众所周知,hadoop在10月底release了最新版2.2。很多国内的技术同仁都马上在网络上推出了自己对新版hadoop的配置心得。这其中主要分为两类:
1.单节点配置
这个太简单了,简单到只要懂点英语,照着网上说的做就ok了。我这里不谈这个,有兴趣的童鞋可以自己去问度娘和谷哥~
2.多节点配置
这个就是我要重点说明的,老实说网络上说的的确是多节点,但不是真正的分布式部署~ 我们为什么要用hadoop?因为hadoop是一个分布式系统基础架构,我们可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 如果只是多节点,但是程序还在一个节点运行,其它节点没有参与程序运行活动。 那和你在网吧里,自己一个人看片子和其他人无交集有什么区别? 所以网上提供的都是多节点伪分布式的配置~
接下来我会贡献出自己这几天弄的一些心得,或许有人看了开头觉得我写的和网上那些差不多,但是真正的区别我会在之后列出来,就看谁有耐心看完我写的东西啦~霍霍~
准备
我用的linux系统是ubuntu 12.04 LTS server版(就是没有桌面显示的版本)。 虚拟机用的是VMWare Workstation10,ssh客户端是开源的putty,还有ftp客户端软件是cuteFTP(虽然可以在linux系统里用vim对文件进行编辑修改,但我觉得有客户端直接在windows系统里修改文件比较方便和高效)。 tomcat版本是6.0.29,jdk版本是1.7.45。虚拟机里ubuntu的网络设置我用的是UAT模式,也就是说和外部window系统的网络配置是共享的,除了IP地址不一样,其他都雷同。
安装tomcat和jdk什么我就不用说了。还有初始的分辨率是600x800,需要重调我也不说了。至于安装vsftpd和openssh,我更加不说了。度娘和谷哥都知道。
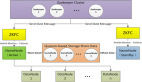
这里就列我弄的两个ubuntu系统。hadoop里把主节点系统叫为master,从节点系统叫为slave。master只能有一 个,slave可以有许多个。就如一个老板可以有很多员工为他打工一样。(当然在很多情况下,还会有个做备份的master,防止master出问题时 候,有个替补直接顶上)
为了行文方便,后面我就直接用master和slave称呼这两个。(网上都喜欢用三节点做例子,一个master两个slave,我简化了一下,就一个master和一个slave,反正都是以此类推的东西,搞简单点)
我的系统原始信息:
| hostname | IP address | |
| master | hadoop | 192.168.72.130 |
| slave | hadoop1 | 192.168.72.128 |
hostname是自己改的,IP地址是你安装完你的ubuntu后,电脑在UAT模式下自动生成的IP地址。请根据你自己情况记录这些信息。还有hostname如何永久地改成hadoop和hadoop1,请问度娘和谷哥。
每个ubuntu里分别加入专为hadoop使用的帐号
命令:
addgroup hadoop adduser –ingroup hadoop wujunshen这个wujunshen是我在用VMWare安装ubuntu时候,让我自己设定的帐号名字,大家可以自行设定。但是hadoop这个用户组名最好不要改。
有人会问 ubuntu里非root账户登录后,输入命令开头不都要打sudo么?这个其实也可以设置,再次提醒请问度娘和谷哥。这里哥给个当年自己记录的博文链接: http://darkranger.iteye.com/admin/blogs/768608
注意:两个ubuntu的hadoop帐号名要一样,不一样就算你配置好了,测试时候也不成功的。我看了一下hadoop的代码,它好像是在hadoop代码里写死了读取帐号名的值。(shell不太会,只看了个大概) 有人说要在系统里设置%HADOOP_HOME%为你安装hadoop的路径,就可以帐号名不一样了。 我没试验过,因为我觉得测试这个有点无聊了,或许《生活大爆炸》里Sheldon会这么做。:)
建立两个系统ssh通信互相信任关系
要在两个系统上每一个进行以下操作。(如果slave有很多个,这样做是很浪费时间的,一般都要用个shell自动化脚本来建立信任关系。这里只是示例,麻烦各位手打或copy了。)
进入wujunshen帐号,输入命令
ssh-keygen -t rsa -P "" cat .ssh/id_rsa.pub >>.ssh/authorized_keys (出现两个问题,第一个问题回车就行,第二个输入y回车,千万不要直接回车,否则不会生成key) 注意:如果出现错误:-bash: .ssh/authorized_keys: No such file or directory 这是由于新建好的用户帐号,比如我这里是wujunshen这个帐号,默认没有.ssh目录,需要自己建立。
mkdir -p ~/.ssh接下来还有一步,我用cuteFTP做的,觉得自己牛逼的可以用linux的拷贝粘贴命令搞。
在每个ubuntu下找到刚才生成的authorized_keys文件,我这里路径是: /home/wujunshen/.ssh/authorized_keys
