以前只用过Hive与impala两个类SQL查询系统,最近又将Hortonworks开源的Stinger与Apache的Drill做了些调研。累死累活搞了一天的资料,头都大了。为了纪念我那逝去的脑细胞,特将这些信息整理出来。
由于调查时间比较短(一天的时间都头晕眼花了,再长点估计我就要过劳死了),所写之处难免会有差错,欢迎大家指正。
总体来说虽然impala、stinger、drill三个系统都是类SQL实时查询系统,但是它们的侧重点完全不同。而且它们也不是为了替换Hive而生,hive在做数据仓库时还是很有价值的。
目前来说只有impala比较成熟(人家标称要使用CDH版本hadoop,如果要使用apache的,要做好测试的心里准备)。
其它两个系统还都处理孵化状态,但是前景非常不错。
Impala
这个系统是Cloudera开源的,时间大约是在12年下半年。虽然到现在才一年的时间但是已经有很多人在使用。社区也比较活跃,大家可以在github上面看到项目的开发人员与代码提交情况(地址:https://github.com/cloudera/impala)。个人感觉开发者虽然有其它几个公司,但是还是以cloudera为主。这样也造就了impala开发的比较快速,虽然到现在才一年左右的时间,但是impala已经可以很稳定的运行。
impala主要是为hdfs与hbase数据提供实时SQL查询。它是根据google的dremel论文实现的一套分布式系统,自用户提交的SQL开始都是基于自身的分析器与执行器。下图是其架构图
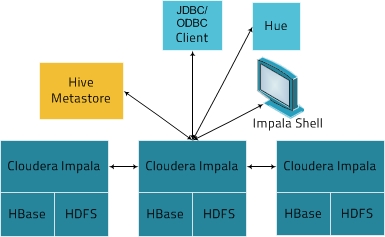
(图片源自:impala安装使用说明书)
由于完全脱离了M/R技术,自身根据HDFS的文件分布来调整计算,所以速度较Hive有很大提升。根据我个人使用部分TPC基准测(为什么是部分?没理 由,我只选了一部分SQL来跑),impala虽然性能提升不像Cloudera标称的达到hive的一百倍,但是在比较复杂的情况下达到40-70倍性 能提高还是有的。
就日常使用来说,标称是支持大部分SQL-92标准(我也不清楚这个标准到底有多少,专业的童鞋给点解读呗!!)。根据我 是测试,日常用的SQL都没有问题。并且impala支持JDBC与ODBC的连接,这对于我们的使用也是很必要的,基于此特点我们可以开发对应业务系统 的UI部分,从而不用要求业务人员自己下SQL了(这是为数不多的展现工作成果的时候了)。
其次就是impala支持的文件格式,我们存取 数据的时候肯定要应景的选择压缩与否以及文件的存储格式。impala支持常用的Text、Sequence、avro格式,压缩方面支持Snappy、 bzip、gzip以及deflate压缩应该可以满足我们大部分的使用场景了。
而最棒的是它的UDF功能可以直接使用hive的udf库,而不需要修改任何代码,使用hive的童鞋可以庆祝了,很多任务不需要任何改变即可平滑切换impala。不过因为impala使用的是C开发的,所以impala还是鼓励大家写一个c下面的udf来提高性能。
drill
开源时间跟impala差不多,只不过属于Apache,。这个系统的目标很宏大--抽象所有数据源,做成统一接口。底层支持hbase、mongoDB、HDFS、Cassandra等数据源。
它的数据接口都是插件化,理论上支持各种查询语言,SQL自然也不例外,不过目前这个系统还是Apache的一个孵化项目,很多功能尚未完成与稳定。但是可以预见,这个系统如果完成是很有影响力的。下图为drill的架构图。
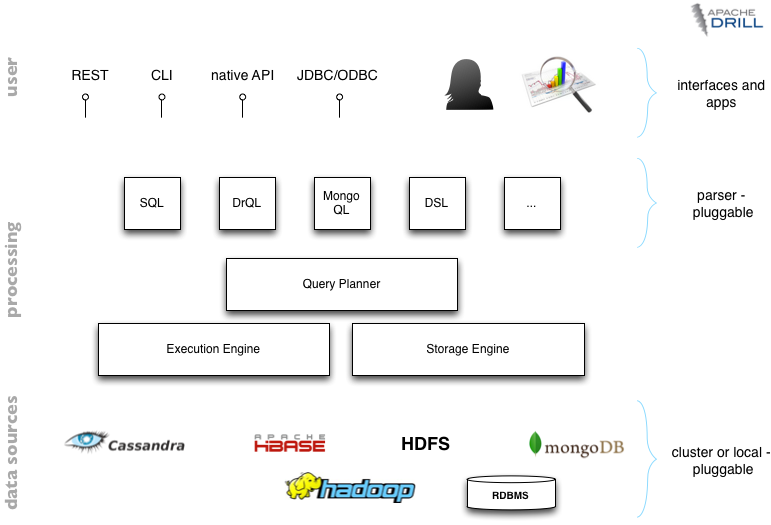
(图片源自:https://cwiki.apache.org/confluence/display/DRILL/High-level+Architecture)
Stinger
Hortonworks开源的一个实时类SQL查询系统,也是声称可以提升较hive 100倍的速度(悲崔的hive,都拿它来当反面教材)。目前处于其计划中三个阶段的最后一个阶段。
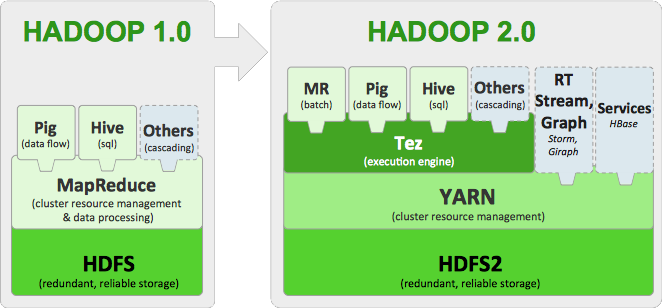
综合来看Hortonwork做的事是在hive等分析系统的现有基上加了一个优化层,所有的事都要经过它的优化层Tez(此框架是基于Yarn)来处理,以减少不必要的工作以及资源开销。虽然它也对HIVE进行了很多的优化与加强,但是这个效果就要看子系统Tez的表现的了。Tez目前也是apache的孵化项目,Stringer如果要稳定可以商用依然还有很多路要走。
从下面的示意图大家可以了解Tez所处的位置。