在本系列教程中,将带大家动手探究Java内存泄露之谜,并教授给读者相关的分析方法。以下是一个案例。
最近有一个服务器,经常运行的时候就出现过载宕机的现象。重启脚本和系统后,该个问题还是会出现。尽管有大量的数据丢失,但因不是关键业务,问题并不严重。不过还是决定作进一步的调查,来看下问题到底出现在哪。首先注意到的是,服务器通过了所有的单元测试和完整的集成环境的测试。在测试环境下使用测试数据时运行正常,那么为什么在生产环境中运行会出现问题呢?很容易会想到,也许是因为实际运行时的负载大于测试时的负载,甚至超过了设计的负荷,从而耗尽了资源。但是到底是什么资源,在哪里耗尽了呢?下面我们就研究这个问题
为了演示这个问题,首先要做的是编写一些内存泄露的代码,将使用生产-消费者模式去实现,以便更好说明问题。
例子中,假定有这样一个场景:假设你为一个证劵经纪公司工作,这个公司将股票的销售额和股份记录在数据库中。通过一个简单进程获取命令并将其存放在一个队列中。另一个进程从该队列中读取命令并将其写入数据库。命令的POJO对象十分简单,如下代码所示:
- public class Order {
- private final int id;
- private final String code;
- private final int amount;
- private final double price;
- private final long time;
- private final long[] padding;
- /**
- * @param id
- * The order id
- * @param code
- * The stock code
- * @param amount
- * the number of shares
- * @param price
- * the price of the share
- * @param time
- * the transaction time
- */
- public Order(int id, String code, int amount, double price, long time) {
- super();
- this.id = id;
- this.code = code;
- this.amount = amount;
- this.price = price;
- this.time = time;
- //这里故意设置Order对象足够大,以方便例子稍后在运行的时候耗尽内存
- this.padding = new long[3000];
- Arrays.fill(padding, 0, padding.length - 1, -2);
- }
- public int getId() {
- return id;
- }
- public String getCode() {
- return code;
- }
- public int getAmount() {
- return amount;
- }
- public double getPrice() {
- return price;
- }
- public long getTime() {
- return time;
- }
- }
这个POJO对象是Spring应用的一部分,该应用有三个主要的抽象类,当Spring调用它们的start()方法的时候将分别创建一个新的线程。
第一个抽象类是OrderFeed。run()方法将生成一系列随机的Order对象,并将其放置在队列中,然后它会睡眠一会儿,又再接着生成一个新的Order对象,代码如下:
- public class OrderFeed implements Runnable {
- private static Random rand = new Random();
- private static int id = 0;
- private final BlockingQueue<Order> orderQueue;
- public OrderFeed(BlockingQueue<Order> orderQueue) {
- this.orderQueue = orderQueue;
- }
- /**
- *在加载Context上下文后由Spring调用,开始生产order对象
- */
- public void start() {
- Thread thread = new Thread(this, "Order producer");
- thread.start();
- }
- @Override
- public void run() {
- while (true) {
- Order order = createOrder();
- orderQueue.add(order);
- sleep();
- }
- }
- private Order createOrder() {
- final String[] stocks = { "BLND.L", "DGE.L", "MKS.L", "PSON.L", "RIO.L", "PRU.L",
- "LSE.L", "WMH.L" };
- int next = rand.nextInt(stocks.length);
- long now = System.currentTimeMillis();
- Order order = new Order(++id, stocks[next], next * 100, next * 10, now);
- return order;
- }
- private void sleep() {
- try {
