很多人常常对TCP优化有一种雾里看花的感觉,实际上只要理解了TCP的运行方式就能掀开它的神秘面纱。Ilya Grigorik 在「High Performance Browser Networking」中做了很多细致的描述,让人读起来醍醐灌顶,我大概总结了一下,以期更加通俗易懂。
流量控制
传输数据的时候,如果发送方传输的数据量超过了接收方的处理能力,那么接收方会出现丢包。为了避免出现此类问题,流量控制要求数据传输双方在每次交互时声明各自的接收窗口「rwnd」大小,用来表示自己最大能保存多少数据,这主要是针对接收方而言的,通俗点儿说就是让发送方知道接收方能吃几碗饭,如果窗口衰减到零,那么就说明吃饱了,必须消化消化,如果硬撑的话说不定会大小便失禁,那就是丢包了。
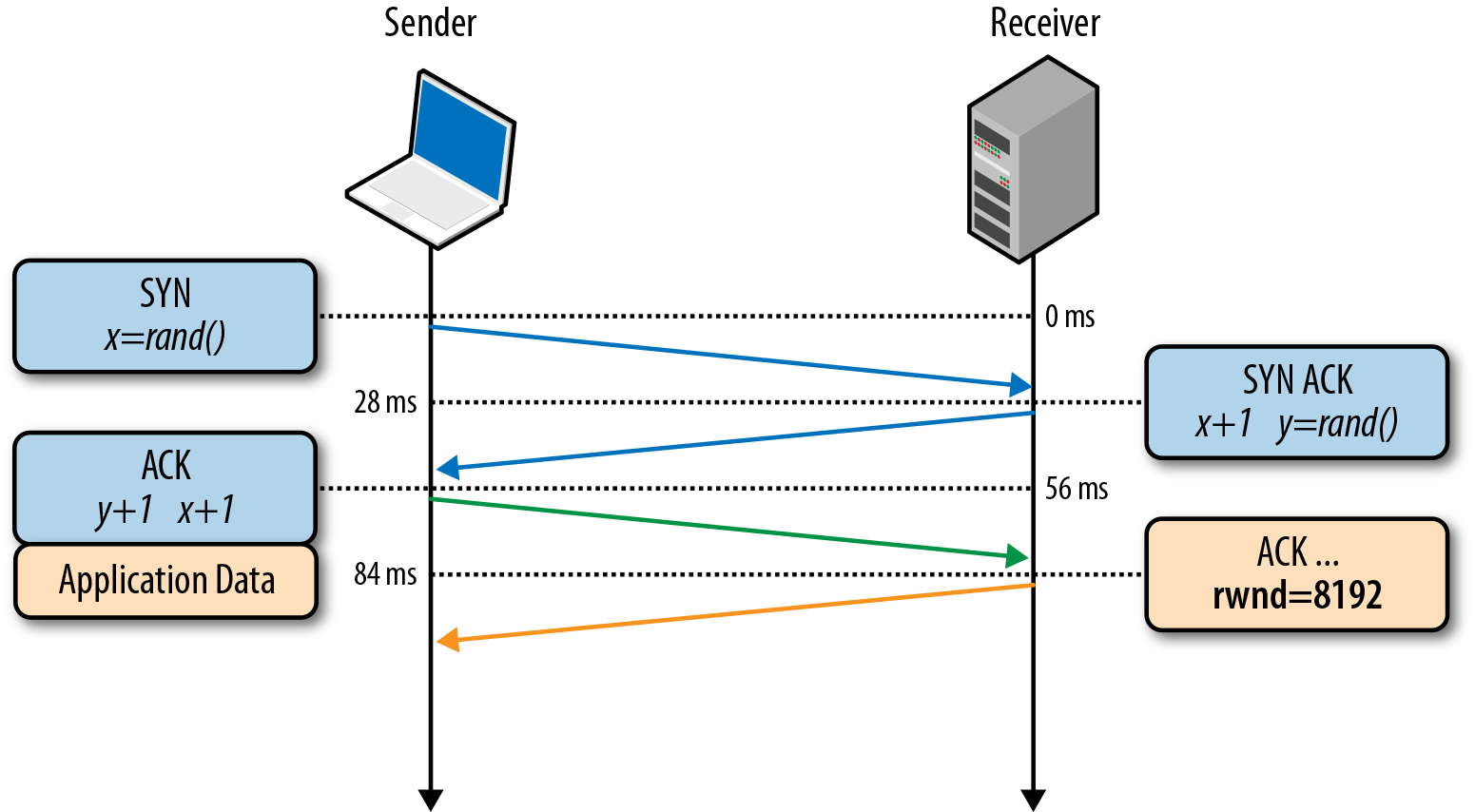
Flow Control
接收方和发送方的称呼是相对的,如果站在用户的角度看:当浏览网页时,数据以下行为主,此时客户端是接收方,服务端是发送方;当上传文件时,数据以上行为主,此时客户端是发送方,服务端是接收方。
慢启动
虽然流量控制可以避免发送方过载接收方,但是却无法避免过载网络,这是因为接收窗口「rwnd」只反映了服务器个体的情况,却无法反映网络整体的情况。
为了避免过载网络的问题,慢启动引入了拥塞窗口「cwnd」的概念,用来表示发送方在得到接收方确认前,最大允许传输的未经确认的数据。「cwnd」同「rwnd」相比不同的是:它只是发送方的一个内部参数,无需通知给接收方,其初始值往往比较小,然后随着数据包被接收方确认,窗口成倍扩大,有点类似于拳击比赛,开始时不了解敌情,往往是次拳试探,慢慢心里有底了,开始逐渐加大重拳进攻的力度。