修改该文件,让此文件包含生成的rsa字符串(有关RSA加密算法的由来,你还是可以去问度娘和谷哥,那是个传奇的故事)和两个ubuntu的hostname,比如我这里是:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDEBNUjKbZQOQsc6iNawm5VxXk+Kx5MXS1A6ZX/xtAfAI3jurVTgNHz6T2exf/dHP3aoaK49vl6EeMg4hZ7qwxldeERMXNBu5m0y/JyRupX9RfHRjJyqSXRdJ1WjE2ySPtXdLNPjKDvzjf61dSP/iMXeemlZfZV2VNqJiLTlpG3OvjraICUXCXMMB4h72Qm59iIHZ4iRI2v5VMmp+CeGEqHba0O8UUkpSpqC8vZCFJKL+IfCFups9OGrKIT854/Xc+vPSd89jA3RLubJThE/F/8QczqSBHXYrLeUMir3lFEPqLe7U4jk5n83/3fAsagaUyXBCWGm7LanLgXsqMfKBxD wujunshen@hadoop1 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC+umV0w7qcQyHJzfqRc+mHE+eCWw8Ns/uU05CF4fEJnGkys+0Itwsh+edwt8K4oHZ8rK0THO1ip2oNXHzVJ8aJ7rpeI19N0BubCahhGbVNqzgyGgvbnz3+xD/La47YNBzjHF4AxTu+Dj51vOp1yRaiTwhu93o9PP18x2Ai7aNQEap7pGpBwogbfSWDBvZNq9PJYinjzhnVqJ7bctJe+1ufme7bX+vyu1hrdtfpwXgW5GiXQ6uvYH6ExiTSWlLFMyDgD63APm1P2Hs1hlR1gNE3SC4q34mfExhoxY3JJgfbP0x2rt8PfdWk5Lzxtaylj85bmZi/9xDvXdoqjtSv4Mxb wujunshen@hadoop保证每个ubuntu系统的authorized_keys文件都包含wujunshen@hadoop1和wujunshen@hadoop以及它们的rsa字符串.
然后在其中一个ubuntu上进行测试,比如我这里在master里输入
ssh hadoop1 去访问slave,这样就不需要输入密码就能访问hadoop1,然后我输入
ssh hadoop 回到master。
结果如下:
wujunshen@hadoop:~$ ssh hadoop1 Welcome to Ubuntu 12.04.3 LTS (GNU/Linux 3.8.0-29-generic i686) * Documentation: https://help.ubuntu.com/ Last login: Wed Nov 27 19:29:55 2013 from hadoop wujunshen@hadoop1:~$ ssh hadoop Welcome to Ubuntu 12.04.3 LTS (GNU/Linux 3.8.0-29-generic i686) * Documentation: https://help.ubuntu.com/ Last login: Wed Nov 27 19:30:03 2013 from hadoop1 wujunshen@hadoop:~$截图:
注意:如果ssh hadoop或ssh hadoop1 出现错误: Host key verification failed
解决方法:到 /home/wujunshen/.ssh目录下找到known_hosts文件,删除known_hosts文件。命令
rm known_hosts #p#
安装
去官网下载hadoop-2.2.0.tar.gz
然后在两个ubuntu里进行以下操作。
解压压缩包在/home/wujunshen目录下
命令:
tar zxf hadoop-2.2.0.tar.gz 解开之后是个hadoop-2.2.0文件夹,改名为hadoop
命令:
mv hadoop-2.2.0 hadoop 安装结束。(安装很简单,但你要想用起来,接下来是重头戏)
配置
以下操作,master和slave都是一样的。
在/home/wujunshen/hadoop/etc/hadoop下找 hadoop-env.sh,修改此文件 找到export JAVA_HOME这一列,后面改成自己的jdk安装目录,比如我这里是/usr/lib/jdk1.7.0_45
改成
export JAVA_HOME=/usr/lib/jdk1.7.0_45 在同一路径下找 core-site.xml,修改它在 < configuration >中添加:
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/home/wujunshen/hadoop/tmp/hadoop-${user.name}</value>
- <description>A base for other temporarydirectories.</description>
- </property>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://192.168.72.130:8010</value>
