阅读 memcached ***有 libevent 基础,memcached 是基于libevent 构建起来的。通由 libevent 提供的事件驱动机制触发 memcached 中的 IO 事件。
个人认为,阅读源码的起初最忌钻牛角尖,如头文件里天花乱坠的结构体到底有什么用。源文件里稀里哗啦的函数是做什么的。刚开始并没必要事无巨细弄清楚头文件每个类型定义的具体用途;很可能那些是不紧要的工具函数,知道他的功能和用法就没他事了。
来看 memcached 内部做了什么事情。memcached 是用 c 语言实现,必须有一个入口函数main(),memcached 的生命从这里开始。
初始化过程
建立并初始化 main_base,即主线程的事件中心,这是 libevent 里面的概念,可以把它理解为事件分发中心。
建立并初始化 memcached 内部容器数据结构。
建立并初始化空闲连接结构体数组。
建立并初始化线程结构数组,指定每个线程的入口函数是worker_libevent(),并创建工作线程。从worder_libevent()的实现来看,工作线程都会调用event_base_loop()进入自己的事件循环。
根据 memcached 配置,开启以下两种服务模式中的一种:
以 UNIX 域套接字的方式接受客户的请求
以 TCP/UDP 套接字的方式接受客户的请求
memcached 有可配置的两种模式: UNIX 域套接字和 TCP/UDP,允许客户端以两种方式向 memcached 发起请求。客户端和服务器在同一个主机上的情况下可以用 UNIX 域套接字,否则可以采用 TCP/UDP 的模式。两种模式是不兼容的。特别的,如果是 UNIX 域套接字或者 TCP 模式,需要建立监听套接字,并在事件中心注册了读事件,回调函数是event_handler(),我们会看到所有的连接都会被注册回调函数是 event_handler()。
调用event_base_loop()开启 libevent 的事件循环。到此,memcached 服务器的工作正式进入了工作。如果遇到致命错误或者客户明令结束 memcached,那么才会进入接下来的清理工作。
UNIX 域套接字和 UDP/TCP 工作模式
在初始化过程中介绍了这两种模式,memcached 这么做为的是让其能更加可配置。TCP/UDP 自不用说,UNIX 域套接字有独特的优势:
在同一台主机上进行通信时,是不同主机间通信的两倍
UNIX 域套接口可以在同一台主机上,不同进程之间传递套接字描述符
UNIX 域套接字可以向服务器提供客户的凭证(用户id或者用户组id)
其他关于 UNIX 域套接字优缺点的请参看: https://pangea.stanford.edu/computing/UNIX/overview/advantages.php
工作线程管理和线程调配方式
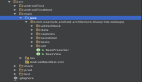
在thread_init(),setup_thread()函数的实现中,memcached 的意图是很清楚的。每个线程都有自己独有的连接队列,即 CQ,注意这个连接队列中的对象并不是一个或者多个 memcached 命令,它对应一个客户! 一旦一个客户交给了一个线程,它的余生就属于这个线程了! 线程只要被唤醒就立即进入工作状态,将自己 CQ 队列的任务所有完完成。当然,每一个工作线程都有自己的 libevent 事件中心。
很关键的线索是thread_init()的实现中,每个工作线程都创建了读写管道,所能给我们的提示是: 只要利用 libevent 在工作线程的事件中心注册读管道的读事件,就可以按需唤醒线程,完成工作,很有意思,而setup_thread()的工作正是读管道的读事件被注册到线 程的事件中心,回调函数是thread_libevent_process().thread_libevent_process()的工作就是从工作线 程自己的 CQ 队列中取出任务执行,而往工作线程工作队列中添加任务的是dispatch_conn_new(),此函数一般由主线程调用。下面是主线程和工作线程的工 作流程:
前几天在微博上,看到 @高端小混混 的微博,转发了:
“多任务并行处理的两种方式,一种是将所有的任务用队列存储起来,每个工作者依次去 拿一个来处理,直到做完所有的>任务为止。另一种是将任务平均分给工作者,先做完任务的工作者就去别的工作者那里拿一些任务来做,同样直到所有任务 做完为止。两种方式的结果如何?根据自己的场景写码验证。”
memcached 所采用的模式就是这里所说的第二种! memcached 的线程分配模式是:一个主线程和多个工作线程。主线程负责初始化和将接收的请求分派给工作线程,工作线程负责接收客户的命令请求和回复客户。
#p#
存储容器
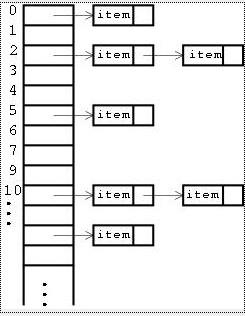
memcached 是做缓存用的,内部肯定有一个容器。回到main()中,调用assoc_init()初始化了容器–hashtable,采用头插法插入新数据,因为头 插法是最快的。memcached 只做了一级的索引,即 hash; 接下来的就靠 memcmp() 在链表中找数据所在的位置。memcached 容器管理的接口主要在 item.h .c 中.