- TimeUnit.MILLISECONDS.sleep(100);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
#p#
第二个类是OrderRecord,这个类负责从队列中提取Order对象,并将它们写入数据库。问题是,将Order对象写入数据库的耗时比产生Order对象的耗时要长得多。为了演示,将在recordOrder()方法中让其睡眠1秒。
- public class OrderRecord implements Runnable {
- private final BlockingQueue<Order> orderQueue;
- public OrderRecord(BlockingQueue<Order> orderQueue) {
- this.orderQueue = orderQueue;
- }
- public void start() {
- Thread thread = new Thread(this, "Order Recorder");
- thread.start();
- }
- @Override
- public void run() {
- while (true) {
- try {
- Order order = orderQueue.take();
- recordOrder(order);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- /**
- * 模拟记录到数据库的方法,这里只是简单让其睡眠一秒
- */
- public void recordOrder(Order order) throws InterruptedException {
- TimeUnit.SECONDS.sleep(1);
- }
- }
为了证明这个效果,特意增加了一个监视类 OrderQueueMonitor ,这个类每隔几秒就打印出队列的大小,代码如下:
- public class OrderQueueMonitor implements Runnable {
- private final BlockingQueue<Order> orderQueue;
- public OrderQueueMonitor(BlockingQueue<Order> orderQueue) {
- this.orderQueue = orderQueue;
- }
- public void start() {
- Thread thread = new Thread(this, "Order Queue Monitor");
- thread.start();
- }
- @Override
- public void run() {
- while (true) {
- try {
- TimeUnit.SECONDS.sleep(2);
- int size = orderQueue.size();
- System.out.println("Queue size is:" + size);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
接下来配置Spring框架的相关配置文件如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <beans xmlns="http://www.springframework.org/schema/beans"
- xmlns:p="http://www.springframework.org/schema/p"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xmlns:context="http://www.springframework.org/schema/context"
- xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
- http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.1.xsd"
- default-init-method="start"
- default-destroy-method="destroy">
- <bean id="theQueue" class="java.util.concurrent.LinkedBlockingQueue"/>
- <bean id="orderProducer">
- <constructor-arg ref="theQueue"/>
- </bean>
- <bean id="OrderRecorder">
- <constructor-arg ref="theQueue"/>
- </bean>
- <bean id="QueueMonitor">
- <constructor-arg ref="theQueue"/>
- </bean>
- </beans>
接下来运行这个Spring应用,并且可以通过jConsole去监控应用的内存情况,这需要作一些配置,配置如下:
- -Dcom.sun.management.jmxremote
- -Dcom.sun.management.jmxremote.port=9010
- -Dcom.sun.management.jmxremote.local.only=false
- -Dcom.sun.management.jmxremote.authenticate=false
- -Dcom.sun.management.jmxremote.ssl=false
