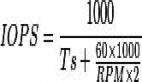Sheepdog是一个分布式对象存储系统,专为虚拟机提供块存储,号称无单点、零配置、可线性扩展(省略更多优点介绍)。本文主要关注其性能究竟如何,测试版本为目前的***稳定版0.7.4。
测试环境
- 节点数量:6个
- 磁盘:各节点都配备7200转SATA硬盘,型号WDC WD10EZEX-22RKKA0,容量为1TB,另外测试节点(即用于启动虚拟客户机的宿主机)多配置一块SSD硬盘,型号INTEL SSDSA2CW300G3,容量为300GB
- 网络:测试节点配备PCI-E双千兆网卡,通过bonding进行负载均衡
- 文件系统:ext4fs,挂载参数:rw,noatime,barrier=0,user_xattr,data=writeback
- sheepdog集群
- 可用空间:6个节点各分配100GB,总共600GB
- 对象副本数量:3个,客户机实际***可用空间为200GB,接近项目规划的容量
- 对象缓存:使用SSD硬盘,分配256GB,可完全缓存客户机文件系统,随测试项目需要挂载或卸载
- 虚拟客户机
- 资源:4GB内存,4个逻辑CPU
- 使用qemu 1.7启动,支持KVM加速、virtio
- 两大测试项目
- IOPS:主要考察较小数据块 随机读和写的能力,测试工具fio(sudo apt-get install fio),测试文件固定为150GB
- 吞吐量:主要考察较大数据块 顺序读或者写的能力,测试工具iozone(sudo apt-get install iozone3),测试文件从64MB倍数递增到4GB,如没有特别说明,测试结果取自操作512MB的数据文件
除特别说明,qemu启动虚拟客户机命令如下:
qemu-system-x86_64 --enable-kvm -m 4096 -smp 4 -drive file=sheepdog:mint,if=virtio,index=0 \ -drive file=sheepdog:data,if=virtio,index=1 -net nic,model=virtio -net user -vnc :1 -daemonize
IOPS测试
测试须知
关于SATA硬盘的IOPS
测试用的普通7200转SATA硬盘,官方公布其平均寻道时间10.5毫秒,所以,根据以下公式,理论上的IOPS值最多只有65。
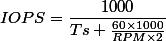
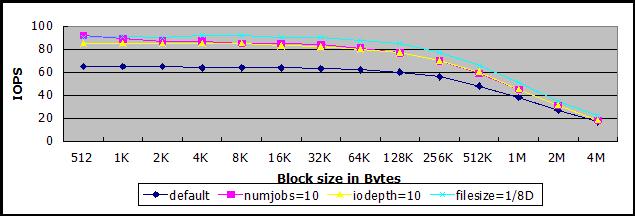
实测结果,在单线程同步IO的情况下(下图深蓝线),也是65,在多任务(紫线)或者使用异步IO(黄线)的情况下,由于操作系统IO调度,IOPS能够达到80到100之间。如果进行读写操作的文件远远小于SATA磁盘大小,缩小了存储单元寻址范围,减少了全磁盘寻道时间,也能提高IOPS,例如,测试文件大小占磁盘大小的1/8的时候,IOPS***在90左右(浅蓝线)。