- <description>The name of the default file system. A URI whose
- scheme and authority determine the FileSystem implementation. The
- uri's scheme determines the config property (fs.SCHEME.impl) naming
- the FileSystem implementation class. The uri's authority is used to
- determine the host, port, etc. for a filesystem.</description>
- </property>
注意:
- /home/wujunshen/hadoop下缺省是没有tmp文件夹的,要用命令: mkdir /home/wujunshen/hadoop/tmp创建
- hdfs://192.168.72.130:8010 里的IP地址就是master 的IP地址
同一路径下修改 mapred-site.xml
因为缺省是没有这个文件的,要用模板文件造一个,命令为:
- mv /home/wujunshen/hadoop/etc/hadoop/mapred-site.xml.template /home/hduser/hadoop/etc/hadoop/mapred-site.xml
在 < configuration >中添加:
- <property>
- <name>mapred.job.tracker</name>
- <value>192.168.72.130:54311</value>
- <description>The host and port that the MapReduce job tracker runs
- at. If "local", thenjobs are run in-process as a single map
- and reduce task.
- </description>
- </property>
- <property>
- <name>mapred.map.tasks</name>
- <value>10</value>
- <description>As a rule of thumb, use 10x the number of slaves(i.e., number of tasktrackers).
- </description>
- </property>
- <property>
- <name>mapred.reduce.tasks</name>
- <value>2</value>
- <description>As a rule of thumb, use 2x the number of slaveprocessors (i.e., number of tasktrackers).
- </description>
- </property>
注意:< value >192.168.72.130:54311< /value >里的IP地址就是master 的IP地址
同一路径下修改 hdfs-site.xml, 在 < configuration >中添加:
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- <description>Default block replication.
- Theactual number of replications can be specified when the file is created.
- Thedefault is used if replication is not specified in create time.
- </description>
- </property>
注意:< value >1< /value >里的数字1表明的是dfs文件备份个数, 如果你只有3个slave,但是你却指定值为4,那么这是不会生效的,因为每个salve上只能存放一个备份文件。 如果你设置了100个slave,那么这个就写100。 我这里slave就1个,就写了1。 网上那些因为都是三节点,一个master,两个slave,所以都写2,但网上很少有人会说要根据实际slave的个数修改。
同一路径下修改slaves文件 增加所有slaves的hostname。比如我这里slave就一个,hostname是hadoop1,所以只有一个hadoop1,该文件内容只为
- hadoop1
运行
所有操作只需要在master运行即可。系统会自动登录到slave上。
初次运行Hadoop的时候需要初始化Hadoop文件系统 ,在master上输入命令
- cd /home/wujunshen/hadoop/bin
- ./hdfs namenode -format
执行成功,你会在日志中(倒数几行)找到如下成功的提示信息:
- common.Storage: Storage directory /home/wujunshen/hadoop/tmp/hadoop-wujunshen/dfs/name has been successfully formatted.
