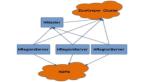
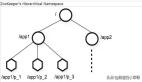
一,环境:
1,主机规划:
集群中包括3个节点:hadoop01为Master,其余为Salve,节点之间局域网连接,可以相互ping通。
|
机器名称 |
IP地址 |
|
hadoop01 |
192.168.1.31 |
|
hadoop02 |
192.168.1.32 |
|
hadoop03 |
192.168.1.33 |
三个节点上均是CentOS6.3 x86_64系统,并且有一个相同的用户hadoop。hadoop01做为master配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;另外两台配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行。安装目录统一为/usr/local下
2,软件版本:
hadoop-1.2.1.tar.gz,jdk-7u25-linux-x64.rpm
二,准备工作,三台机器都需要做 ,将三台机器selinux,iptables停用。
1,安装jdk
[root@hadoop01 ~]# rpm -ivh jdk-7u25-linux-x64.rpm
[root@hadoop01 ~]# cd /usr/java/
[root@hadoop01 java]# ls
default jdk1.7.0_25 latest
[root@hadoop01 java]# ln -s jdk1.7.0_25 jdk
[root@hadoop01 java]# vim /etc/profile

[root@hadoop01 java]# source /etc/profile 让其java命令立即生效
[root@hadoop01 java]# java 执行java命令,如果能正常执行就表示java安装完成
2,添加一个hadoop用户,用来运行hadoop集群

3,做三台机器之间做双机互信,原因master通过远程启动datanode进程和tasktracker进程,如果不做双机互信,会导致每次启动集群服务都会需要密码
[root@hadoop01 ~]# vim /etc/hosts

将hosts文件分别复制到另外两台。
4,切换到hadoop用户,对其用做双机互信,先在三台机器先执行ssh-keygen生成公钥与私钥。

将公钥复制到别的机器,需要对hadoop01,hadoop03,都做相同的动作。
[hadoop@hadoop02 ~]$ ssh-copy-id -i hadoop01
[hadoop@hadoop03 ~]$ ssh-copy-id -i hadoop01
5,同步时间,三台机器启用ntpd服务,另外两台执行相同的操作
[root@hadoop01 ~]# crontab -e
*/5 * * * * /usr/sbin/ntpdate ntp.api.bz &> /dev/null
三,配置master,也就hadoop01
[root@hadoop01 ~]# tar xf hadoop-1.2.1.tar.gz -C /usr/local/
[root@hadoop01 ~]# chown -R hadoop:hadoop /usr/local/hadoop-1.2.1
[root@hadoop01 ~]# su - hadoop
[hadoop@hadoop01 ~]$ cd /usr/local/hadoop-1.2.1/
(1)Hadoop的配置文件都存储在conf下,配置文件解释
hadoop-env.sh:用于定义hadoop运行环境相关的配置信息,比如配置JAVA_HOME环境变量、为hadoop的JVM指定特定的选项、指定日志文件所在的目录路径以及master和slave文件的位置等;
core-site.xml: 用于定义系统级别的参数,它作用于全部进程及客户端,如HDFS URL、Hadoop的临时目录以及用于rack-aware集群中的配置文件的配置等,此中的参数定义会覆盖core-default.xml文件中的默认配置;
hdfs-site.xml: HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限等,此中的参数定义会覆盖hdfs-default.xml文件中的默认配置;
mapred-site.xml:mapreduce的相关设定,如reduce任务的默认个数、任务所能够使用内存的默认上下限等,此中的参数定义会覆盖mapred-default.xml文件中的默认配置;
masters: hadoop的secondary-masters主机列表,当启动Hadoop时,其会在当前主机上启动NameNode和JobTracker,然后通过SSH连接此文件中的主机以作为备用NameNode;
slaves:Hadoop集群的slave(datanode)和tasktracker的主机列表,master启动时会通过SSH连接至此列表中的所有主机并为其启动DataNode和taskTracker进程;
Hadoop-metrics2.properties:控制metrics在hadoop上如何发布属性
Log4j.properties:系统日志文件、namenode审计日志、tarsktracker子进程的任务日志属性
(2)修改hadoop-env.sh
[hadoop@hadoop01 hadoop-1.2.1]$ vim conf/hadoop-env.sh

(3)修改core-site.xml
[hadoop@hadoop01 hadoop-1.2.1]$ vim conf/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
</configuration>
hadoop.tmp.dir属性用于定义Hadoop的临时目录,其默认为/tmp/hadoop-${username}。HDFS进程的许多目录默认都在此目录中,/hadoop/tmp目录,需要注意的是,要保证运行Hadoop进程的用户对其具有全部访问权限。