关于SSD硬盘的IOPS
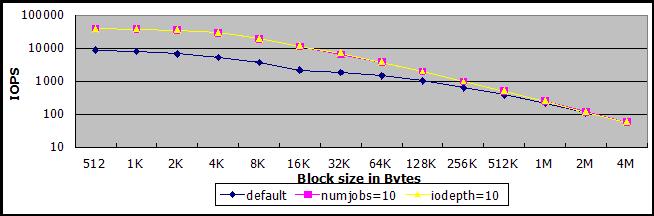
测试用的SSD硬盘,在单线程同步IO的情况下,IOPS最多能够达到9000左右(下图深蓝线),在多任务(紫线)或者异步IO(黄线)的情况下,最多能够达到40000-50000之间。由于构造原理不同于传统磁盘,减小测试文件大小并不能明显提高IOPS。
关于读写比例
由于大多数业务场景既有读操作,也有写操作,而且一般读操作比写操作多很多,因此,读写混合测试项目中的读写比例设定为4:1。一般业务很少有完全随机写的情况,因此不进行只写测试。
关于电梯算法
虚拟的客户机操作系统的IO调度算法使用noop,网上有资料能够提高IOPS,但是实测效果不明显,因此最终报告并没有把它单列出来。
IOPS测试1:不使用对象缓存,只读测试
单线程同步IO的情况下(下图深蓝线),sheepdog的IOPS差不多达到100,比单节点单SATA硬盘高,究其原因:客户机中的测试文件为150GB,共有三个副本,即共占450GB,集群有6个节点,平均每个节点75GB,而各个节点所在磁盘容量为1TB,仅占其1/13,因此,无其它IO任务的情况下,IOPS会比全磁盘随机操作高。
减少客户机的测试文件大小为原来的1/8,即19GB,IOPS能够达到130-140左右,验证了无其它IO任务的情况下,测试文件越小,IOPS越高(浅蓝线)。
恢复客户机的测试文件为150GB,在多任务(线程数量为10,紫线)或者异步IO(队列深度为10,黄线)的情况下,IOPS可达230-250。
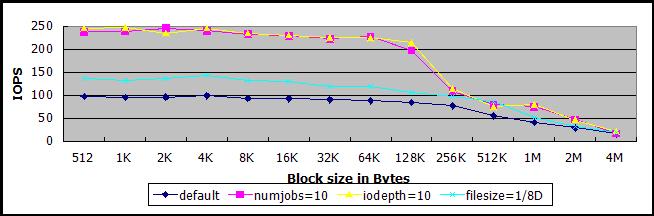
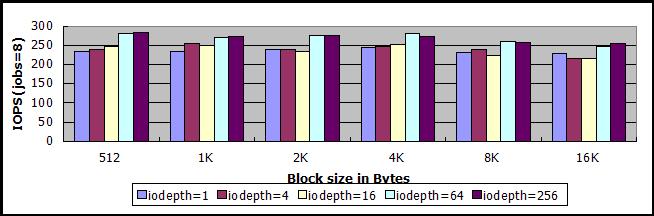
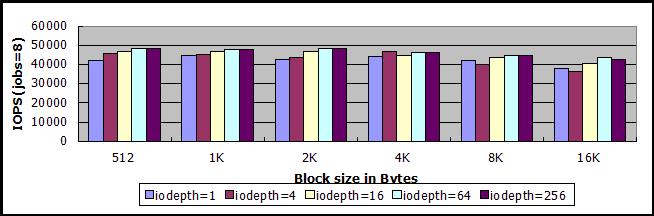
250左右是否该sheepdog集群的极限?进一步换其它numjob和iodepth的组合进行测试,答案是肯定的,测试结果都在250左右,以下是线程数量为8,异步IO队列深度分别为1、4、16、64、256的测试结果,线程数量增加到16,测试数据并没有提高。
IOPS测试2:使用对象缓存,只读测试
单线程同步IO、使用对象缓存且缓存命中率100%的情况下(下图蓝线),sheepdog的IOPS***可达6000,对比相同条件下SSD硬盘的测试结果(***9000),还是有些损耗。
通过多任务(紫线)或者异步IO(黄线)的方式提高并发IO数量,在缓存命中率100%的情况下,IOPS可以提高到40000-50000,基本与相同条件下SSD硬盘的测试结果相当。
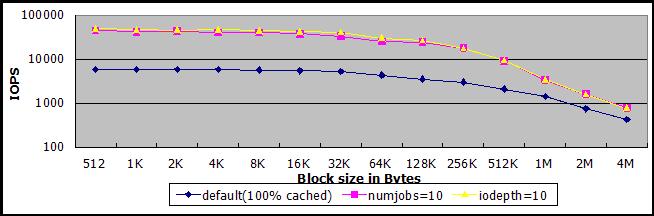
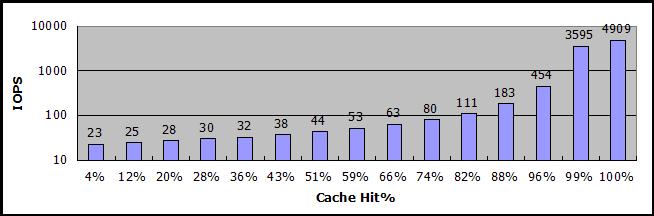