Slow Start
在慢启动的过程中,随着「cwnd」的增加,可能会出现网络过载,其外在表现就是丢包,一旦出现此类问题,「cwnd」的大小会迅速衰减,以便网络能够缓过来。
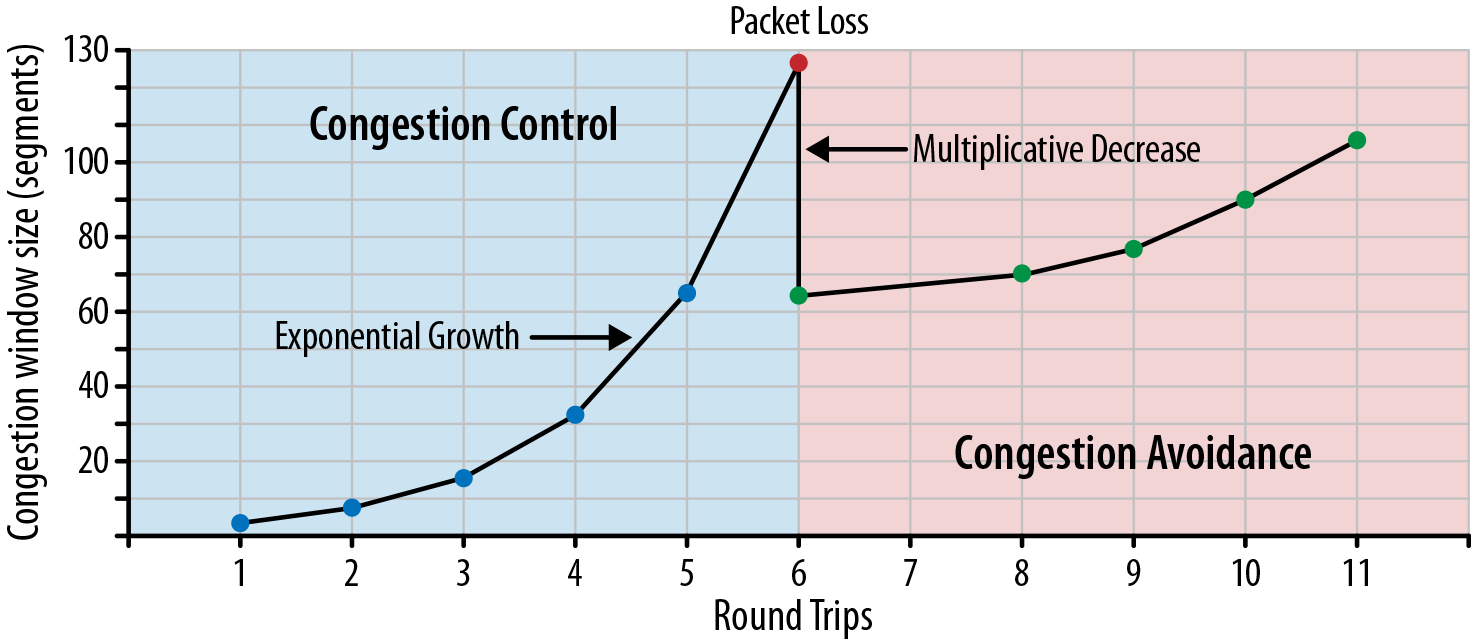
Congestion Avoidance
说明:网络中实际传输的未经确认的数据大小取决于「rwnd」和「cwnd」中的小值。
拥塞避免
从慢启动的介绍中,我们能看到,发送方通过对「cwnd」大小的控制,能够避免网络过载,在此过程中,丢包与其说是一个网络问题,倒不如说是一种反馈机制,通过它我们可以感知到发生了网络拥塞,进而调整数据传输策略,实际上,这里还有一个慢启动阈值「ssthresh」的概念,如果「cwnd」小于「ssthresh」,那么表示在慢启动阶段;如果「cwnd」大于「ssthresh」,那么表示在拥塞避免阶段,此时「cwnd」不再像慢启动阶段那样呈指数级整整,而是趋向于线性增长,以期避免网络拥塞,此阶段有多种算法实现,通常保持缺省即可,这里就不一一说明了,有兴趣的读者可以自行查阅。
…
如何调整「rwnd」到一个合理值
有很多人都遇到过网络传输速度过慢的问题,比如说明明是百兆网络,其最大传输数据的理论值怎么着也得有个十兆,但是实际情况却相距甚远,可能只有一兆。此类问题如果剔除奸商因素,多半是由于接收窗口「rwnd」设置不合理造成的。