fs.default.name属性用于定义HDFS的名称节点和其默认的文件系统,其值是一个URI,即NameNode的RPC服务器监听的地址(可以是主机名)和端口(默认为8020)。其默认值为file:///,即本地文件系统。
(4)修改hdfs-site.xml文件
[hadoop@hadoop01 hadoop-1.2.1]$ vim conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/data/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
dfs.name.dir属性定义的HDFS元数据持久存储路径,默认为${hadoop.tmp.dir}/dfs/name
dfs.replication属性定义保存副本的数量,默认是保存3份,由于这里只有两台slave。所以设置2。
(5)修改mapred-site.xml文件
[hadoop@hadoop01 hadoop-1.2.1]$ vim conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://hadoop01:9001</value>
</property>
</configuration>
(6)编辑masters文件
masters用于指定,辅助名称节点(SecondaryNameNode)的主机名或主机地址
[hadoop@hadoop01 hadoop-1.2.1]$ vim conf/masters
hadoop01
(7)编辑slaves文件,这个文件只需在master主机上编辑就行
用于指定各从服务器(TaskTracker或DataNode)的主机名或主机地址
hadoop02
hadoop03
在三台机器上分别创建两个目录:
[root@hadoop01 local]# mkdir -p /hadoop/data
[root@hadoop01 local]# mkdir -p /hadoop/tmp
[root@hadoop01 local]# chown -R hadoop:hadoop /hadoop/
[root@hadoop02 local]# mkdir -p /hadoop/data
[root@hadoop02 local]# mkdir -p /hadoop/tmp
[root@hadoop02 local]# chown -R hadoop:hadoop /hadoop/
[root@hadoop03 local]# mkdir -p /hadoop/data
[root@hadoop03 local]# mkdir -p /hadoop/tmp
[root@hadoop03 local]# chown -R hadoop:hadoop /hadoop/
(8)配置slave:将配置的hadoop整个目录复制到hadoop02,haoop03
[root@hadoop01 ~]# scp -rp /usr/local/hadoop-1.2.1 hadoop02:/usr/local/
[root@hadoop01 ~]# scp -rp /usr/local/hadoop-1.2.1 hadoop03:/usr/local/
修改权限:
[root@hadoop02 ~]# chown -R hadoop:hadoop /usr/local/hadoop-1.2.1/
[root@hadoop03 ~]# chown -R hadoop:hadoop /usr/local/hadoop-1.2.1/
四,启动集群:
1、格式化名称节点
与普通文件系统一样,HDFS文件系统必须要先格式化,创建元数据数据结构以后才能使用。
[hadoop@hadoop01 hadoop-1.2.1]$ bin/hadoop namenode -format

如果格式化出错,一般会提示错误,就像下面,已经在提示哪个文件,第几行,根据提示检查即可。

[hadoop@hadoop01 ~]$ bin/start-all.sh

[hadoop@hadoop01 ~]$ jps 查看进程是否起来。secondarynamenode,nomenode,jobtracker三个进程必须都有,才正常。
8549 SecondaryNameNode
8409 NameNode
8611 JobTracker
8986 Jps
或者这种方式查看集群是否正常
[hadoop@hadoop01 hadoop-1.2.1]$ bin/hadoop dfsadmin -report
Safe mode is ON
Configured Capacity: 37073182720 (34.53 GB)
Present Capacity: 32421658624 (30.2 GB)
DFS Remaining: 32421576704 (30.19 GB)
DFS Used: 81920 (80 KB)
DFS Used%: 0%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 2 (2 total, 0 dead)
Name: 192.168.0.33:50010
Decommission Status : Normal
Configured Capacity: 18536591360 (17.26 GB)
DFS Used: 40960 (40 KB)
Non DFS Used: 2325061632 (2.17 GB)
DFS Remaining: 16211488768(15.1 GB)
DFS Used%: 0%
DFS Remaining%: 87.46%
Last contact: Sat Aug 31 22:25:13 CST 2013
Name: 192.168.0.32:50010
Decommission Status : Normal