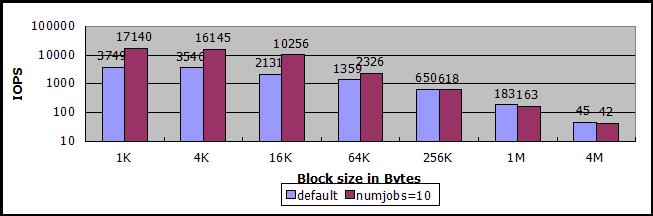
注意上图为对数刻度,且没有数据值,很难比较数值大小,下图省略了一半数据块,但是标上了数据值。
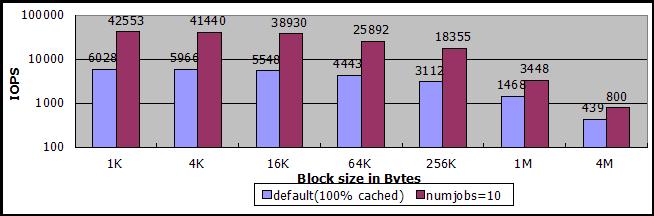
之所以强调缓存命中率,是因为在不完全命中缓存的时候,IOPS下降很厉害,低于80%的话,可能还不如没有对象缓存。下图是sheepdog对象缓存命中率与IOPS的关系图,其中,测试的数据块大小从512B倍数递增到512KB,缓存命中率是在测试过程中,根据sheepdog的cache目录中已有的对象文件数量估算的平均值,IOPS值是读取数据块操作在估算的缓存命中率条件下测量的平均值。
50000是否该sheepdog集群的极限?仿照上面的方法进行测试,答案也是肯定的,测试结果都在50000以内,以下是线程数量为8,异步IO队列深度分别为1、4、16、64、256的测试结果,线程数量增加到16,测试数据并没有提高。
IOPS测试3:不使用对象缓存,读写混合测试
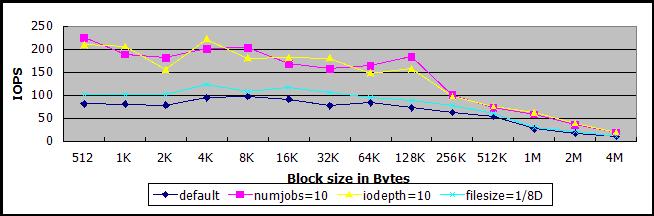
读写混合测试的IOPS比只读测试的结果,总的来说要低一些,而且起伏较大,需要多次测试计算其平均值。
单线程同步IO的情况下(下图深蓝线),能够达到80-100。
减少客户机的测试文件大小为原来的1/8,即19GB,IOPS能够达到100-120(浅蓝线)。
恢复客户机的测试文件为150GB,在多任务(线程数量为10,紫线)或者异步IO(队列深度为10,黄线)的情况下,IOPS大多在180-250之间,但也有时候只到160左右。
IOPS测试4:使用对象缓存,读写混合测试
单线程同步IO、使用对象缓存且缓存命中率100%的情况下,IOPS差不多达到4000。
通过多任务或者异步IO的方式提高并发IO数量,在缓存命中率100%的情况下,IOPS可达10000-20000之间。
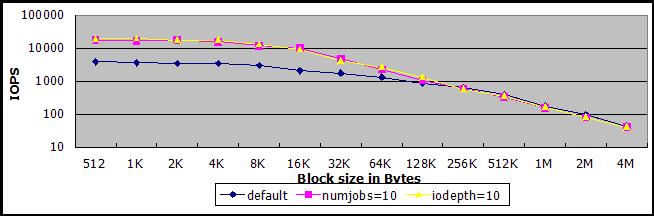
注意上图为对数刻度,且没有数据值,下图省略了一半数据块,但是标上了数据值。可以看到,大数据块读写混合的情况下,多任务或异步IO的IOPS可能还不如单任务同步IO
吞吐量测试
测试须知
关于SATA硬盘的吞吐量
普通7200转SATA硬盘的吞吐量数据,对比一下后面SSD硬盘的吞吐量数据,说明传统磁盘顺序读写的能力还是相当出色的。
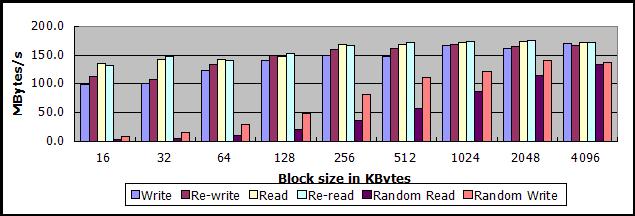
关于SSD硬盘的吞吐量
大数据块(512KB以上)顺序读,吞吐量可达250MB/s-270MB/s,顺序写,吞吐量可达200MB/s-210MB/s。
小数据块(16KB)顺序读,吞吐量也有140MB/s,顺序写大概120MB/s-130MB/s。
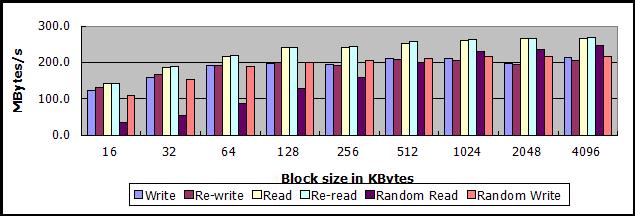
无优化sheepdog的吞吐量