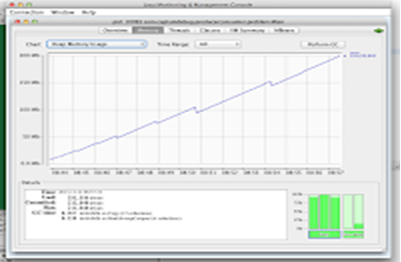
如果你看看堆的使用量,你会发现随着队列的增大,堆的使用量逐渐增大,如下图所示,你可能不会发现1KB的内存泄露,但当达到1GB的内存溢出就很明显了。所以,接下来要做的事情就是等待其溢出,然后进行分析。
#p#
接下来我们来看下如何发现并解决这类问题。在Java中,可以借助不少自带的或第三方的工具帮助我们进行相关的分析。
下面介绍分析程序内存泄露问题的三个步骤:
- 提取发生内存泄露的服务器的转储文件。
- 用这个转储文件生成报告。
- 分析生成的报告。
有几个工具能帮你生成堆转储文件,分别是:
- jconsole
- visualvm
- Eclipse Memory Analyser Tool(MAT)
用jconsole提取堆转储文件
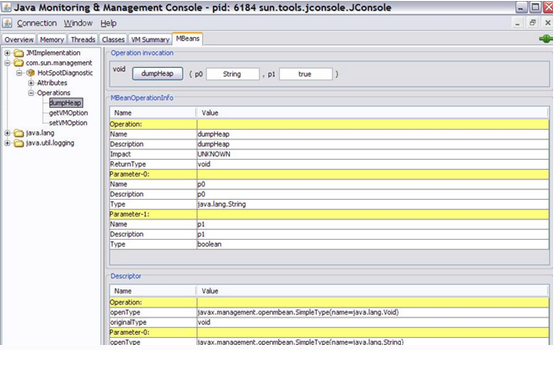
使用jconsole连接到你的应用:单击MBeans选项卡打开com.sun.management包,点击HotSpotDiagnostic,点击Operations,然后选择dumpHeap。这时你将会看到dumpHeap操作:它接受两个参数p0和p1。在p0的编辑框内输入一个堆转储的文件名,然后按下DumpHeap按钮就可以了。如下图:
用jvisualvm提取堆转储文件
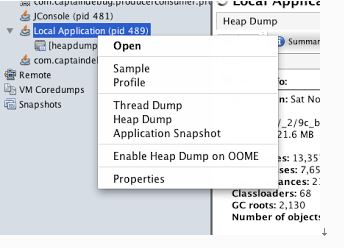
首先使用jvisual vm连接示例代码,然后右键点击应用,在左侧的“application”窗格中选择“Heap Dump”。
注意:如果需要分析的发生内存泄露的是在远程服务器上,那么jvisualvm将会把转存出来的文件保存在远程机器(假设这是一台unix机器)上的/tmp目录下。
用MAT来提取堆转储文件
jconsole和jvisualvm本身就是JDK的一部分,而MAT或被称作“内存分析工具”,是一个基于eclipse的插件,可以从eclipse.org下载。
最新版本的MAT需要你在电脑上安装JDk1.6。如果你用的是Java1.7版本也不用担心,因为它会自动为你安装1.6版本,并且不会和安装好的1.7版本产生冲突。
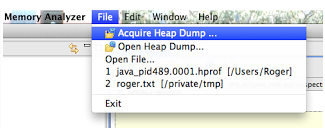
使用MAT的时候,只需要点击“Aquire Heap Dump”,然后按步骤操作就可以了,如下图:
要注意的是,使用上面的三种方法,都需要配置远程JMX连接如下:
- -Dcom.sun.management.jmxremote
- -Dcom.sun.management.jmxremote.port=9010
- -Dcom.sun.management.jmxremote.local.only=false
- -Dcom.sun.management.jmxremote.authenticate=false
- -Dcom.sun.management.jmxremote.ssl=false
何时提取堆转存文件
那么在什么时候才应该提取堆转存文件呢?这需要耗费点心思和碰下运气。如果过早提取了堆转储文件,那么将可能不能发现问题症结所在,因为它们被合法,非泄露类的实例屏蔽了。不过也不能等太久,因为提取堆转储文件也需要占用内存,进行提取的时候可能会导致应用崩溃。
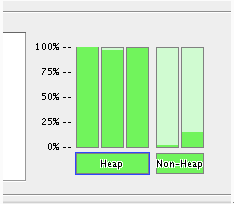
最好的办法是将jconsole连接到应用程序并监控堆的占用情况,知道它何时在崩溃的边缘。因为没有发生内存泄露时,三个堆部分指标都是绿色的,这样很容易就能监控到,如下图:
分析转储文件
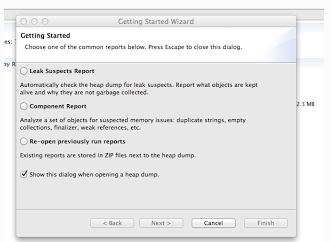
现在轮到MAT派上用场了,因为它本身就是设计用来分析堆转储文件的。要打开和分析一个堆转储文件,可以选择File菜单的Heap Dump选项。选择了要打开的文件后,将会看到如下三个选项:
#p#
选择Leak Suspect Report选项。在MAT运行几秒后,会生成如下图的页面:
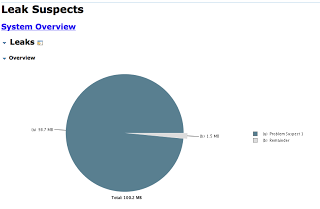
如饼状图显示:疑似有一处发生了内存泄露。也许你会想,这样的做法只有在代码受到控制的情况下才可取。毕竟这只是个例子,这又能说明什么呢?好吧,在这个例子里,所有的问题都是浅然易见的;线程a占用了98.7MB内存,其他线程用了1.5MB。在实际情况中,得到的图表可能是上图那样。让我们继续探究,会得到如下图:
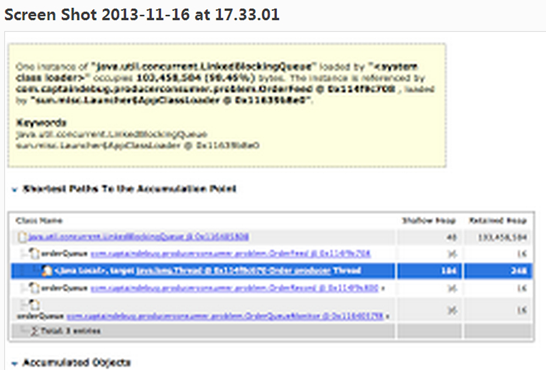
如上图所示,报告的下一部分告诉我们,有一个LinkedBlockQueue占用了98.46%的内存。想要进一步的探究,点击Details>>就可以了,如下图:
可以看到,问题确实是出在我们的orderQueue上。这个队列里存储了所有生成的随机生成的Order对象,并且可以被我们上篇博文里提到的三个线程OrderFeed、OrderRecord、OrderMonitor访问。
那么一切都清楚了,MAT告诉我们:示例代码中有一个LinkedBlockQueue,这个队列用尽了所有的内存,从而导致了严重的问题。不过我们不知道这个问题为什么会产生,也不能指望MAT告诉我们。
本文代码可以在:https://github.com/roghughe/captaindebug/tree/master/producer-consumer中下载。
原文链接:http://www.javacodegeeks.com/2013/12/investigating-memory-leaks-part-1-writing-leaky-code.html