Configured Capacity: 18536591360 (17.26 GB)
DFS Used: 40960 (40 KB)
Non DFS Used: 2326462464 (2.17 GB)
DFS Remaining: 16210087936(15.1 GB)
DFS Used%: 0%
DFS Remaining%: 87.45%
Last contact: Sat Aug 31 22:25:12 CST 2013
测试集群:
[hadoop@hadoop01 hadoop-1.2.1]$ bin/hadoop jar hadoop-test-1.2.1.jar DFSCIOTest -write -nrFiles 10 -filesize 1000
[hadoop@hadoop01 hadoop-1.2.1]$ bin/hadoop jar hadoop-test-1.2.1.jar DFSCIOTest -read -nrFiles 10 -filesize 1000
hadoop默认监听的端口:
Hadoop进程监听的地址和端口
Hadoop启动时会运行两个服务器进程,一个为用于Hadoop各进程之间进行通信的RPC服务器,另一个是提供了便于管理员查看Hadoop集群各进程相关信息页面的HTTP服务器。
用于定义各RPC服务器所监听的地址和端口的属性有如下几个:
fs.default.name:定义HDFS的NameNode用于提供URI所监听的地址和端口,默认端口为8020;
dfs.datanode.ipc.address:DataNode上RPC服务器监听的地址和端口,默认为0.0.0.0:50020;
mapred.job.tracker:JobTracker的PRC服务器所监听的地址和端口,默认端口为8021;
mapred.task.tracker.report.address:TaskTracker的RPC服务器监听的地址和端口;TaskTracker的子JVM使用此端口与TaskTracker进行通信,它仅需要监听在本地回环地址127.0.0.1上,因此可以使用任何端口;只有在当本地没有回环接口时才需要修改此属性的值;
除了RPC服务器之外,DataNode还会运行一个TCP/IP服务器用于数据块传输,其监听的地址和端口可以通过dfs.datanode.address属性进行定义,默认为0.0.0.0:50010。
可用于定义各HTTP服务器的属性有如下几个:
dfs.http.address:NameNode的HTTP服务器地址和端口,默认为0.0.0.0:50070;
dfs.secondary.http.address:SecondaryNameNode的HTTP服务器地址和端口,默认为0.0.0.0:50090;
mapred.job.tracker.http.addrss:JobTracker的HTTP服务器地址和端口,默认为0.0.0.0:50030;
dfs.datanode.http.address:DataNode的HTTP服务器地址和端口,默认为0.0.0.0:50075;
mapred.task.tracker.http.address:TaskTracker的HTTP服务器地址和端口,默认为0.0.0.0:50060;上述的HTTP服务器均可以通过浏览器直接访问以获取对应进程的相关信息,访问路径为http://Server_IP:Port。如namenode的相关信息:

四,排错思路
1,是否是hadoop.tmp.dir,dfs.data.dir属性,如果定义在别的目录需要在集群中所有节点都创建,并让hadoop用户能够访问
2,查看进程对应的端口是否有在监听。在上面配置中将namenode的端口定义9000,jobtracker定义成9001
[hadoop@hadoop01 hadoop-1.2.1]$ netstat -tunlp |grep 9000
tcp 0 0 ::ffff:192.168.0.31:9000 :::* LISTEN 22709/java
[hadoop@hadoop01 hadoop-1.2.1]$ netstat -tunlp |grep 9001
tcp 0 0 ::ffff:192.168.0.31:9001 :::* LISTEN 22924/java
3,查看日志,哪个服务没起来就查看对应的日志。
4,查看集群中所有节点的时间是不是一致。
5,iptable与selinux是否阻止。
6,/etc/hosts是否正确。
五,添加节点,删除节点
添加节点
1.修改host
和普通的datanode一样。添加namenode的ip
2.修改namenode的配置文件conf/slaves
添加新增节点的ip或host
3.在新节点的机器上,启动服务
[hadoop@hadoop04 hadoop]# ./bin/hadoop-daemon.sh start datanode
[hadoop@hadoop04 hadoop]# ./bin/hadoop-daemon.sh start tasktracker
4.均衡block
[hadoop@hadoop04 hadoop]# ./bin/start-balancer.sh
1)如果不balance,那么cluster会把新的数据都存放在新的node上,这样会降低mapred的工作效率
2)设置平衡阈值,默认是10%,值越低各节点越平衡,但消耗时间也更长
[root@slave-004 hadoop]# ./bin/start-balancer.sh -threshold 5
3)设置balance的带宽,默认只有1M/s
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>1048576</value>
<description>
Specifies the maximum amount of bandwidth that each datanode
can utilize for the balancing purpose in term of
the number of bytes per second.