在软硬件不做任何优化的情况下(不绑定双网卡、不使用virtio、以默认参数启动sheepdog),sheepdog的吞吐量数据比较低:
1、顺序写
- 数据块大小为16KB,吞吐量13-14MB/s
- 数据块大小在256KB-4MB之间,吞吐量30-35MB/s
2、顺序读
- 数据块大小为16KB,吞吐量25MB/s左右,如果数据文件大小超过可用内存,降低到20MB/s
- 数据块大小在512KB-4MB之间,吞吐量125-140MB/s,如果数据文件大小超过可用内存,降低到80MB/s以下
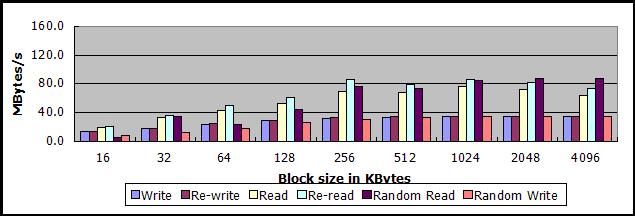
以下两图,上图为数据文件512MB的测试数据,下图为数据文件4GB的测试数据
注,不使用virtio方式启动sheepdog的命令行参数为:
qemu-system-x86_64 --enable-kvm -m 4096 -smp 4 -drive file=sheepdog:mint,index=0 \ -drive file=sheepdog:data,index=1 -vnc :1 -daemonize
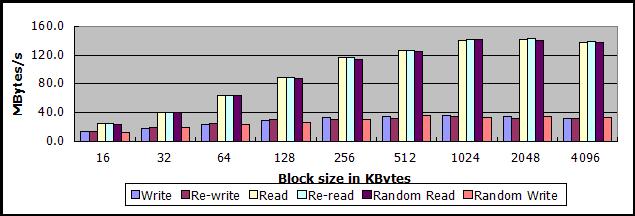
吞吐量测试1:不使用对象缓存
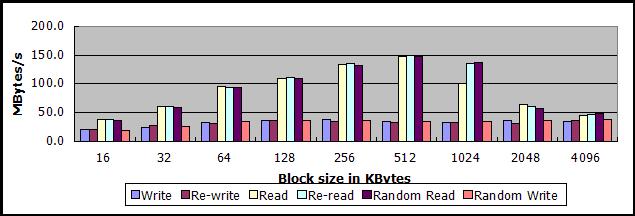
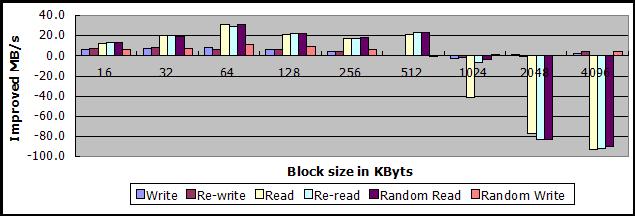
从测试结果看,使用virtio方式启动客户机有利有弊:
1、提高了中小数据块读写操作的吞吐量
- 当数据块大小在16KB-512KB之间时,顺序读的吞吐量提高10MB/s-30MB/s不等
- 当数据块大小在16KB-256KB之间时,顺序写的吞吐量提高5MB/s-8MB/s不等
2、大大降低了超大数据块读操作的吞吐量,至于为何virtio在这种情况下会降低测试的吞吐量,尚不清楚
- 当数据块大小达到2MB或者4MB时,顺序读的吞吐量降低80MB/s-90MB/s
以下两图,上图为512MB下的测试数据,下图为该情况下,与无优化sheepdog读写512MB数据文件两者吞吐量之差。
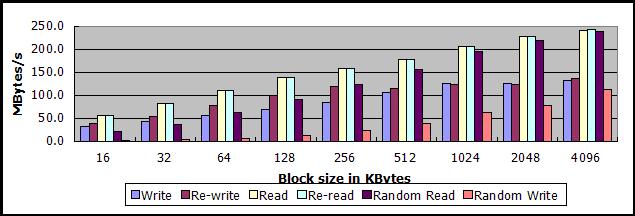
吞吐量测试2:使用对象缓存
使用了对象缓存,顺序读写的吞吐量与数据文件大小没有直接关系,即使数据文件大小超过可用内存。
同时也使用了virtio,并没有因此降低读取大数据块的吞吐量。
由于SSD硬盘的特点,数据块越大,吞吐量越高,在数据块大小为4MB的情况下,顺序读的吞吐量可达240MB/s,顺序写也有130MB/s;如果数据块大小只有16KB,顺序读和顺序写的吞吐量分别只有55MB/s和35MB/s。
总结sheepdog性能

以上为sheepdog集群节点数为6个,且各节点都只挂载一块SATA硬盘的情况下测得的结果,如果增加集群节点数,并且每个节点都挂满硬盘,IOPS应该会更高,而吞吐量取决于缓存和网络带宽,应该不会有明显变化。