












作为本年度***看点的Hadoop***盛宴,2013 Hadoop中国技术峰会即将于11月22日-23日在北京福朋喜来登大酒店盛大开幕.大会集结了近千名CIO、CTO、架构师、IT经理、咨询顾问、工程师、Hadoop技术爱好者,以及从事Hadoop研究与推广的IT厂商和技术专家,届时将分享Hadoop相关的热点话题。
IDC预测,中国未来几年,会有越来越多的企业级用户试水大数据平台和应用,而Hadoop被看成大数据分析的“神器”,将成为最耀眼的“明星”。Hadoop相关的数据应用遍地开花,在各行各业做得风生水起。仅以互联网为例,目前京东、淘宝、腾讯、百度、Amazon、一淘、人人、优酷、搜狐、搜狗、暴风影音、Ebay、乐视、PPTV、小米等IT企业都亲自操刀,利用Hadoop 大干一场。 正所谓时势造英雄,大数据时代是一个英雄辈出的时代,十名Committer齐聚京城,届时Hadoop行业英雄谱将唱响2013 Hadoop中国技术峰会的现场。我们为大家爆料了五个颇具代表的Hadoop行业案例,为您分享2013 Hadoop中国技术峰会的精彩内容。大会官网:http://www.chinahadoop.com/
Hortonworks 再续前缘: Hadoop 2.0 强势来袭
俗话说得好,“聪明绝顶!”2013 Hadoop中国技术峰会特邀的这位光头老外就是大名鼎鼎的Hortonworks公司的亚太技术总监Jeff Markham。大数据分析服务公司Hortonworks乃名门雅虎之后,它与雅虎联手贡献了Hadoop主干项目80%以上的源码。此外,Hortonworks公司还被认为是 Hadoop 2.0、Apache Hadoop Yarn的主要贡献者。
在本次2013 Hadoop中国技术峰会中,Jeff演讲的重要主题之一是Hadoop2——Yarn。谈到YARN的诞生,Jeff表示,旧版MapReduce的JobTracker/TaskTracker机制需要通过大规模的调整来修复它在可扩展性、内存消耗、线程模型、可靠性和性能方面的缺陷。Hortonworks在着手构建Hadoop2.0时,希望从根本上重新设计Hadoop的架构,从而达到可以在Hadoop上运行多个应用程序并处理相关数据集的目的。这样一来,多种类型的应用程序都可以高效、可控地运行在同一个集群上。这是以Hadoop 2.0为基础的Apache YARN之所以能够诞生的真正原因。
京东在电商行业的淘金利器 :利用Hadoop在大数据领域大展拳脚
也许Jeff错过了中国网购的“龙卷风”,相信他还来不及体验中国的双十一有多么地疯狂。不过没关系,如果您有机会参加2013 Hadoop中国技术峰会,不妨晒晒双十一那些可圈可点的网购吸金数字,160万个文胸高过3个珠穆朗玛峰,9小时销售的纸尿裤可以吸干6个西湖。相信精明的他会利用这个机会找京东的人推销一下YARN。
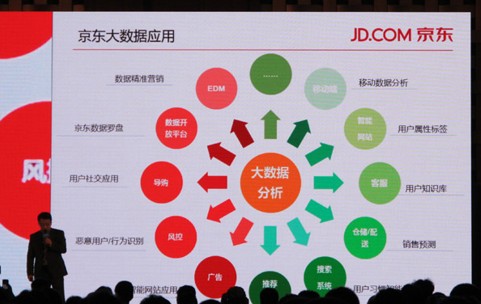
互联网行业,谁掌握了用户数据,谁就有资本赚钱。以低价、正品行货而跻身电商巨头行业的电商京东吸引了大批的粉丝,十年来积累了上亿个宝贵价值的用户数据。传统公司如银行、保险机构、电信企业等,它们的数据大多都是结构化的;而互联网公司像百度、腾讯等企业的数据,多来源于网络评论、用户日志等,这些数据是非结构化或半结构化的。京东之类的电商企业的数据处于二者之间:从用户下单到仓储分拣,再到配送,整个交易链条上的数据是结构化的;而用户的网站浏览行为、购买评价等各种数据是非结构化的。京东需要做的是将结构化和非结构化的数据巧妙的融合起来,从而实现客户洞察、用户定位、风险评估等一系列与大数据有关的分析和决策行为。
在电商淘金热潮中,大数据已经成为了京东所向披靡的竞争利器。如何利用大数据来挖掘这十年积累的数据,为企业提供决策支持,支持京东更好更大的发展,是摆在京东Hadoop团队面前的核心难题。为此,2013 Hadoop中国技术峰会同时邀请了3位资深京东Hadoop技术专家,从各个维度深入剖析京东的大数据Hadoop应用,包括营销体系、广告推放、仓储调拨、销售预测,物流配送等。举个例子,用户没有来的时候有货,这并不表明用户来的时候一定会有货。京东需要对用户访问量和商品数据进行分析,整合出一个较为准确的现货率,实时提供给采购部门备货,从而优化用户体验。
如何在合适的时间向目标客户推送正确的内容?几乎所有的电商企业都会基于用户的购买行为做精准营销。京东也不例外,每天都会产生几亿的PV,但其先进的Hadoop的数据分析手段盖过了简单的E-mail与短信势头。京东依靠大数据对用户建模,进行正确的画像分析、定位模型。简单来讲,京东利用Hadoop对对用户海量评论和搜索日志的分析和挖掘,包括性别、年龄、是否有房有车等多个维度,制定大数据分析模型,从而判断用户是购买冲动型还是目标明确性,理解用户的购买意图,然后根据不同用户属性推荐不同的商品,从而提升用户体验,给用户带来了更多的价值。
