数据科学是OSEMN(和 awesome 相同发音),它包括获取(Obtaining)、整理(Scrubbing)、探索(Exploring)、建模(Modeling)和翻译(iNterpreting)数据。作为一名数据科学家,我用命令行的时间非常长,尤其是要获取、整理和探索数据的时候。而且我也不是唯一一个这样做的人。最近,Greg Reda介绍了可用于数据科学的经典命令行工具。在这之前,Seth Brown介绍了如何在Unix下进行探索性的数据分析。
下面我将介绍在我的日常工作中发现很有用的七个命令行工具。包括:jq、 json2csv、 csvkit、scrape、 xml2json、 sample 和 Rio。(我自己做的scrape、sample和Rio可以在这里拿到)。任何建议意见、问题甚至git上的拉取请求都非常欢迎(其他人建议的工具可以在***找到)。好的,下面我们首先介绍jq。
1. jq – sed for JSON
JSON现在越来越流行,尤其当API盛行了以后。我还记得处理JSON时,用grep和sed写着丑陋的代码。谢谢jq,终于可以不用写的这么丑了。
假设我们对2008总统大选的所有候选人感兴趣。纽约时报有一个关于竞选财务的API。让我们用curl取一些JSON:
- curl -s 'http://api.nytimes.com/svc/elections/us/v3/finances/2008/president/totals.json?api-key=super-secret' > nyt.json
-s表示静默模式。然后我们用jq最简单的格式jq ‘.’,可以把得到的丑陋的代码:
- {"status":"OK","base_uri":"http://api.nytimes.com/svc/elections/us/v3/finances/2008/","cycle":2008,"copyright":"Copyright (c) 2013 The New York Times Company. All Rights Reserved.","results":[{"candidate_name":"Obama, Barack","name":"Barack Obama","party":"D",
转换成漂亮的格式:
- < nyt.json jq '.' | head { "results": [ { "candidate_id": "P80003338", "date_coverage_from": "2007-01-01", "date_coverage_to": "2008-11-24", "candidate_name": "Obama, Barack", "name": "Barack Obama", "party": "D",
同时,jq还可以选取和过滤JSON数据:
- < nyt.json jq -c '.results[] | {name, party, cash: .cash_on_hand} | select(.cash | tonumber > 1000000)'
- {"cash":"29911984.0","party":"D","name":"Barack Obama"}
- {"cash":"32812513.75","party":"R","name":"John McCain"}
- {"cash":"4428347.5","party":"D","name":"John Edwards"}
更多使用方法参见手册,但是不要指望jq能做所有事。Unix的哲学是写能做一件事并且做得好的程序,但是jq功能强大!下面就来介绍json2csv。
2. json2csv – 把JSON转换成CSV
虽然JSON适合交换数据,但是它不适合很多命令行工具。但是不用担心,用json2csv我们可以轻松把JSON转换成CSV。现在假设我们把数据存在million.json里,仅仅调用
- < million.json json2csv -k name,party,cash
就可以把数据转换成:
- Barack Obama,D,29911984.0
- John McCain,R,32812513.75
- John Edwards,D,4428347.5
有了CSV格式我们就可以用传统的如 cut -d 和 awk -F 一类的工具了。grep和sed没有这样的功能。因为CSV是以表格形式存储的,所以csvkit的作者开发了csvkit。
3. csvkit – 转换和使用CSV的套装
csvkit不只是一个程序,而是一套程序。因为大多数这类工具“期望”CSV数据有一个表头,所以我们在这里加一个。
- echo name,party,cash | cat - million.csv > million-header.csv
我们可以用csvsort给候选人按竞选资金排序并展示:
- < million-header.csv csvsort -rc cash | csvlook
- |---------------+-------+--------------|
- | name | party | cash |
- |---------------+-------+--------------|
- | John McCain | R | 32812513.75 |
- | Barack Obama | D | 29911984.0 |
- | John Edwards | D | 4428347.5 |
- |---------------+-------+--------------|
看起来好像MySQL哈?说到数据库,我们可以把CSV写到sqlite数据库(很多其他的数据库也支持)里,用下列命令:
- csvsql --db sqlite:///myfirst.db --insert million-header.csv
