













2013年8月3日《天空之城》在日本的热播创下每秒新增143119条推文的Twitter峰值记录,是Twitter平均每秒发推数(TPS)5700条的25倍。
值得注意的是,在这次毫无征兆的“洪峰”到来时,Twitter全新的系统平台并没有被潮水般涌来的推文堵塞而产生任何延迟甚至宕机。
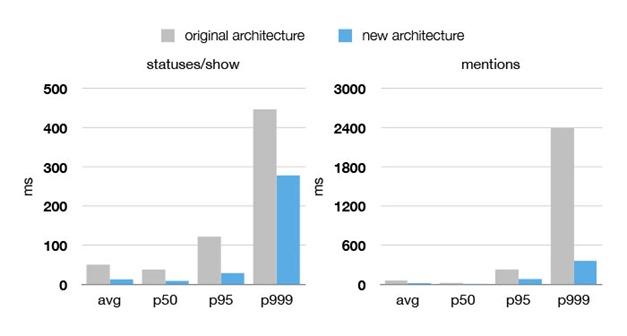
Twitter旧架构与新架构的性能对比
仅仅三年前,在2010年世界杯上,一个点球和一张红牌产生的“推文风暴”都可能导致Twitter服务暂时失去响应,号称地球脉搏的Twitter 经常“心肌梗塞”。过去三年Twitter的工程师们夜以继日的工作,试图用“缝缝补补”的方式完善Twitter系统,但最终随着Twitter的快速 发展,这些方法的收效转瞬即逝。
最终,Twitter痛下决心重新架构为人诟病的IT系统,新平台上线运行后在性能和可靠性上都取得的翻天覆地的进步。无论是《天空之城》热播还是超 级碗决赛都没能卡住Twitter,而且新的架构也为Twitter推出多媒体推文卡片,跨设备消息同步等新功能的推出提供了有力的支撑。
最近,Twitter平台工程副总裁Raffi Krikorian(@raffi)在Twitter官方博客 撰文分享了Twitter新架构的方法和经验,摘要如下:
重新架构的缘由与问题症结
2010年世界杯多次卡壳后,我们重新审视了系统,有以下几点发现:
我们运行着全球最大的Ruby on Rails应用,200名工程师负责开发运维这个系统,但随着用户规模和服务数量的快速增长,系统所有的数据库管理、Memcache链接以及公共API 的代码属于同一个代码库。这给工程师的学习、管理和并行开发都带来巨大困难。
我们的MySQL存储系统已经遇到性能瓶颈。整个数据库中到处都是读写热点。
通过添置硬件已经无法解决根本的系统问题——我们的前端Ruby服务器每秒处理交易的数量大大低于我们的预期,也与其硬件性能不成比例。
从软件的角度看,我们陷入了“优化的陷阱”。我们是在牺牲代码库的可读性和灵活性来换取性能和效率。
重新检视系统,并设定三大目标/挑战
一、新架构必须在性能、效率和可靠性上表现优异,减少延迟大幅提升客户体验;同时将服务器数量减少到原来的十分之一;新系统能够隔离硬件问题防止其演变为大规模宕机。
二、解决单一代码库的种种弊端,尝试松耦合的面向服务模型。我们的目标是鼓励封装与模块化的最佳实践,但这次是在系统层面,而不是类库、模块和数据包的层面。
三、最重要的是能够支持新功能的快速发布。我们希望能够由一些充分授权的小团队能做出自主决策,并独立发布一些用户功能。
我们在动手前部分开发了一些概念验证模型,最终我们确定了重建的原则、工具和架构。
系统重建的关键措施
一、前端服务:用JVM取代Ruby VM。通过重写代码库将Ruby VM服务移植到JVM,性能提高了10倍,如今性能达到 10-20k请求/秒/主机。
二、编程模型:按服务类型对系统进行结构,建立一个统一的客户端服务器库并与负载均衡、故障转移策略等绑定,从而让工程师们能更加专注于应用和服务界面。
三、采用SOA面向服务架构,使并行开发成为可能。
四、推文的分布式存储。即使将整块单一应用分解成不同的“服务”,存储依然是个巨大的瓶颈。过去Twitter采用的单一MySQL主数据库只能线性 写入推文,Twitter决定在推文的存储上采用全新的分区策略,用Gizzard框架创建容错的分片分布式数据库存储推文,但这样一来就没有办法使用 MySQL的唯一ID生成功能。Twitter用 Snowflake解决了这个问题。
五、监测与统计。将单一应用转化为复杂的SOA应用后,需要购买匹配的工具才能够驾驭。Twitter的服务推出速度很快,同时还需要实现数据化的决策支持,Twitter的Runtime系统团队为工程师开发了两个工具Viz和 Zipkin。
















