虚拟化为Hadoop注入了前所未有的活力,从IT生产管理的角度,表现为以下几点:
·Hadoop和其他消耗不同类型资源的应用一起部署共享数据中心可以提高总体资源利用率;
·灵活的虚拟机操作使得用户可以动态的根据数据中心资源创建、扩展自己的Hadoop集群,也可以缩小当前集群、释放资源支持其他应用如果需要;
·通过与虚拟化架构提供的HA、FT集成,避免了传统Hadoop集群中的单点失败,再加之Hadoop本身的数据可靠性,为企业大数据应用提供了可靠保证。
基于这些原因,vSphere Big Data Extensions(BDE)为用户在虚拟化环境中灵活的部署和管理Hadoop集群提供了有效的支持。除却这些优势,虚拟化是否会伤害Hadoop运行的性能呢?为此,我们在同等规模上做了虚拟化部署和物理部署的Hadoop集群的性能对比和优化,实验表明虚拟化Hadoop集群可以很好地支持生产环境。
虚拟化环境和物理环境的性能对比
图1显示了性能调优试验的部署样式,一台物理服务器上只部署一台虚拟机,Tasktracker和Datanode一起跑在同一个节点中。因为每个虚拟节点可以使用全部的服务器资源,方便进行虚拟化和传统物理环境部署的Hadoop做性能对比和分析。试验结果在图2中显示,虚拟化Hadoop相对于物理环境的性能对比几乎是持平的。
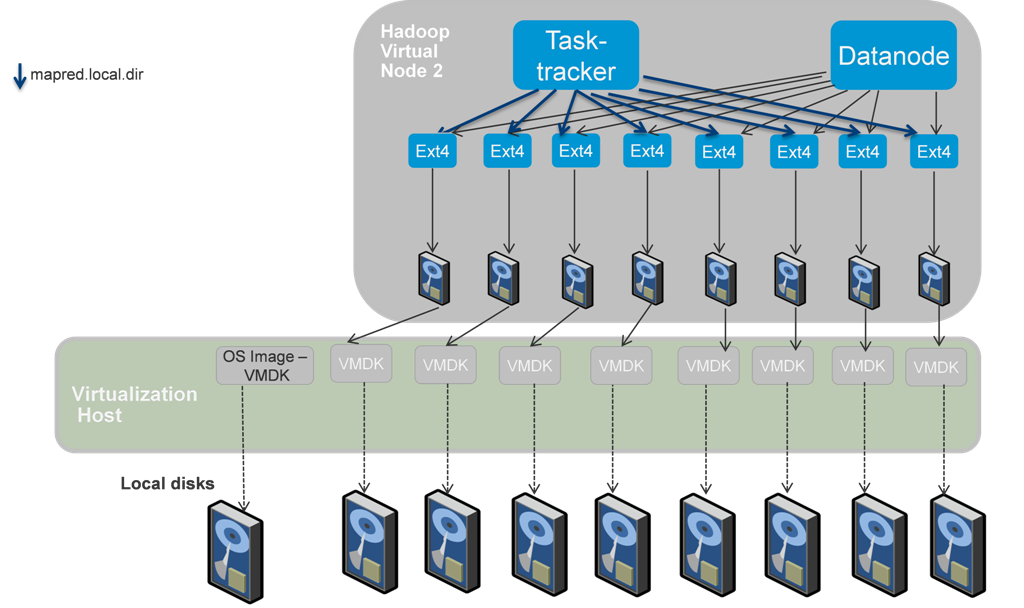