连接管理
每个连接都会建立一个连接结构体与之对应。main()中会调用conn_init()建立连接结构体数组。连接结构体 struct conn 记录了连接套接字,读取的数据,将要写入的数据,libevent event 结构体以及所属的线程信息。
当有新的连接时,主线程会被唤醒,主线程选定一个工作线程 thread0,在 thread0 的写管道中写入数据,特别的如果是接受新的连接而不是接受新的数据,写入管道的数据是字符 ‘c’。工作线程因管道中有数据可读被唤醒,thread_libevent_process()被调用,新连接套接字被注册了 event_handler()回调函数,这些工作在conn_new()中完成。因此,客户端有命令请求的时候(譬如发起 get key 命令),工作线程都会被触发调用event_handler()。
当出现致命错误或者客户命令结束服务(quit 命令),关于此连接的结构体内部的数据会被释放(譬如曾经读取的数据),但结构体本身不释放,等待下一次使用。如果有需要,连接结构体数组会指数自增。
一个请求的工作流程
memcached 服务一个客户的时候,是怎么一个过程,试着去调试模拟一下。当一个客户向 memcached 发起请求时,主线程会被唤醒,接受请求。接下来的工作在连接管理中有说到。
客户已经与 memcached 服务器建立了连接,客户在终端(黑框框)敲击 get key + 回车键,一个请求包就发出去了。从连接管理中已经了解到所有连接套接字都会被注册回调函数为event_handler(),因此 event_handler()会被触发调用。
- void event_handler(const int fd,const short which,void *arg) {
- conn *c;
- c = (conn *)arg;
- assert(c != NULL);
- c->whichwhich = which;
- /* sanity */
- if (fd != c->sfd) {
- if (settings.verbose > 0)
- fprintf(stderr,"Catastrophic: event fd doesn't match conn fd!\n");
- conn_close(c);
- return;
- }
- drive_machine(c);
- /* wait for next event */
- return;
- }
event_handler()调用了drive_machine().drive_machine()是请求处理的开端,特别的当有新的连接 时,listen socket 也是有请求的,所以建立新的连接也会调用drive_machine(),这在连接管理有提到过。下面是drive_machine()函数的骨架:
- // 请求的开端。当有新的连接的时候 event_handler() 会调用此函数。
- static void drive_machine(conn *c) {
- bool stop = false;
- int sfd,flags = 1;
- socklen_t addrlen;
- struct sockaddr_storage addr;
- int nreqs = settings.reqs_per_event;
- int res;
- const char *str;
- assert(c != NULL);
- while (!stop) {
- // while 能保证一个命令被执行完成或者异常中断(譬如 IO 操作次数超出了一定的限制)
- switch(c->state) {
- // 正在连接,还没有 accept
- case conn_listening:
- // 等待新的命令请求
- case conn_waiting:
- // 读取数据
- case conn_read:
- // 尝试解析命令
- case conn_parse_cmd :
- // 新的命令请求,只是负责转变 conn 的状态
- case conn_new_cmd:
- // 真正执行命令的地方
- case conn_nread:
- // 读取所有的数据,抛弃!!! 一般出错的情况下会转换到此状态
