












在去年的软件开发2.0技术大会上,我讲了一个支持动态负载均衡的多核查找设计方法。基本思想是采用数据结构分拆的方法,使用了多级的数据结构设计。下面先简要介绍一下这种多级数据结构的设计思路,然后给出一个采用数组顺序查找作为查找表实现的多级数据结构类CDHashArray。
在CDHashArray中,对数组的插入和删除都是顺序化的操作,查找也是近似于顺序化的操作,看起来似乎会很慢。实际上对于小数组,比如只有几个或十来个数组,其效率并不慢,这使得以前在单核时代无法用于大型查找的数组顺序查找,在多核时代却可以得到很好应用前景。
二级查找结构基本思想
要了解多级数据结构设计,首先得知道基本的二级查找数据结构设计思想。
二级查找结构就是在第1级查找时找到二级子表的位置,然后在找到的二级子表中进行第二次查找来找到对应的目标数据。
典型的二级查找结构示意图如下:
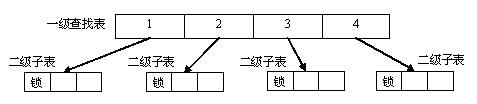
图 16.2.1: 二级查找结构示意图
二级查找结构由一级查找表和二级子表构成,一个查找表中的每个节点指向一个二级查找子表。查找时,先将关键词映射成一级查找表的位置,然后将对应位置的二级子表取出,在子表中找到对应的查找目标数据。
Intel Threading Building Blocks(TBB)开源项目中,其中的concurrent_hash_map使用的就是一种最简单的二级查找结构。它使用了哈希表式的数据结构,并给哈希表的每个桶设一把锁。
对于普通的查找,这种简单的二级查找结构也许够用了,但是对于一些大型的查找,这种简单的二级查找结构并不能满足。首先的问题是如果子表数量过多,则锁的数量也非常多,锁本身需要占用大量的内存开销。
如 果子表数量过少,那么又会引起另外一个重要的问题,那就是负载平衡问题。因为这种情况中有可能各个二级子表中的数据数量相差非常大,这将导致某些子表的访 问量很少,而某些子表的访问量很大。这些访问量大的表很容易发生多个线程同时访问的情况,从而导致集中式锁竞争情况的发生。
为了解决二级查找结构中的不足,下面来看看多级查找结构的设计思想。
多级查找结构设计思想
多级查找结构是在二级查找结构的基础上设计的,当某个子表中数据个数过多时,可以将其拆分成两个或更多个子表,同时新建一个索引表来指向这几个拆分候的子表,指向原来子表的指针指向新建的索引表。
如果拆分后的子表内插入的数据过多时,可以继续将其分拆,这样一直分拆下去,将形成一个多级的查找数据结构,下图就是一个多级查找结构示意图。
















