很多人觉得机器学习高不可攀,认为这是一门只有少数专业学者才了解的神秘技术。
毕竟,你是在让运行在二进制世界里的机器得出它自己对现实世界的认识。你正在教它们如何思考。然而,本文几乎不是你所认为的晦涩难懂、复杂而充满数 学公式的文章。正如所有帮助我们认识世界的基本常识一样(例如:牛顿运动定律、工作需要去完成、供需关系等等),机器学习***的方法和概念也应该是简洁明 了的。可惜的是,绝大多数关于机器学习的文献都充斥着复杂难懂的符号、艰涩晦暗的数学公式和不必要的废话。正是这给机器学习简单基础的思想围上了一堵厚厚 的墙。
现在看一个实际的例子,我们需要在一篇文章的末尾增加一个“你可能喜欢”的推荐功能,那么我们该如何实现呢?

为了实现这个想法,我们有一个简单的解决方案:
- 1.获得当前文章的标题并将其分割成独立的单词(译者注:原文是英文,只需要依据空格分割即可,中文分词需要用到分词器)
- 2.获取除当前文章以外的所有文章
- 3.将这些文章依据其内容与当前文章标题的重合程度进行排序
- def similar_posts(post)
- title_keywords = post.title.split(' ')
- Post.all.to_a.sort |post1, post2|
- post1post1_title_intersection = post1.body.split(' ') & title_keywords
- post2post2_title_intersection = post2.body.split(' ') & title_keywords
- post2_title_intersection.length <=> post1_title_intersection.length
- end[0..9]
- end
采用这种方法去找出与博文“支持团队如何提高产品质量”相似的文章,我们由此得到下列相关度前十的文章:
- 如何着手实施一个经过验证的方案
- 了解你的客户是如何做决策的
- 设计***运行界面以取悦你的用户
- 如何招聘设计师
- 图标设计的探讨
- 对歌手Ryan的采访
- 通过内部交流对客户进行积极支持
- 为什么成为***并不重要
- 对Joshua Porter的采访
- 客户留存、群组分析与可视化
正如你所看到的,标杆文章是关于如何有效率地进行团队支持,而这与客户群组分析、讨论设计的优点都没有太大的关系,其实我们还可以采取更好的方法。
现在,我们尝试用一种真正意义上的机器学习方法来解决这个问题。分两步进行:
- 将文章用数学的形式表示;
- 用K均值(K-means)聚类算法对上述数据点进行聚类分析。
1.将文章用数学的形式表示
如果我们可以将文章以数学的形式展示,那么可以根据文章之前的相似程度作图,并识别出不同簇群:

如上图所示,将每篇文章映射成坐标系上的一个坐标点并不难,可以通过如下两步实现:
- 找出每篇文章中的所有单词;
- 为每篇文章建立一个数组,数组中的元素为0或者1,用于表示某单词在该文章中是否出现了,每篇文章数组元素的顺序都是一样的,只是其值有差异。
Ruby代码如下:
- @posts = Post.all
- @words = @posts.map do |p|
- p.body.split(' ')
- end.flatten.uniq
- @vectors = @posts.map do |p|
- @words.map do |w|
- p.body.include?(w) ? 1 : 0
- end
- end
假设@words 的值为:
[“你好”,”内部”,”内部交流”,”读者”,”博客”,”发布”]
如果某篇文章的内容是“你好 博客 发布 读者”,那么其对应的数组即为:
[1,0,0,1,1,1]
当然,我们现在没法使用简单的工具像二维坐标系一样展示这个六维度的坐标点,但是这其中涉及的基本概念,例如两点之间的距离都是互通的,可以通过二维推广到更高维度(因此使用二维的例子来说明问题还是行得通的)。
#p#
2.用K均值(K-means)聚类算法对数据点进行聚类分析
现在我们得到了一系列文章的坐标,可以尝试找出相似文章的群簇。这里我们采用使用一个相当简单聚类算法-K均值算法,概括起来有五个步骤:
- 设定一个数K,它表示群簇中对象的数目;
- 从所有数据对象中随机选择K个对象作为初始的K个群簇中心;
- 遍历所有对象,分别将它们指派到离自己最近的一个群簇中;
- 更新群簇中心,即计算每个群簇中对象的均值,并将均值作为该群簇的新中心;
- 重复3、4步骤,直到每个群簇中心不再变化。
我们接下来用图的形式形象化地展示这些步骤。首先我们从一系列文章坐标中随机选择两个点(K=2):