- case conn_swallow:
- // 数据回复
- case conn_write:
- case conn_mwrite:
- // 连接结束。一般出错或者客户显示结束服务的情况下回转换到此状态
- case conn_closing:
- }
- }
- return;
- }
通过修改连接结构体状态 struct conn.state 执行相应的操作,从而完成一个请求,完成后 stop 会被设置为 true,一个命令只有执行结束(无论结果如何)才会跳出这个循环。我们看到 struct conn 有好多种状态,一个正常执行的命令状态的转换是:
- conn_new_cmd->conn_waiting->conn_read->conn_parse_cmd->conn_nread->conn_mwrite->conn_close
这个过程任何一个环节出了问题都会导致状态转变为 conn_close。带着刚开始的问题把从客户连接到一个命令执行结束的过程是怎么样的:
客户connect()后,memcached 服务器主线程被唤醒,接下来的调用链是event_handler()->drive_machine()被调用,此时主线程对应 conn 状态为 conn_listining,接受请求
- dispatch_conn_new(sfd,conn_new_cmd,EV_READ | EV_PERSIST,DATA_BUFFER_SIZE,tcp_transport);
dispatch_conn_new()的工作是往工作线程工作队列中添加任务(前面已经提到过),所以其中一个沉睡的工作线程会被唤醒,thread_libevent_process()会被工作线程调用,注意这些机制都是由 libevent 提供的。
thread_libevent_process()调用conn_new()新建 struct conn 结构体,且状态为 conn_new_cmd,其对应的就是刚才accept()的连接套接字.conn_new()最关键的任务是将刚才接受的套接字在 libevent 中注册一个事件,回调函数是event_handler()。循环继续,状态 conn_new_cmd 下的操作只是只是将 conn 的状态转换为 conn_waiting;
循环继续,conn_waiting 状态下的操作只是将 conn 状态转换为 conn_read,循环退出。
此后,如果客户端不请求服务,那么主线程和工作线程都会沉睡,注意这些机制都是由 libevent 提供的。
客户敲击命令「get key」后,工作线程会被唤醒,event_handler()被调用了。看! 又被调用了.event_handler()->drive_machine(),此时 conn 的状态为 conn_read。conn_read 下的操作就是读数据了,如果读取成功,conn 状态被转换为 conn_parse_cmd。
循环继续,conn_parse_cmd 状态下的操作就是尝试解析命令: 可能是较为简单的命令,就直接回复,状态转换为 conn_close,循环接下去就结束了; 涉及存取操作的请求会导致 conn_parse_cmd 状态转换为 conn_nread。
循环继续,conn_nread 状态下的操作是真正执行存取命令的地方。里面的操作无非是在内存寻找数据项,返回数据。所以接下来的状态 conn_mwrite,它的操作是为客户端回复数据。
状态又回到了 conn_new_cmd 迎接新的请求,直到客户命令结束服务或者发生致命错误。大概就是这么个过程。
#p#
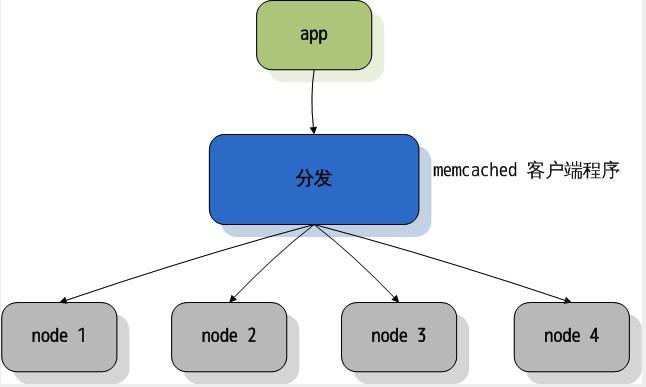
memcached 的分布式
memcached 的服务器没有向其他 memcached 服务器收发数据的功能,意即就算部署多个 memcached 服务器,他们之间也没有任何的通信。memcached 所谓的分布式部署也是并非平时所说的分布式。所说的「分布式」是通过创建多个 memcached 服务器节点,在客户端添加缓存请求分发器来实现的。memcached 的更多的时候限制是来自网络 I/O,所以应该尽量减少网络 I/O。
我在 github 上分享了 memcached 的源码剖析注释: 这里