</description>
</property>
注意:
1. 必须确保slave的firewall已关闭;
2. 确保新的slave的ip已经添加到master及其他slaves的/etc/hosts中,反之也要将master及其他slave的ip添加到新的slave的/etc/hosts中
删除节点
1.集群配置
修改conf/hdfs-site.xml文件
<property>
<name>dfs.hosts.exclude</name>
<value>/data/soft/hadoop/conf/excludes</value>
<description>Names a file that contains a list of hosts that are
not permitted to connect to the namenode. The full pathname of the
file must be specified. If the value is empty, no hosts are
excluded.</description>
</property>
2确定要下架的机器
dfs.hosts.exclude定义的文件内容为,每个需要下线的机器,一行一个。这个将阻止他们去连接Namenode。如:
haoop04
3.强制重新加载配置
[root@master hadoop]# ./bin/hadoop dfsadmin -refreshNodes
它会在后台进行Block块的移动
4.关闭节点
等待刚刚的操作结束后,需要下架的机器就可以安全的关闭了。
[root@master hadoop]# ./bin/ hadoop dfsadmin -report
可以查看到现在集群上连接的节点
正在执行Decommission,会显示:
Decommission Status : Decommission in progress
执行完毕后,会显示:
Decommission Status : Decommissioned
5.再次编辑excludes文件
一旦完成了机器下架,它们就可以从excludes文件移除了
登录要下架的机器,会发现DataNode进程没有了,但是TaskTracker依然存在,需要手工处理一下
六,安装zookeeper:
1,zookeeper概述:
ZooKeeper是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization)、命名服务(Naming Service)、集群维护(Group Maintenance)等,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。ZooKeeper本身可以以Standalone模式安装运行,不过它的长处在于通过分布式ZooKeeper集群(一个Leader,多个Follower),基于一定的策略来保证ZooKeeper集群的稳定性和可用性,从而实现分布式应用的可靠性。
hadoop01为zookeeper1,hadoop02为zookeeper2,hadoop03为zookeeper3。zookeerper
2,下载zookeeper-3.4.4解压到/usr/local/下,并修改权限
# chown -R hadoop:hadoop /usr/local/zookeeper-3.4.4/
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/hadoop/zookeeper
# the port at which the clients will connect
clientPort=2181
server.1=hadoop01:28888:38888
server.2=hadoop02:28888:38888
server.3=hadoop03:28888:38888
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
注解:
tickTime发送心跳时间间隔,单位毫秒
initlimit和sysnclimit,两者都是以ticktime的总数进行度量(上面的时间为10*2000=20s)。initLimit参数设定了允许所有跟随者与***进行连接并同步的时间,如果在设定的时间内内,半数以上的跟随者未能完成同步,***便会宣布放弃领导地位,然后进行另外一次***选举。如果这种情况经常发生,通过查看日志中的记录发现,则表明设定的值太小。
syscLimit参数设定了允许一个跟随者与***进行同步的时间。如果在设定的时间内,一个跟随者未能完成同步,它将会自己重启,所有关联到这个跟随者的客户端将连接到另外一个跟随者。
datadir保存的zk中持久化的数据,zk中存在两种数据,一种用完即消失,一种需要持久存在,zk的日志也保存在这
[hadoop@hadoop01 ~]$ mkdir /hadoop/zookeeper/
[hadoop@hadoop01 ~]$ echo "1" > /hadoop/zookeerper/myid
将zookeeper目录分别复制到hadoop02,hadoop03,并创建/hadoop/zookeeper目录,并在其目录下创建其myid。
3,在对应的节点上启动服务
[hadoop@hadoop01 zookeeper-3.4.4]$ sh bin/zkServer.sh start
三个节点启动完之后,查看
[hadoop@hadoop01 zookeeper-3.4.4]$ jps
1320 NameNode
2064 Jps
1549 JobTracker
1467 SecondaryNameNode
1996 QuorumPeerMain
[hadoop@hadoop01 zookeeper-3.4.4]$ sh bin/zkServer.sh status 查看当前节点是否是leader
[hadoop@hadoop01 zookeeper-3.4.4]$ sh bin/zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.4/bin/../conf/zoo.cfg
Mode: follower 表示是跟从
七,安装hbase
HBase集群需要依赖于一个Zookeeper ensemble。HBase集群中的所有节点以及要访问HBase
的客户端都需要能够访问到该Zookeeper ensemble。HBase自带了Zookeeper,但为了方便
其他应用程序使用Zookeeper,***使用单独安装的Zookeeper ensemble。
此外,Zookeeper ensemble一般配置为奇数个节点,并且Hadoop集群、Zookeeper ensemble、
HBase集群是三个互相独立的集群,并不需要部署在相同的物理节点上,他们之间是通过网