图1:性能对比部署
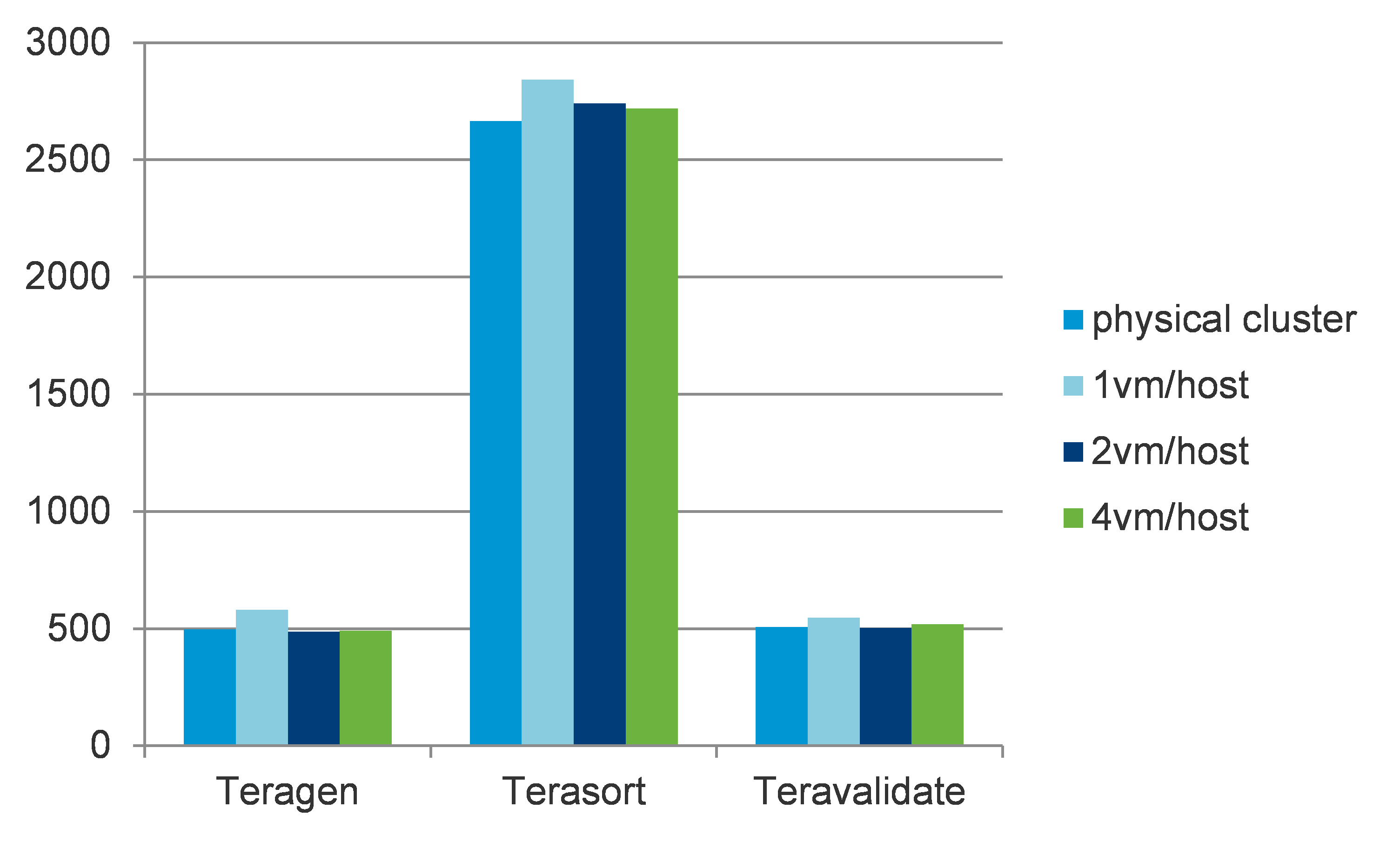
图2:Apache Hadoop 1.2物理部署和虚拟化部署的性能对比
图3显示了更推荐生产环境使用的部署拓扑,一台物理服务器上部署多台虚拟节点。如图2所示,这种部署将增加资源利用率从而得到更高的性能。
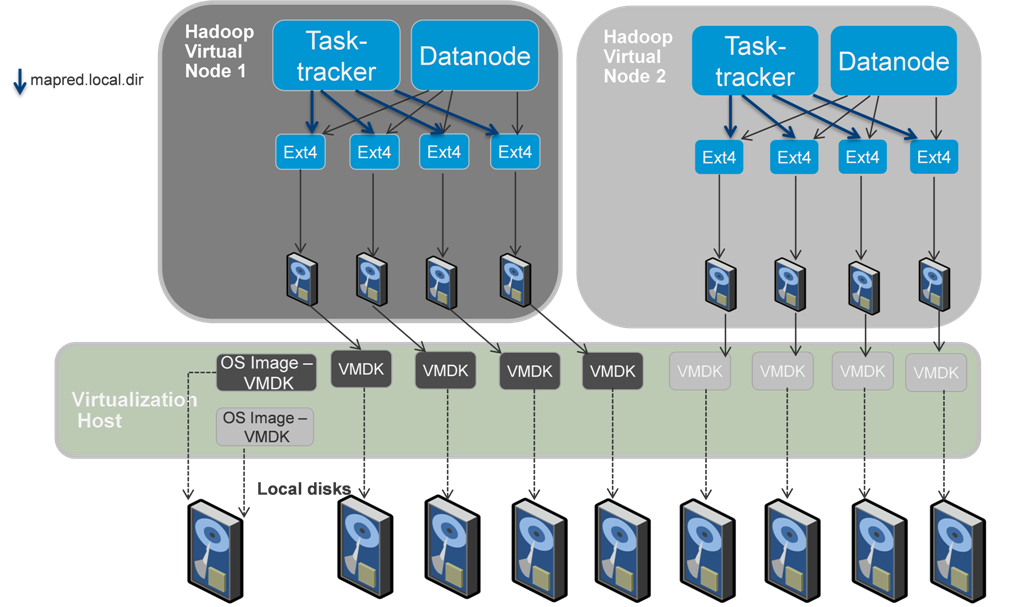
图3:多虚拟机的部署
同时,我们把这些实验经验内嵌到vSphere BDE部署的Hadoop集群系统配置当中,屏蔽了性能优化的复杂性。虽然不同的数据中心设置和集群配置可能带来不同的表现,这里按照创建、配置、扩展Hadoop集群的顺序跟大家分享一些通用的经验:
Hadoop虚拟化的调优经验:
(1)计划初始规模:集群表现于跟数据中心基础设施和配置密切相关,建议用户在一开始对环境表现难以预测的时候,先建立小规模集群,比如5台或者6台服务器,部署Hadoop,然后运行标准Hadoop基准了解自己数据中心的特点。然后根据需要逐步添加服务器和存储等资源。
(2)选择服务器:CPU建议不要少于2 * Quad-core并且激活HT(Hyper-Threading);为每个计算内核配置至少4G内存,并且预留6%的内存为虚拟化的有效运行。