实际上接收窗口「rwnd」的合理值取决于BDP的大小,也就是带宽和延迟的乘积。假设带宽是 100Mbps,延迟是 100ms,那么计算过程如下:
- BDP = 100Mbps * 100ms = (100 / 8) * (100 / 1000) = 1.25MB
此问题下如果想最大限度提升吞度量,接收窗口「rwnd」的大小不应小于 1.25MB。说点引申的内容:TCP使用16位来记录窗口大小,也就是说最大值是64KB,如果超过它,就需要使用tcp_window_scaling机制。参考:TCP Windows and Window Scaling。
Linux中通过配置内核参数里接收缓冲的大小,进而可以控制接收窗口的大小:
- shell> sysctl -a | grep mem
- net.ipv4.tcp_rmem = <MIN> <DEFAULT> <MAX>
如果我们出于传输性能的考虑,设置了一个足够大的缓冲,那么当大量请求同时到达时,内存会不会爆掉?通常不会,因为Linux本身有一个缓冲大小自动调优的机制,窗口的实际大小会自动在最小值和最大值之间浮动,以期找到性能和资源的平衡点。
通过如下方式可以确认缓冲大小自动调优机制的状态(0:关闭、1:开启):
- shell> sysctl -a | grep tcp_moderate_rcvbuf
如果缓冲大小自动调优机制是关闭状态,那么就把缓冲的缺省值设置为BDP;如果缓冲大小自动调优机制是开启状态,那么就把缓冲的最大值设置为BDP。