络通信的。
一,下载hbase-0.94.1 ,并解压到/usr/local下,hbase的版本需要与hadoop对应,查看是否对应只需要看hbase-0.94.1/lib/hadoop-core后面的版本号是否与hadoop的版本对应,如果不对应,可以将hadoop下hadoop-core文件复制过来,但是不能保证不会有问题
[hadoop@master hbase-0.94.12]$ vim conf/hbase-env.sh
export JAVA_HOME=/usr/java/jdk
export HBASE_CLASSPATH=/usr/local/hadoop-1.0.4/conf
export HBASE_MANAGES_ZK=false
export HBASE_HEAPSIZE=2048
tips:
其中,HBASE_CLASSPATH指向存放有Hadoop配置文件的目录,这样HBase可以找到HDFS
的配置信息,由于本文Hadoop和HBase部署在相同的物理节点,所以就指向了Hadoop安
装路径下的conf目录。HBASE_HEAPSIZE单位为MB,可以根据需要和实际剩余内存设置,
默认为1000。HBASE_MANAGES_ZK=false指示HBase使用已有的Zookeeper而不是自带的。
[root@hadoop01 ~]# source /etc/profile
在hbase-094.1/src/main/resources/hbasse-default.xml可以将这个文件复制到conf目录下,进行修改
[hadoop@hadoop01 hbase-0.94.1]$ vim conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop01:9000/hbase</value>
<description>The directory shared by region servers.</description>
</property>
<property>
<name>hbase.hregion.max.filesize</name>
<value>1073741824</value>
<description>
Maximum HStoreFile size. If any one of a column families' HStoreFiles has
grown to exceed this value, the hosting HRegion is split in two.
Default: 256M.
</description>
</property>
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
<description>
Memstore will be flushed to disk if size of the memstore
exceeds this number of bytes. Value is checked by a thread that runs
every hbase.server.thread.wakefrequency.
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed Zookeeper
true: fully-distributed with unmanaged Zookeeper Quorum (see hbase-env.sh)
</description>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
<description>Property from ZooKeeper's config zoo.cfg.
The port at which the clients will connect.
</description>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<property>
<name>hbase.zookeeper.property.tickTime</name>
<value>6000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01,hadoop02,hadoop03</value>
<description>Comma separated list of servers in the ZooKeeper Quorum.
For example, "host1.mydomain.com,host2.mydomain.com,host3.mydomain.com".
By default this is set to localhost for local and pseudo-distributed modes
of operation. For a fully-distributed setup, this should be set to a full
list of ZooKeeper quorum servers. If HBASE_MANAGES_ZK is set in hbase-env.sh
this is the list of servers which we will start/stop ZooKeeper on.
</description>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/hadoop/hbase</value>
</property>
</configuration>
注释:
1,hbase.rootdir:hbase所使用的文件系统为HDFS,根目录为hdfs://node0:9000/hbase,该目录应该由HBase自动创建,只需要指定到正确的HDFS NameNode上即可。
2,hbase.hregion.max.filesize:设置HStoreFile的大小,当 大于这个数时,就会split 成两个文件
3,hbase.hregion.memstore.flush.size:设置memstore的大小,当大于这个值时,写入磁盘
4,hbase.cluster.distributed:指定hbase为分布式模式
5,hbase.zookeeper.property.clientPort:指定zk的连接端口
6,zookeeper.session.timeout:RegionServer与Zookeeper间的连接超时时间。当超时时间到后,ReigonServer会被Zookeeper从RS集群清单中移除,HMaster收到移除通知后,会对这台server负责的regions重新balance,让其他存活的RegionServer接管.