再去启动hadoop,命令:
- cd home/wujunshen/hadoop/sbin/
- ./start-dfs.sh
- ./start-yarn.sh
#p#
注意:你也可以直接运行./start-all.sh,不用分开启动dfs和yarn.第一次运行start-all会出现一个问题,输入yes就行了。
查看运行结果 执行你的jdk运行目录下的jps,比如我这里是 /usr/lib/jdk1.7.0_45/bin/
输入命令:
- /usr/lib/jdk1.7.0_45/bin/jps
在hadoop上结果为:
- 6419 ResourceManager
- 6659 Jps
- 6106 NameNode
- 6277 SecondaryNameNode
在hadoop1结果为:
- 3930 SecondaryNameNode
- 4222 Jps
- 3817 DataNode
- 3378 NodeManager
或执行命令
- cd /home/wujunshen/hadoop/bin
- ./hdfs dfsadmin -report
结果:
- Configured Capacity: 51653570560 (48.11 GB)
- Present Capacity: 46055575552 (42.89 GB)
- DFS Remaining: 46055550976 (42.89 GB)
- DFS Used: 24576 (24 KB)
- DFS Used%: 0.00%
- Under replicated blocks: 0
- Blocks with corrupt replicas: 0
- Missing blocks: 0
- -------------------------------------------------
- Datanodes available: 1 (1 total, 0 dead)
- Live datanodes:
- Name: 192.168.72.128:50010 (hadoop1)
- Hostname: hadoop1
- Decommission Status : Normal
- Configured Capacity: 51653570560 (48.11 GB)
- DFS Used: 24576 (24 KB)
- Non DFS Used: 5597995008 (5.21 GB)
- DFS Remaining: 46055550976 (42.89 GB)
- DFS Used%: 0.00%
- DFS Remaining%: 89.16%
- Last contact: Wed Nov 27 23:56:32 PST 2013
截图:
注意:有时候会发现hadoop1上的datanode没有出现,这个时候以我的体会,最好是把/home/wujunshen/hadoop下的tmp文件夹删除,然后重新建,重新初始化hadoop文件系统,重启hadoop,然后执行两种查看方式再看看
测试
两种测试方法,实际是运行了两个示例程序,一个是wordcount,另外一个是randomwriter
1.执行下列命令:
- cd /home/wujunshen
- wget http://www.gutenberg.org/cache/epub/20417/pg20417.txt
- cd hadoop
- bin/hdfs dfs -mkdir /tmp
- bin/hdfs dfs -copyFromLocal /home/wujunshen/pg20417.txt /tmp
- bin/hdfs dfs -ls /tmp
- bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /tmp/ /tmp-output
2.执行下列命令:
- cd /home/wujunshen/hadoop
- bin/hdfs dfs -mkdir /input
- bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar randomwriter input
总结
如果你能看到这里,而且按照我之前说的已经运行成功了。那么恭喜你,你实现了hadoop多节点伪分布式的配置。对的,你没看错!!!就是伪分布式~ 可能有人不服气会说:怎么到这里就是伪分布式了呢?不是都OK的么?那么我请你仔细看看你测试中选择的两种示例程序启动的job,如图是运行第二个randomwriter 程序的job:
看到红框了伐?全是Local!!!也就是说不管你执行哪个示例程序,启动的job都只是在master这个节点本地运行的job。哪里有让slave节点参与了?
再说,看看wordcount这个单词就知道是个计算单词的示例程序,如果只有master一个节点计算,那么这能算分布式多节点参与计算么? 所以各位朋友,请接着耐心地看下去,看我如何施展魔法让hadoop真正的进行分布式计算!!!