实际上这里还有一个细节问题是:缓冲里除了保存着传输的数据本身,还要预留一部分空间用来保存TCP连接本身相关的信息,换句话说,并不是所有空间都会被用来保存数据,相应额外开销的具体计算方法如下:
- Buffer / 2^tcp_adv_win_scale
依照Linux内核版本的不同,net.ipv4.tcp_adv_win_scale 的值可能是 1 或者 2,如果为 1 的话,则表示二分之一的缓冲被用来做额外开销,如果为 2 的话,则表示四分之一的缓冲被用来做额外开销。按照这个逻辑,缓冲最终的合理值的具体计算方法如下:
- BDP / (1 – 1 / 2^tcp_adv_win_scale)
此外,提醒一下延迟的测试方法,BDP中的延迟指的就是RTT,通常使用ping命令很容易就能得到它,但是如果 ICMP 被屏蔽,ping也就没用了,此时可以试试 synack。
如何调整「cwnd」到一个合理值
一般来说「cwnd」的初始值取决于MSS的大小,计算方法如下:
- min(4 * MSS, max(2 * MSS, 4380))
以太网标准的MSS大小通常是1460,所以「cwnd」的初始值是3MSS。
当我们浏览视频或者下载软件的时候,「cwnd」初始值的影响并不明显,这是因为传输的数据量比较大,时间比较长,相比之下,即便慢启动阶段「cwnd」初始值比较小,也会在相对很短的时间内加速到满窗口,基本上可以忽略不计。