7,hbase.zookeeper.property.tickTime:
8,hbase.zookeeper.quorum:默认值是 localhost,列出zookeepr的ensemble servers
9,hbase.regionserver.handler.count:
默认值:10
说明:RegionServer的请求处理IO线程数。
调优:
这个参数的调优与内存息息相关。
较少的IO线程,适用于处理单次请求内存消耗较高的Big PUT场景(大容量单次PUT或设置了较大cache的scan,均属于Big PUT)或ReigonServer的内存比较紧张的场景。
较多的IO线程,适用于单次请求内存消耗低,TPS要求非常高的场景。设置该值的时候,以监控内存为主要参考。
这里需要注意的是如果server的region数量很少,大量的请求都落在一个region上,因快速充满memstore触发flush导致的读写锁会影响全局TPS,不是IO线程数越高越好。
压测时,开启Enabling RPC-level logging,可以同时监控每次请求的内存消耗和GC的状况,***通过多次压测结果来合理调节IO线程数。
这里是一个案例?Hadoop and HBase Optimization for Read Intensive Search Applications,作者在SSD的机器上设置IO线程数为100,仅供参考。
10,hbase.tmp.dir:指定HBase将元数据存放路径
[hadoop@hadoop01 hbase-0.94.1]$ vim conf/regionservers 相当于hadoop的slave
hadoop02
hadoop03
11,启动所有hbase进程
[hadoop@master hbase-0.94.12]$ bin/start-hbase.sh
12,停止
[hadoop@master hbase-0.94.12]$ bin/stop-hbase.sh
13,连接hbase创建表
[hadoop@master hbase-0.94.12]$ bin/hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.94.12, r1524863, Fri Sep 20 04:44:41 UTC 2013
hbase(main):001:0>
14,创建一个名为 small的表,这个表只有一个 column family 为 cf。可以列出所有的表来检查创建情况,然后插入些值。
hbase(main):003:0> create 'small', 'cf'
0 row(s) in 1.2200 seconds
hbase(main):003:0> list
small
1 row(s) in 0.0550 seconds
hbase(main):004:0> put 'small', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0560 seconds
hbase(main):005:0> put 'small', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0370 seconds
hbase(main):006:0> put 'small', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0450 seconds
15、检查插入情况.Scan这个表
hbase(main):005:0> scan 'small'
Get一行,操作如下
hbase(main):008:0> get 'small', 'row1'
disable 再 drop 这张表,可以清除你刚刚的操作
hbase(main):012:0> disable 'small'
0 row(s) in 1.0930 seconds
hbase(main):013:0> drop 'small'
0 row(s) in 0.0770 seconds
16,导出与导入
[hadoop@master hbase-0.94.12]$ bin/hbase org.apache.hadoop.hbase.mapreduce.Driver export small small
导出的表,在hadoop文件系统的当前用户目录下,small文件夹中。例如,导出后在hadoop文件系统中的目录结构:
[hadoop@master hadoop-1.0.4]$ bin/hadoop dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2013-10-22 10:44 /user/hadoop/small
[hadoop@master hadoop-1.0.4]$ bin/hadoop dfs -ls ./small
Found 3 items
-rw-r--r-- 2 hadoop supergroup 0 2013-10-22 10:44 /user/hadoop/small/_SUCCESS
drwxr-xr-x - hadoop supergroup 0 2013-10-22 10:44 /user/hadoop/small/_logs
-rw-r--r-- 2 hadoop supergroup 285 2013-10-22 10:44 /user/hadoop/small/part-m-00000
2.把这个表导入到另外一台集群中hbase中时,需要把part-m-00000先put到另外hadoop中,假设put的路径也是:
/user/hadoop/small/
而且,这个要导入的hbase要已经建有相同第表格。
那么从hadoop中导入数据到hbase:
#hbase org.apache.hadoop.hbase.mapreduce.Driver import small part-m-00000
这样,没有意外的话就能正常把hbase数据导入到另外一个hbase数据库。
17.Web UI
用于访问和监控Hadoop系统运行状态
|
Daemon |
缺省端口 |
配置参数 |
|
|
HDFS |
Namenode |
50070 |
dfs.http.address |
|
Datanodes |
50075 |
dfs.datanode.http.address |
|
|
Secondarynamenode |
50090 |
dfs.secondary.http.address |
|
|
Backup/Checkpoint node* |
50105 |
dfs.backup.http.address |
|
|
MR |
Jobracker |
50030 |
mapred.job.tracker.http.address |
|
Tasktrackers |
50060 |
mapred.task.tracker.http.address |
|
|
HBase |
HMaster |
60010 |
hbase.master.info.port |
|
HRegionServer |
60030 |
hbase.regionserver.info.port |


本文出自 “smalldeng” 博客,请务必保留此出处http://smalldeng.blog.51cto.com/1038075/1329290