我们将每篇文章指派到离它最近的群簇中:

我们计算各个群簇中所有对象的坐标均值,作为该群簇新的中心。
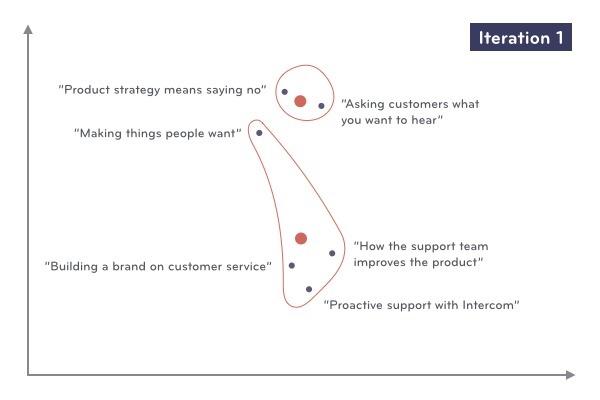
这样我们就完成了***次的数据迭代,现在我们将文章根据新的群簇中心重新指派到对应的群簇中去。
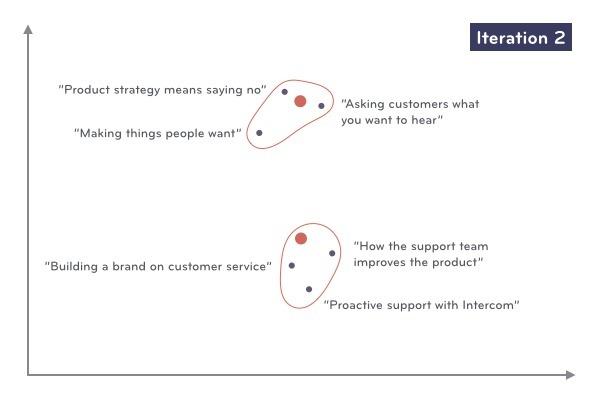
至此,我们找到了每篇文章对应的群簇!很明显,即使继续进行迭代群簇中心不会改变,每篇文章对应的群簇也不会改变了。
上述过程的Ruby代码如下:
- @cluster_centers = [rand_point(), rand_point()]
- 15.times do
- @clusters = [[], []]
- @posts.each do |post|
- min_distance, min_point = nil, nil
- @cluster_centers.each.with_index do |center, i|
- if distance(center, post) < min_distance
- min_distance = distance(center, post)
- min_point = i
- end
- end
- @clusters[min_point] << post
- end
- @cluster_centers = @clusters.map do |post|
- average(posts)
- end
- end
下面是由这个方法得到的与博文“支持团队如何提高产品质量”相似性排在前十位的文章:
- 你对此更了解了还是你更聪明了
- 客户反馈的三个准则
- 从客户获取你所要的信息
- 产品交付只是一个开始
- 你觉得功能扩展看起来像什么
- 了解你的用户群
- 在正确的信息和正确的时间下转换客户
- 与你的客户沟通
- 你的应用有消息推送安排吗
- 你有试着与客户沟通吗
- 结果不言自明。
- 我们仅仅用了不到40行的代码以及简单的算法介绍就实现了这个想法,然而如果你看学术论文你永远不会知道这本该有多简单。下面是一篇介绍K均值算法论文的摘要(并不知道K均值算法是谁提出的,但这是***提出“K均值”这个术语的文章)。

如果你喜欢以数学符号去表达思想,毫无疑问学术论文是很有用处的。然而,其实有更多优质的资源可以替换掉这些繁杂数学公式,它们更实际、更平易近人。
- Wiki百科(例如:潜在语义索引,聚类分析)
- 开源机器学习库的源代码(例如: Scipy’s K-Means,Scikit’s DBSCAN)
- 以程序员的角度编写的书籍(例如:集体智慧编程,黑客机器学习)
- 可汗学院
试一试
如何为你的项目管理应用推荐标签?如何设计你的客户支持工具?或者是社交网络中用户如何分组?这些都可以通过简答的代码、简单的算法来实现,是练习的好机会!所以,如果你认为项目中面临的问题可以通过机器学习来解决,那为什么还要犹豫呢?
机器学习其实比你想象得更简单!