不过当我们浏览网页的时候,情况就不一样了,这是因为传输的数据量比较小,时间比较短,相比之下,如果慢启动阶段「cwnd」初始值比较小,那么很可能还没来得及加速到满窗口,通讯就结束了。这就好比博尔特参加百米比赛,如果起跑慢的话,即便他的加速很快,也可能拿不到好成绩,因为还没等他完全跑起来,终点线已经到了。
举例:假设网页20KB,MSS大小1460B,如此说来整个网页就是15MSS。
先让我们看一下「cwnd」初始值比较小(等于4MSS)的时候会发生什么:
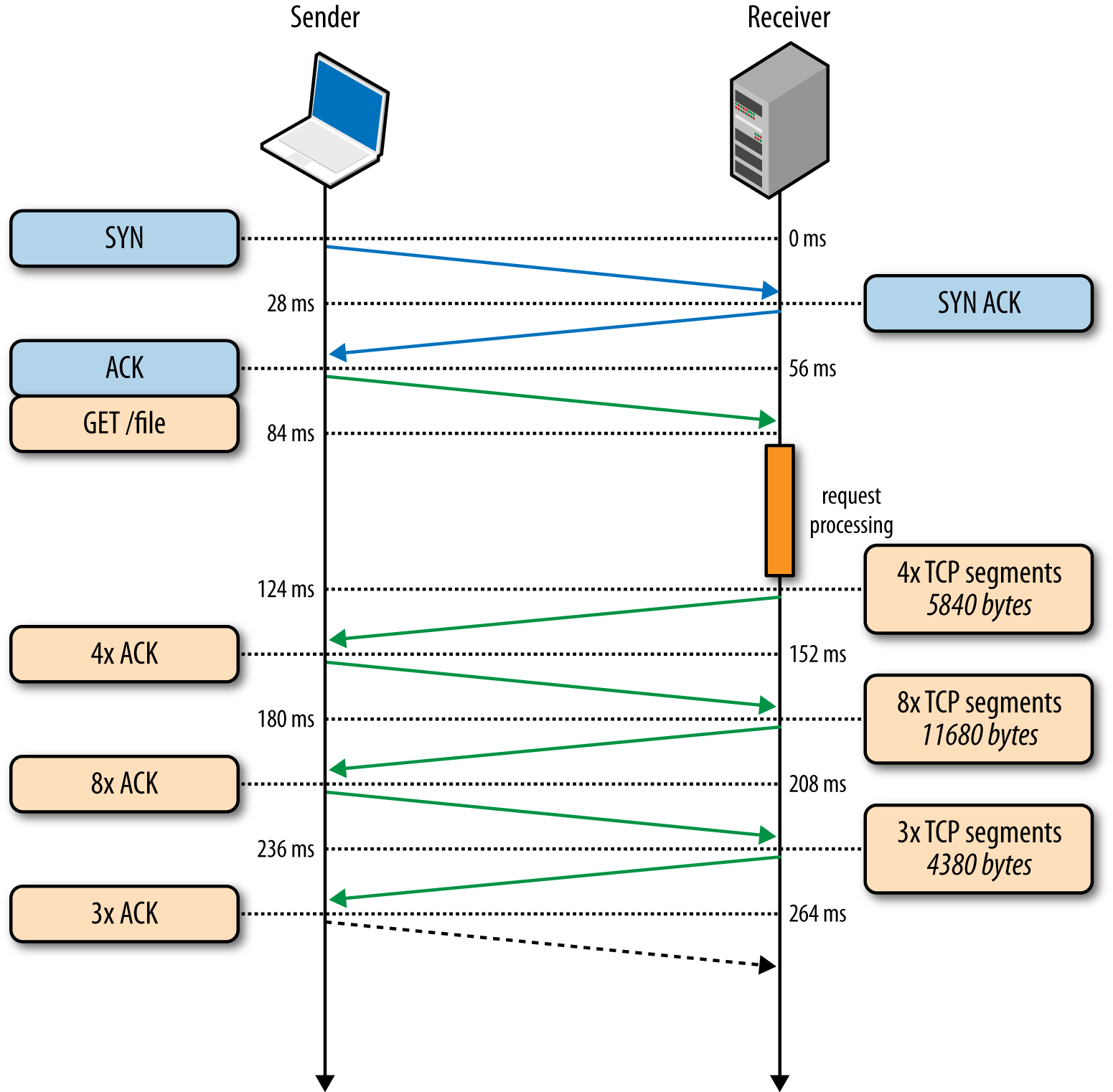
Small Window
再看一下「cwnd」初始值比较大(大于15MSS)的时候又会如何:
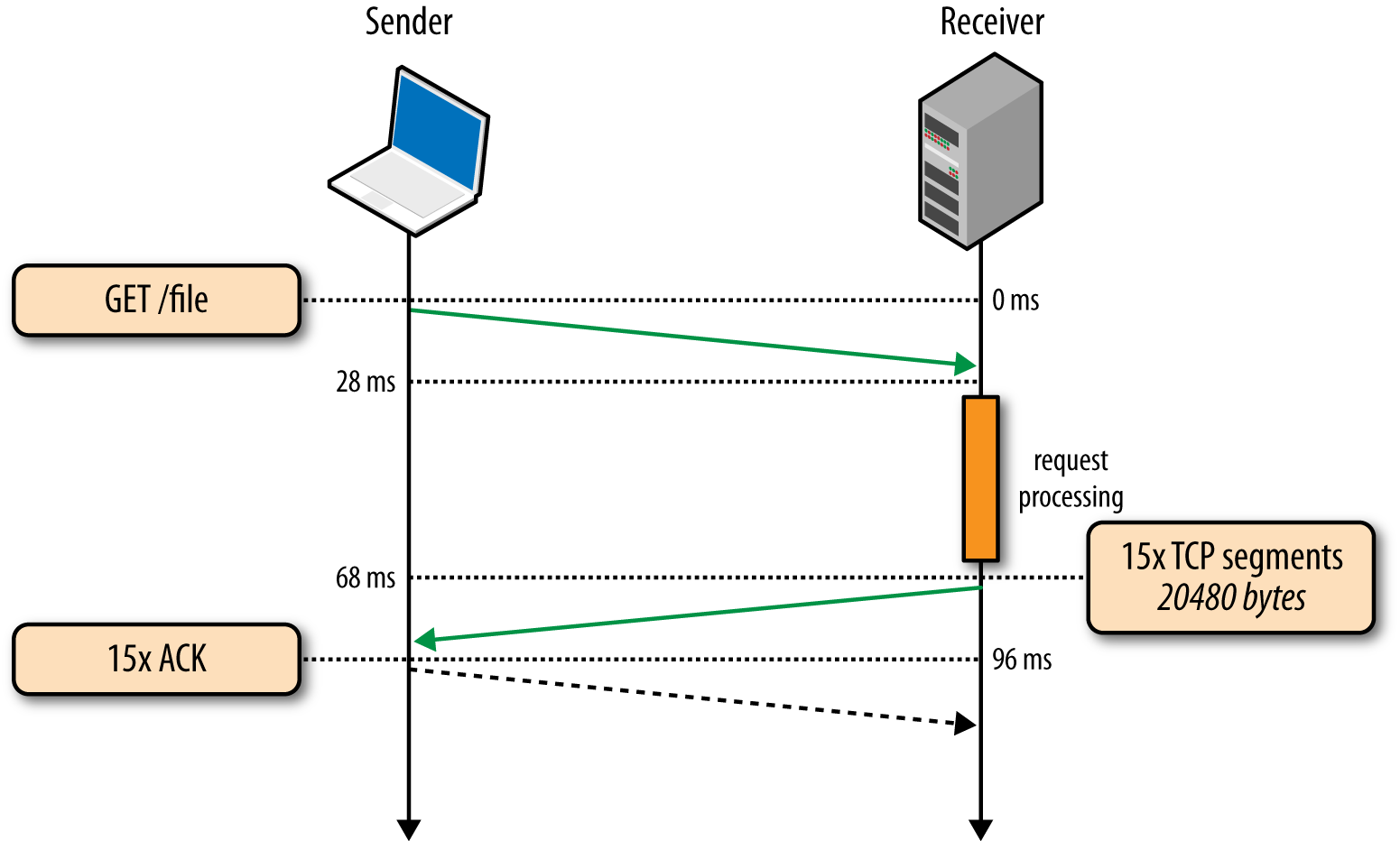
Big Window
明显可见,除去TCP握手和服务端处理,原本需要三次RTT才能完成的数据传输,当我们加大「cwnd」初始值之后,仅用了一次RTT就完成了,效率提升非常大。
推荐:大拿 mnot 写了一个名叫 htracr 的工具,可以用来测试相关的影响。
既然加大「cwnd」初始值这么好,那么到底应该设置多大为好呢?Google在这方面做了大量的研究,权衡了效率和稳定性之后,最终给出的建议是10MSS。如果你的Linux版本不太旧的话,那么可以通过如下方法来调整「cwnd」初始值:
- shell> ip route | while read p; do
- ip route change $p initcwnd 10;