#p#
真.配置
之前配置里所说的那些文件修改还是要的。这里我们再对其中一些文件进行修改。
在/home/wujunshen/hadoop/etc/hadoop 下找到 yarn-env.sh,修改它
找到设置JAVA_HOME的那一列 改成:
- export JAVA_HOME=/usr/lib/jdk1.7.0_45
在/home/wujunshen/hadoop/etc/hadoop 下修改mapred-site.xml 在 < configuration >中添加(原先的配置还留着):
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>192.168.72.130:10020</value>
- </property>
- <property>
- <value>192.168.72.130:19888</value>
- </property>
在/home/wujunshen/hadoop/etc/hadoop 下修改yarn-site.xml 在 < configuration >中添加:
- <property>
- <name>yarn.resourcemanager.address</name>
- <value>hadoop:8032</value>
- </property>
- <property>
- <description>The address of the scheduler interface.</description>
- <name>yarn.resourcemanager.scheduler.address</name>
- <value>hadoop:8030</value>
- </property>
- <property>
- <description>The address of the RM web application.</description>
- <name>yarn.resourcemanager.webapp.address</name>
- <value>hadoop:8088</value>
- </property>
- <property>
- <name>yarn.resourcemanager.resource-tracker.address</name>
- <value>hadoop:8031</value>
- </property>
- <property>
- <description>The address of the RM admin interface.</description>
- <name>yarn.resourcemanager.admin.address</name>
- <value>hadoop:8033</value>
- </property>
- <property>
- <description>The address of the RM admin interface.</description>
- <name>yarn.nodemanager.address</name>
- <value>hadoop:10000</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
注意:这里很多value都是hadoop打头的,我一开始修改这些文件都是填写master的IP地址,我后来试验了一下,其实用master的hostname,也就是hadoop也可以的。
好了重复测试里那两个示例程序,这里我运行了randomwriter程序,因为之前已经创建过input文件夹,现在执行命令会报错说input已存在,很简单,后面加个1就行,命令变成
- cd /home/wujunshen/hadoop
- bin/hdfs dfs -mkdir /input1
- bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar randomwriter input1
重复执行这些命令的话,就把后面改成2,3,4就好了。反正是例子,随意一点,不用像工作中要取个很正式的名字。
结果如下:
- 13/11/28 19:37:23 INFO mapreduce.Job: Running job: job_1385696103815_0001
- 13/11/28 19:37:43 INFO mapreduce.Job: Job job_1385696103815_0001 running in uber mode : false
- 13/11/28 19:37:43 INFO mapreduce.Job: map 0% reduce 0%
- 13/11/28 19:51:05 INFO mapreduce.Job: map 10% reduce 0%
- 13/11/28 19:51:11 INFO mapreduce.Job: map 20% reduce 0%
- 13/11/28 19:51:13 INFO mapreduce.Job: map 30% reduce 0%
- 13/11/28 19:51:19 INFO mapreduce.Job: map 40% reduce 0%
- 13/11/28 19:51:21 INFO mapreduce.Job: map 50% reduce 0%
- 13/11/28 19:51:40 INFO mapreduce.Job: map 60% reduce 0%
- 13/11/28 20:03:37 INFO mapreduce.Job: map 70% reduce 0%
- 13/11/28 20:03:48 INFO mapreduce.Job: map 80% reduce 0%
- 13/11/28 20:03:49 INFO mapreduce.Job: map 90% reduce 0%
- 13/11/28 20:03:51 INFO mapreduce.Job: map 100% reduce 0%
- 13/11/28 20:03:53 INFO mapreduce.Job: Job job_1385696103815_0001 completed successfully
- 13/11/28 20:03:53 INFO mapreduce.Job: Counters: 30
- File System Counters
- FILE: Number of bytes read=0
- FILE: Number of bytes written=789520
- FILE: Number of read operations=0
- FILE: Number of large read operations=0
- FILE: Number of write operations=0
- HDFS: Number of bytes read=1270
- HDFS: Number of bytes written=10772863128
- HDFS: Number of read operations=40
- HDFS: Number of large read operations=0
- HDFS: Number of write operations=20
- Job Counters
- Killed map tasks=5
- Launched map tasks=15
- Other local map tasks=15
- Total time spent by all maps in occupied slots (ms)=9331745
- Total time spent by all reduces in occupied slots (ms)=0
- Map-Reduce Framework
- Map input records=10
- Map output records=1021605
- Input split bytes=1270
- Spilled Records=0
- Failed Shuffles=0
- Merged Map outputs=0
- GC time elapsed (ms)=641170
- CPU time spent (ms)=806440
- Physical memory (bytes) snapshot=577269760
- Virtual memory (bytes) snapshot=3614044160
- Total committed heap usage (bytes)=232574976
- org.apache.hadoop.examples.RandomWriter$Counters
- BYTES_WRITTEN=10737514428
- RECORDS_WRITTEN=1021605
- File Input Format Counters
- Bytes Read=0
- File Output Format Counters
- Bytes Written=10772863128
- Job ended: Thu Nov 28 20:03:53 PST 2013
- The job took 1594 seconds.