- sqlite3 myfirst.db
- sqlite> .schema million-header
- CREATE TABLE "million-header" (
- name VARCHAR(12) NOT NULL,
- party VARCHAR(1) NOT NULL,
- cash FLOAT NOT NULL
- );
插入后数据都会正确因为CSV里也有格式。此外,这个套装里还有其他有趣工具,如 in2csv、 csvgrep 和csvjoin。通过csvjson,数据甚至可以从csv转换会json。总之,你值得一看。
4. scrape – 用XPath和CSS选择器进行HTML信息提取的工具
JSON虽然很好,但是同时也有很多资源依然需要从HTML中获取。scrape就是一个Python脚本,包含了lxml和cssselect包,从而能选取特定HTML元素。维基百科上有个网页列出了所有国家的边界线语国土面积的比率,下面我们来把比率信息提取出来吧。
- curl -s 'http://en.wikipedia.org/wiki/List_of_countries_and_territories_by_border/area_ratio' | scrape -b -e 'table.wikitable > tr:not(:first-child)' | head
- <!DOCTYPE html>
- <html>
- <body>
- <tr>
- <td>1</td>
- <td>Vatican City</td>
- <td>3.2</td>
- <td>0.44</td>
- <td>7.2727273</td>
- </tr>
-b命令让scrape包含和标签,因为有时xml2json会需要它把HTML转换成JSON。
5. xml2json – 把XML转换成JSON
如名字所说,这工具就是把XML(HTML也是一种XML)转换成JSON的输出格式。因此,xml2json是连接scrape和jq之间的很好的桥梁。
- curl -s 'http://en.wikipedia.org/wiki/List_of_countries_and_territories_by_border/area_ratio' | scrape -be 'table.wikitable > tr:not(:first-child)' | xml2json | jq -c '.html.body.tr[] | {country: .td[1][], border: .td[2][], surface: .td[3][], ratio: .td[4][]}' | head
- {"ratio":"7.2727273","surface":"0.44","border":"3.2","country":"Vatican City"}
- {"ratio":"2.2000000","surface":"2","border":"4.4","country":"Monaco"}
- {"ratio":"0.6393443","surface":"61","border":"39","country":"San Marino"}
- {"ratio":"0.4750000","surface":"160","border":"76","country":"Liechtenstein"}
- {"ratio":"0.3000000","surface":"34","border":"10.2","country":"Sint Maarten (Netherlands)"}
- {"ratio":"0.2570513","surface":"468","border":"120.3","country":"Andorra"}
- {"ratio":"0.2000000","surface":"6","border":"1.2","country":"Gibraltar (United Kingdom)"}
- {"ratio":"0.1888889","surface":"54","border":"10.2","country":"Saint Martin (France)"}
- {"ratio":"0.1388244","surface":"2586","border":"359","country":"Luxembourg"}
- {"ratio":"0.0749196","surface":"6220","border":"466","country":"Palestinian territories"}
当然JSON数据之后可以输入给json2csv。
6. sample – 用来debug
我写的第二个工具是sample。(它是依据bitly的data_hacks写的,bitly还有好多其他工具值得一看。)当你处理大量数据时,debug管道非常尴尬。这时,sample就会很有用。这个工具有三个用处:
- 逐行展示数据的一部分。
- 给在输出时加入一些延时,当你的数据进来的时候有些延时,或者你输出太快看不清楚时用这个很方便。
- 限制程序运行的时间。
下面的例子展现了这三个功能:
|
1
|
seq 10000 | sample -r 20% -d 1000 -s 5 | jq '{number: .}'
|
这表示,每一行有20%的机会被给到jq,没两行之间有1000毫秒的延迟,5秒过后,sample会停止。这些选项都是可选的。为了避免不必要的计算,请尽早sample。当你debug玩之后你就可以把它移除了。
7. Rio – 在处理中加入R
这篇文章没有R就不完整。将R/Rscript加入处理不是很好理解,因为他们并没有标准化输入输出,因此,我加入了一个命令行工具脚本,这样就好理解了。