- done
需要提醒的是片面的提升发送端「cwnd」的大小并不一定有效,这是因为前面我们说过网络中实际传输的未经确认的数据大小取决于「rwnd」和「cwnd」中的小值,所以一旦接收方的「rwnd」比较小的话,会阻碍「cwnd」的发挥。
推荐:相关详细的描述信息请参考:Tuning initcwnd for optimum performance。
有时候我们可能想检查一下目标服务器的「cwnd」初始值设置,此时可以数包:
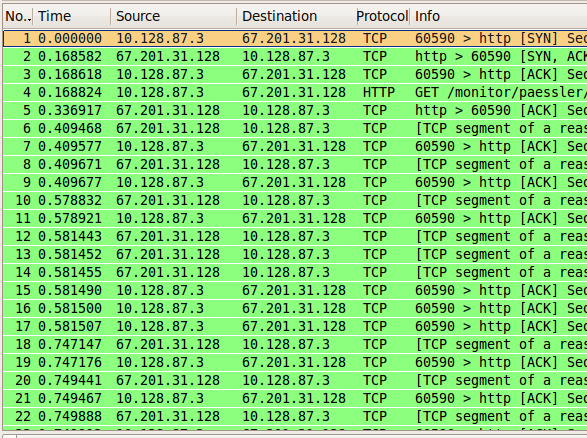
Test Initcwnd
通过握手阶段确认RTT为168,开始传输后得到第一个数据包的时间是409,加上RTT后就是577,从409到577之间有两个数据包,所以「cwnd」初始值是2MSS。
需要额外说明的是,单纯数包可能并不准确,因为网卡可能会对包做点手脚,具体说明信息请参考:Segmentation and Checksum Offloading: Turning Off with ethtool。
补充:有人写了一个名叫 initcwnd_check 的脚本,可以帮你检查「cwnd」初始值。
…
实践是检验真理的唯一标准,希望大家多动手,通过实验来检验结果,推荐一篇不错的文章:Impact of Bandwidth Delay Product on TCP Throughput,此外知乎上的讨论也值得一看:为什么多 TCP 连接分块下载比单连接下载快,大家有货的话也请告诉我。