#p#
可以看到这个时候Job名字打头已经不是local了,而是job了。而且可以登录http://192.168.72.130:8088查看运行的job状态
如图:
上图还是这个job处于running状态时的信息。
完成时信息如下图:
现在我们再执行那个wordcount程序,这里和randomwriter类似。
命令是
- cd /home/wujunshen/hadoop
- bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /tmp/ /tmp-output100(为啥是tmp-output100,之前在说randomwriter示例程序时候已经说过)
结果:
- 3/11/29 00:01:40 INFO client.RMProxy: Connecting to ResourceManager at hadoop/192.168.72.130:8032
- 13/11/29 00:01:41 INFO input.FileInputFormat: Total input paths to process : 1
- 13/11/29 00:01:41 INFO mapreduce.JobSubmitter: number of splits:1
- 13/11/29 00:01:41 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapreduce.combine.class is deprecated. Instead, use mapreduce.job.combine.class
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
- 13/11/29 00:01:41 INFO Configuration.deprecation: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
- 13/11/29 00:01:42 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1385696103815_0009
- 13/11/29 00:01:42 INFO impl.YarnClientImpl: Submitted application application_1385696103815_0009 to ResourceManager at hadoop/192.168.72.130:8032
- 13/11/29 00:01:42 INFO mapreduce.Job: The url to track the job: http://hadoop:8088/proxy/application_1385696103815_0009/
- 13/11/29 00:01:42 INFO mapreduce.Job: Running job: job_1385696103815_0009
- 13/11/29 00:01:53 INFO mapreduce.Job: Job job_1385696103815_0009 running in uber mode : false
- 13/11/29 00:01:53 INFO mapreduce.Job: map 0% reduce 0%
- 13/11/29 00:02:03 INFO mapreduce.Job: map 100% reduce 0%
- 13/11/29 00:02:18 INFO mapreduce.Job: map 100% reduce 50%
- 13/11/29 00:02:19 INFO mapreduce.Job: map 100% reduce 100%
- 13/11/29 00:02:20 INFO mapreduce.Job: Job job_1385696103815_0009 completed successfully
- 13/11/29 00:02:20 INFO mapreduce.Job: Counters: 43
- File System Counters
- FILE: Number of bytes read=267032
- FILE: Number of bytes written=771667
- FILE: Number of read operations=0
- FILE: Number of large read operations=0
- FILE: Number of write operations=0
- HDFS: Number of bytes read=674677
- HDFS: Number of bytes written=196192
- HDFS: Number of read operations=9
- HDFS: Number of large read operations=0
- HDFS: Number of write operations=4
- Job Counters
- Launched map tasks=1
- Launched reduce tasks=2
- Data-local map tasks=1
- Total time spent by all maps in occupied slots (ms)=7547
- Total time spent by all reduces in occupied slots (ms)=25618
- Map-Reduce Framework
- Map input records=12760
- Map output records=109844
- Map output bytes=1086547
- Map output materialized bytes=267032
