












Ironfan介绍
在Serengeti中,有二个最重要最关键的功能:一是虚拟机管理,即在vCenter中为一个Hadoop集群创建和管理所需要的虚拟机;另一个是集群软件安装配置管理,即在已安装好操作系统的虚拟机上安装Hadoop相关组件(包括Zookeeper,Hadoop,Hive,Pig等),更新配置文件(例如Namenode/Jobtracker/Zookeeper结点的IP等信息),然后启动Hadoop服务。Ironfan就是在Serengeti中负责集群软件安装配置管理的组件。
Ironfan是基于Chef技术开发的集群软件部署配置管理工具。Chef是一个类似于Puppet和CFEngine的开源的系统配置管理工具,它定义了一套简单易用的DSL(Domain Specific language)语言用于在一台已安装好基本操作系统的机器上安装配置任意软件和配置系统本身。Ironfan基于Chef的框架和API提供了简单易用的自动化部署和管理集群的命令行工具。Ironfan支持部署Zookeeper,Hadoop和HBase集群,也可以编写新的cookbook以部署任意其他非Hadoop集群。
Ironfan最初由美国一家Big Data初创公司Infochimps使用Ruby语言开发,并在github.com上以Apache Licensev2开源。最开始Ironfan只支持在Amazon EC2的Ubuntu虚拟机上部署Hadoop集群。VMwareProject Serengeti团队选择了基于Ironfan来开发Big Data集群工具,并实现了一系列重大改进,让Ironfan可以在VMware vCenter中的CentOS 5.x虚拟机上创建部署Hadoop集群。ProjectSerengeti改进后的Ironfan同样以Apache License v2在github.com上开源,供用户免费下载和修改。
Ironfan架构
下图描绘了Ironfan的架构。Ironfan主要包括Cluster OrchestrationEngine,VM Provision Engine,SoftwareProvision Engine和用于存储数据的Chef Server 和Package Server。
·ClusterOrchestration Engine:Ironfan的总控制器,负责加载解析集群定义文件,创建虚拟机,在ChefServer中保存集群的配置信息,并调用Chef REST API为各个虚拟机创建对应的ChefNode和Chef Client, 并设定各个虚拟机的ChefRole。
·VMProvision Engine:创建cluster中的所有虚拟机,并等待虚拟机得到IP。VM Provision Engine提供了接口以支持在各种虚拟机云环境中创建虚拟机,目前实现了Amazon EC2和VMware vCenter的支持。在Serengeti中,所有虚拟机由Ironfan的调用者在VMware vCenter中创建,并将IP保存在cluster spec文件中,传递给Ironfan的VM Provision Engine。
·SoftwareProvision Engine: 使用虚拟机中预先创建好的缺省用户名和密码,SSH远程登录到所有虚拟机中同时启动chef-client来安装软件。chef-client是Chef框架中的代理程序,负责在其运行的结点上执行预先由Chef Role指定的安装配置脚本。chef-client也会将执行进度数据保存在Chef Server中。
·ChefServer:用于存储Chef Nodes,Chef Clients, Chef Roles, Chef Cookbooks, 提供Chef RESTAPI, 是Chef框架的重要组成部件。
·PackageServer:用于存储所需的Hadoop和其他Hadoop所依赖的安装包。
Ironfan对外提供了Knife CLI命令行接口,其调用者(即SerengetiWeb Service 组件)创建单独进程调用Knife CLI,通过进程退出状态值判断成功或者失败。具体的集群结点数据和执行进度信息由调用者随时从ChefServer获取。

IronfanKnife CLI
每一个SerengetiCLI cluster命令都对应一个IronfanKnife CLI命令,包括create (创建集群)、list(查看集群)、config(配置集群)、stop(停止集群)、start(启动集群)、delete(删除集群)。
clustercreate => knife cluster create
clusterlist => knife cluster show
clusterconfig => knife cluster bootstrap
clusterstop => knife cluster stop
clusterstart => knife cluster start
clusterdelete => knife cluster kill
其中参数/opt/serengeti/logs/task/
Ironfancluster定义文件 (DSL, roles)