小米进军云服务行业:大力发展HBase技术
如果说58是个神奇的网站,那么小米就是一个神奇的公司。对比一下,历经百年的老牌诺基亚加上全部专利的总资产才72亿,而成立不久的小米估值造就超过了100亿美元。 谈起小米,它的饥饿营销法在中国市场可谓如火如荼,就连苹果的黄牛都开始囤积小米了。相比于小米手机,小米大数据显得并不张扬,但这丝毫不影响它在大数据领域的实力。这不,HBase的总牵头人Michael Stack就专程来看看这个神奇的公司。要知道,小米云服务的大部分结构性数据都是采用HBase的延伸技术存储,小米提交了65项HBase的补丁,其中37项已经被并入HBase主代码树。而作为小米大数据团队而言,当然也不会错过中国最有价值的Hadoop技术盛宴——2013 Hadoop中国技术峰会这个平台,来为大家现场分享小米云服务是如何运用HBase相关技术的。
大数据在视频中的数字游戏:优酷土豆利用Hadoop挖掘数据中的价值
视频似乎是看不完的,看完一个视频,会有一个又一个的相关的视频推荐,视频行业俨然成为了大数据时代的先锋。优酷土豆作为一家耳熟能详的大型视频网站,拥有海量的视频文件。有这样一种技术,亚马逊和谷歌都在用,亚马逊会告诉你“买了A商品的顾客也同时购买了B商品”,Youtube上,一个视频播放结束,马上就会出现相关推荐视频。同样,优酷也就靠着这种基于Hadoop的“协同过滤推荐”的技术给用户推荐他们喜欢看的视频。
正所谓燕雀安知鸿鹄之志哉?当然,优酷土豆并不满足于把数据的挖掘分析只用在简单的推荐视频上,优酷土豆希望能够在行业内树立一个标杆,作为它的拳头性平台化战略产品“中国网络视频指数”更是成为了大数据时代的弄潮儿。
优酷土豆拥有海量的数据,仅运营数据,目前每天收集到的网站各类访问日志总量已经达到TB级,经分析及压缩处理后留存下来的历史运营数据已达数百TB,很快将飙升到 PB级,5年后数据量将会突破几十PB级。如何更好地处理和分析这些海量数据?如何在海量数据中掘金?这将成为优酷土豆值得花力气研究的事情。
在本届2013 Hadoop中国技术峰会中,来自优酷土豆的Hadoop技术专家将现场剖析Hadoop在广告、网站、无线、搜索等方面的应用。在优酷土豆平台上,每当用户点击播放视频时,优酷土豆都会对页面浏览、评论收藏、视频播放以及播放时的各种操作进行了记录。这些数据经处理后的分析结果会反馈给不同相关业务模块用作参考,来自产品、内容运营、用户的个性化推荐及广告投放等业务部门都会受益匪浅。
内容方面,优酷土豆通过对用户网络情况进行数据统计:比如每次播放是否发生了缓冲,平均下载速度是多少等,凭借对这些数据进行实时的统计和计算,获取每个地区每个运营商下用户的加载表现,以此来决定CDN节点的分布和分配策略,为不同地区、不同运营商的用户提供清晰流畅的视频服务。
在推荐方面,优酷土豆通过对大量视频播放行为的分析,归纳不同时长、不同类型、不同内容的视频之间的相互关联,挖掘不同人群用户的同质化观看习惯,对每次用户的观看进行有针对性的后续推荐,并借助后续数据的分析,迭代地改善现有服务,为用户提供量身定制的推送服务。
VMWare 领跑虚拟化行业:Hadoop的大数据扩展技术更胜一筹
作为虚拟化技术的旗帜,VMware始终领跑虚拟化与云计算的发展。不过,VMWare的雄心远不止如此。VMWare开始发力Hadoop虚拟化相关技术。近日,VMware宣布推出了VMware vSphere Big Data Extensions(大数据扩展),这将允许该公司广受欢迎的基础设施管理软件来控制企业客户建立的Hadoop集群。这样一来,成千上万的VMware企业客户将能够使用他们已经熟悉的软件来控制Hadoop部署。
为此,2013 Hadoop中国技术峰会组委会特意邀请了两位VMWare重量级技术专家,为您庖丁解牛,讲解VMware的大数据方案。
创投资金给了谁?谁能获得自己的一桶金?
2013上半年IDG、红杉们的钱都给了谁?大数据成为了投资最热关键词,互联网以信息为本,在大数据领域,做数据分析、挖掘等相关技术备受青睐。值得一提的是,2013 Hadoop中国技术峰会特别增设了一个大数据创业与投资的主题论坛,新浪微博基金、美国光速创业投资、IDG资本投资顾问(北京)有限公司、中通银泰、星环信息(上海)有限公司、Xadoop、天云大数据、云创存储等单位将共同分享大数据领域的创业和投资方面的故事,希望能同时帮助到创业者和投资者。现在团队购票还有优惠,欲想了解详细议程,请访问www.chinahadoop.com /hadoop.it168.com。今年销售一如既往的火爆,若不想等门票售罄,请及早预定。