- Input split bytes=107
- Combine input records=109844
- Combine output records=18040
- Reduce input groups=18040
- Reduce shuffle bytes=267032
- Reduce input records=18040
- Reduce output records=18040
- Spilled Records=36080
- Shuffled Maps =2
- Failed Shuffles=0
- Merged Map outputs=2
- GC time elapsed (ms)=598
- CPU time spent (ms)=4680
- Physical memory (bytes) snapshot=267587584
- Virtual memory (bytes) snapshot=1083478016
- Total committed heap usage (bytes)=152768512
- Shuffle Errors
- BAD_ID=0
- CONNECTION=0
- IO_ERROR=0
- WRONG_LENGTH=0
- WRONG_MAP=0
- WRONG_REDUCE=0
- File Input Format Counters
- Bytes Read=674570
- File Output Format Counters
- Bytes Written=196192
可以看到job名字也是以job打头的一个名字。
注意:这里有可能会碰到错误:
- java.io.FileNotFoundException: Path is not a file: /tmp/hadoop-yarn
解决方法很简单,命令是:
- cd /home/wujunshen/hadoop
- bin/hdfs dfs -mkdir /tmp
- bin/hdfs dfs -copyFromLocal /home/wujunshen/pg20417.txt /tmp
- bin/hdfs dfs -ls /tmp
(如果之前已经运行过以上命令就没必要再输入这些命令了。我顺便讲一下这几个命令,其实hadoop是在ubuntu的文件系统中划出了一块作为它自己的 文件系统,所谓的hdfs全称就是hadoop file system,但是这个文件系统中的文件和文件夹是无法用ubuntu的命令找到的,也无法在win7,win8中用FTP客户端cuteFTP找到。因 为这是虚拟的文件系统,现实中不存在。所以如果要在这个虚拟化的文件系统中进行文件和文件夹创建,还有拷贝和查看等操作,必须开头是以bin/hdfs dfs打头的,这样就能在这个虚拟的文件系统中进行普通系统的操作,当然后面要有个减号,可以看到mkdir /tmp,copyFromLocal /home/wujunshen/pg20417.txt /tmp和ls /tmp就是普通文件系统操作命令)
- bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /tmp/pg20417.txt /tmp-output101
#p#
出现该错误的原因是在运行上条命令时候,在虚拟文件系统hdfs的tmp文件夹下自动创建了一个/tmp/hadoop-yarn,而我们是对 pg20417.txt 这个文本中的word个数进行计算,要找的是file而不是path,所以我们改成/tmp/pg20417.txt, 让wordcount 程序知道自己要找的是个file而不是path,而且还知道自己要找的是哪个file。
登录http://192.168.72.130:8088查看运行的job状态
可以看到我试验的各种成功和失败的job信息
真.总结
其实hadoop中有个很重要的东西就是yarn。在真.配置里修改的那些有关yarn的配置文件是让hadoop变成真正的分布式系统的关键。 在这里我简单地对yarn介绍一下:
yarn原意为“纱线”,想想我们刚才对它进行了配置让我们实现了真正的分布式配置,我顿时觉得用纱线这个名字还挺形象的,呵呵。 它是hadoop的一个资源管理器。它的资源管理和执行框架都是按master/slave范例实现——节点管理器(NM)运行、监控每个节点,并向资源管理器报告资源的可用性状态。 特定应用的执行由Master控制,负责将一个应用分割成多个Job,并和资源管理器协调执行所需的资源。资源一旦分配好,Master就和节点管理器一起安排、执行、监控独立的Job。 yarn提供了一种新的资源管理模型和执行方式,用来执行MapReduce任务。因此,在最简单的情况下,现有的MapReduce应用仍然能照原样运行(需要重新编译),yarn只不过能让开发人员更精确地指定执行参数。
好了,我终于写完了。大家随便看看吧~
题外话
我蛮喜欢hadoop这个黄色小象的logo,贴出来给大家养养眼
另外不知道大家在登录时有没有注意到右上角的登录帐号,见下图红框:
这个dr. who可是大大有名啊~它是目前人类历史上最长的电视连续剧,英国科幻剧《神秘博士》的剧名。前不久google上还纪念过这部电视剧开播50周年。新版 的dr. who从2005年开始也开播了快10年了。至于它的外传剧集《火炬木小组》在国内年轻人之中更加有名。(火炬木小组绝对是个坑,从2006年开始播,到 现在也只有四季,平均每两年出一季,第一,第二季还一季20多集,从第三季开始居然只有五六集。而且到现在也没说会不会拍第五季,不过看第四季最后一集应 该有续集。这片子主角杰克上校扮演者在美剧《绿箭侠》里演一号反派。第四季里那个会说上海话的黑人在夏天《星际迷航》最新电影版里也出来过,就是被可汗胁 迫炸楼的那位。)
原文链接:http://www.ituring.com.cn/article/63927