接下来,我们看看Ironfan是如何定义集群的。下图是一个名为demo的cluster的定义文件demo.rb,它是一个Ruby文件,用Ironfan所定义的DSL语言描述集群的组成结构,定义了3个虚拟机组。其中每一个facet定义了一个虚拟机组,包含若干个安装同样软件的虚拟机。每个分组中结点个数由instance指定,虚拟机上要安装的软件由role指定。这个role就是Chef中所定义的role。
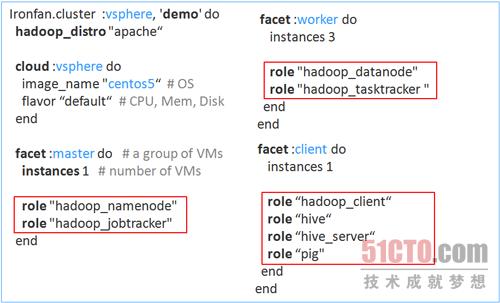
Chef Roles和 Cookbooks
在Serengeti中所有Chef Role文件存放于/opt/serengeti/cookbooks/roles/*.rb,所有
Chef Cookbook 文件存放于/opt/serengeti/cookbooks/cookbooks/
以hadoop_namenode role为例,/opt/serengeti/cookbooks/roles/hadoop_namenode.rb 内容如下:
name 'hadoop_namenode'
description 'runs a namenode infully-distributed mode. There should be exactly one of these per cluster.'
run_list %w[
role[hadoop] # 一个role可以包含引用另一个role
hadoop_cluster::namenode # hadoop_cluster 是一个cookbook, namenode是此cookbook中的一个recipe
]
如果开发者需要修改调试 role和cookbook,可在修改role和cookbook 文件后,运行以下命令上传role和cookbook:
knife role from file/opt/serengeti/cookbooks/roles/
knifecookbook upload
Cluster Service Discovery
在集群部署过程之中,有些组件的安装和服务的启动顺序是有先后依赖的,比如Datanode服务需要在Namenode服务启动之后再启动,Tasktracker服务需要在Jobtracker服务启动之后再启动,并且这些服务通常不在同一个虚拟机上。因此Ironfan在部署过程中需要控制不同结点上服务的安装和启动顺序,让有依赖关系的结点同步。Ironfan是使用一个名为cluster_service_discovery的cookbook实现相关结点之间同步。
cluster_service_discoverycookbook定义了provide_service,provider_fqdn,provider_fqdn_for_role,all_providers_for_service等等方法,用于实现结点同步。我们以datanode服务需要等待namenode服务启动为例讲解如何实现同步:
·在namenoderecipe中,启动namenode服务之后,调用provide_service(node[:hadoop][:namenode_service_name]),向Chef Server把此结点注册为namenode 服务的提供者;
·在datanoderecipe中,启动datanode服务之前,调用provider_fqdn(node[:hadoop][:namenode_service_name])向Chef Server查询namenode服务提供者的FQDN(或IP); provider_fqdn方法会每隔5秒种向Chef Server查询一次,直到查询到结果,或者30分钟后超时报错。
其他相关结点的同步也与此机制相似,例如Zookeeper结点之间的相互等待,HBase结点等待Zookeeper结点,具体方法调用可查看cluster_service_discovery,zookeeper,hadoop, 和hbase cookbook的源代码。
关于vSphere Big Data Extensions:
VMware vSphere Big Data Extensions(简称BDE)基于vSphere平台支持大数据和Apache Hadoop作业。BDE以开源Serengeti项目为基础,为企业级用户提供一系列整合的管理工具,通过在vSphere上虚拟化Apache Hadoop,帮助用户在基础设施上实现灵活、弹性、安全和快捷的大数据部署、运行和管理工作。了解更多关于VMware vSphere Big Data Extensions的信息,请参见http://www.vmware.com/hadoop。
作者介绍
胡辉 (Jesse Hu)
VMware高级开发工程师
担任VMware大数据产品vSphere BDE和Serengeti开源项目的技术带头人之一,是Serengeti开源项目最早期的开发者,并实现了第一个原型系统,是Serengeti集群软件安装配置管理模块Ironfan的设计者。在加入VMware之前,曾就职于Yahoo,IBM,Oracle等多家IT企业,对开源社区,云计算, Mobile, SNS, Web 2.0, Ruby都有了解和研究。


















