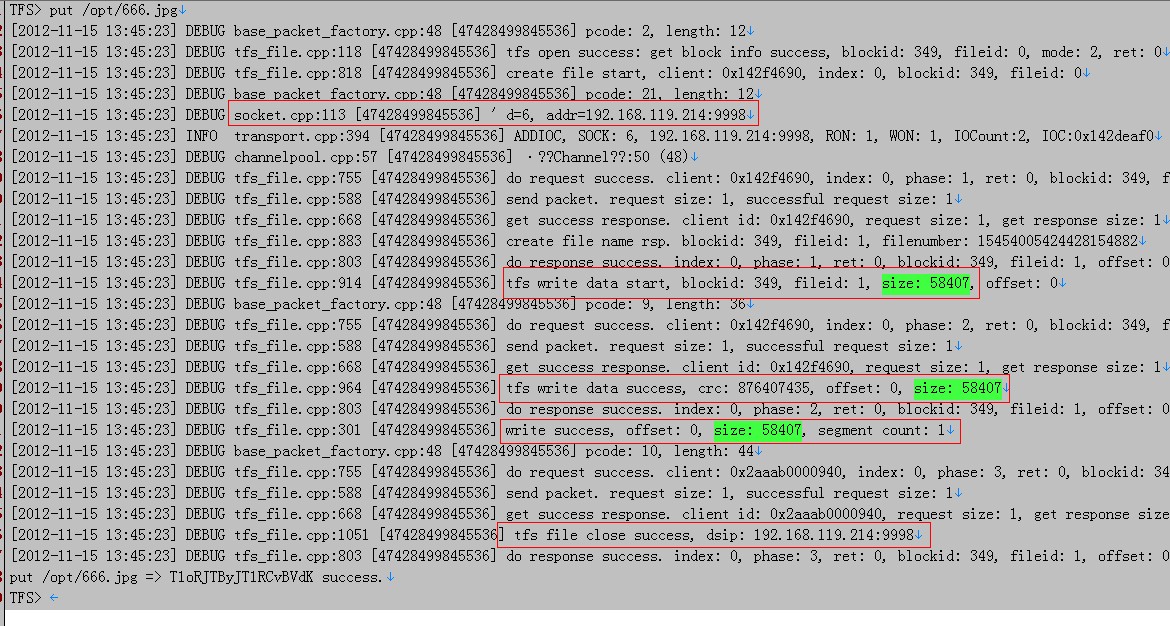
可以看到 blockid=349,size=58407,ip=192.168.119.214:9998
查349这个块的信息。
在ns、ds中随便找一台机器,执行:
/usr/local/tfs/bin/ds_client -d 192.168.119.214:9998
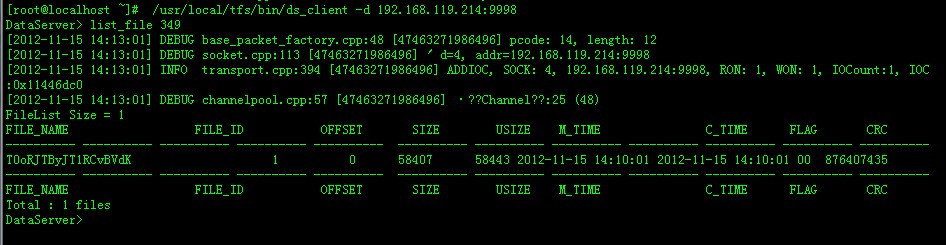
可以看到块349中有一个文件,文件名是:T0oRJTByJT1RCvBVdK
—————–读最文件————————
read_file_data 349 1 /opt/777/jpg

成功了,到 /opt/777/jpg,去看一看文件。