Rio这样工作:首先,给标准输入的CSV被转移到一个临时文件中,然后让R把它读进df中。之后,在-e中的命令被执行。***,***一个命令的输出被重定向到标准输出中。让我用一行命令展现这三个用法,对每个部分展现5个数字的总结:
- curl -s 'https://raw.github.com/pydata/pandas/master/pandas/tests/data/iris.csv' > iris.csv
- < iris.csv Rio -e 'summary(df)'
- SepalLength SepalWidth PetalLength PetalWidth
- Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
- 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
- Median :5.800 Median :3.000 Median :4.350 Median :1.300
- Mean :5.843 Mean :3.054 Mean :3.759 Mean :1.199
- 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
- Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
- Name
- Length:150
- Class :character
- Mode :character
如果加入了-s选项,sqldf包会被引入,这样CSV格式就会被输出,这可以让你之后用别的工具处理数据。
- < iris.csv Rio -se 'sqldf("select * from df where df.SepalLength > 7.5")' | csvlook
- |--------------+------------+-------------+------------+-----------------|
- | SepalLength | SepalWidth | PetalLength | PetalWidth | Name |
- |--------------+------------+-------------+------------+-----------------|
- | 7.6 | 3 | 6.6 | 2.1 | Iris-virginica |
- | 7.7 | 3.8 | 6.7 | 2.2 | Iris-virginica |
- | 7.7 | 2.6 | 6.9 | 2.3 | Iris-virginica |
- | 7.7 | 2.8 | 6.7 | 2 | Iris-virginica |
- | 7.9 | 3.8 | 6.4 | 2 | Iris-virginica |
- | 7.7 | 3 | 6.1 | 2.3 | Iris-virginica |
- |--------------+------------+-------------+------------+-----------------|
如果你用-g选项,ggplot2会被引用,一个叫g得带有df的ggplot对象会被声明。如果最终输出是个ggplot对象,一个PNG将会被写到标准输出里。
- < iris.csv Rio -ge 'g+geom_point(aes(x=SepalLength,y=SepalWidth,colour=Name))' > iris.png
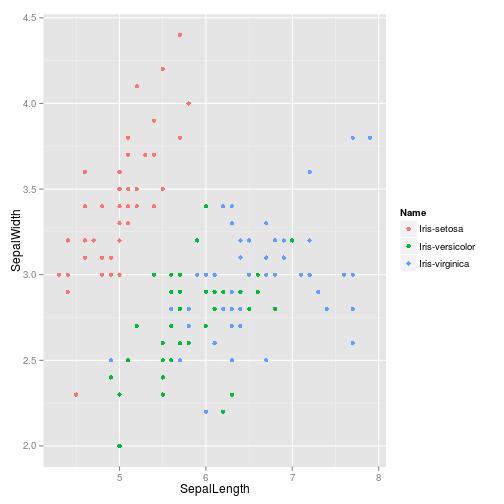
我制作了这个工具,为了可以在命令行中充分利用R的力量。当然它有很多缺陷,但至少我们不需要再学习gnuplot了。
别人建议的命令行工具
下面是其他朋友通过twitter和hacker news推荐的工具,谢谢大家。
- BigMLer by aficionado
- crush-tools by mjn
- csv2sqlite by dergachev
- csvquote by susi22
- data-tools repository by cgrubb
- feedgnuplot by dima55
- Grinder repository by @cgutteridge
- HDF5 Tools by susi22
- littler by @eddelbuettel
- mallet by gibrown
- RecordStream by revertts
- subsample by paulgb
- xls2csv by @sheeshee
- XMLStarlet by gav
结论
我介绍了七个我日常用来处理数据的命令行工具。虽然每个工具各有所长,我经常是将它们与传统工具(如grep, sed, 和awk)一起使用。将小工具结合起来使用组成一个大的流水线,这就是其用处所在。
不知你们对这个列表有什么想法,你们平时喜欢用什么工具呢。如果你们也做了什么好玩的工具,欢迎将其加入数据科学工具包data science toolbox。
如果你不认为自己能制作工具,也不用担心,下次当你写一个异乎寻常的命令行流水线时,记得将它放到一个文件里,加一个#!,加一些参数,改成可执行文件,你就做成一个工具啦~
虽然命令行工具的强大在获取、处理和探索数据时不容小觑,在真正的探索、建模和理解翻译数据时,你还是***在科学计算环境下进行。比如R或者IPython notebook+pandas。
如果感兴趣,欢迎follow me on Twitter。
原文链接: jeroen janssens 翻译: 大飞
译文链接: http://blog.jobbole.com/54308/