Hadoop性能对I/O很敏感,建议每台服务器配置多块本地存储而不建议配置少块大容量的硬盘。考虑任务调度的代价,对于每个计算内核不建议配置超过2块本地存储。为高性能考虑,推荐使用10G网卡。考虑为主节点服务器(运行namenode、Jobtracker)配置双电源以提高可靠性。
(3)虚拟化配置:本地存储尽量避免配置成RAID,为每一个物理盘创建一个datastore虚拟化网络配置时为了可靠性和网络传输效率,隔离管理网络和Hadoop集群网络。如图4所示:
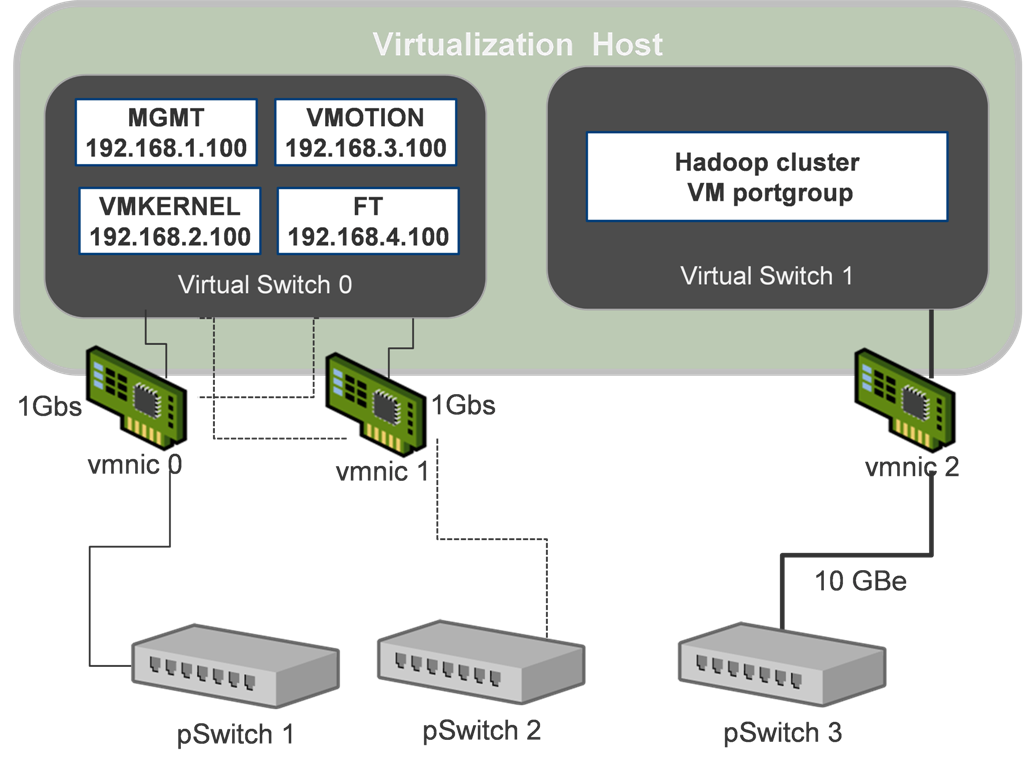
图4:虚拟化网络配置
(4)系统设置:BDE将会自动配置根据实验经验取得的虚拟磁盘和操作系统参数,向用户屏蔽性能优化的具体细节。建议对性能敏感的用户替换默认模板采用CentOS6*,因为Linux 6.* 内核的THP(TransparentHuge Page)和EPT(Extended PageTables,Intel处理器)可以一起帮助虚拟化性能。
(5)Hadoop配置: BDE将会自动产生并配置hadoop配置文件(主要在map-site.xml,core-site.xml,和 hdfs-site.xml内),包括块大小(blocksize),会话管理和日志功能。但是有一些相关于MapReduce任务的参数,包括mapred.reduce.parallel.copies,io.sort.mb,io.sort.factor,io.sort.record.percent,和tasktracker.http.thread,需要根据不同负载具体设置。
(5)扩展建议:如果用户观察集群中CPU的利用率经常超过80%,建议加入新的节点。另外单个存贮节点的容量不建议超过24TB,否则一旦节点失败,数据备份拷贝容易造成数据拥塞。扩展可以按照小规模集群上运行性能基准经验和资源使用情况进行。
如有任何问题,您可以发邮件至bigdata_apac@vmware.com。
关于vSphere Big Data Extensions:
VMware vSphere Big Data Extensions(简称BDE)基于vSphere平台支持大数据和Hadoop作业。BDE以开源Serengeti项目为基础,为企业级用户提供一系列整合的管理工具,通过在vSphere上虚拟化Hadoop,帮助用户在基础设施上实现灵活、弹性、安全和快捷的大数据部署、运行和管理工作。了解更多关于VMware vSphere Big Data Extensions的信息,请参见http://www.vmware.com/hadoop。
作者简介
李欣慧
VMware软件高级工程师
现担任VMware大数据部门高级工程师,致力于大数据在云计算中心上的服务化和高效化,工作在分布式系统性能优化领域。李欣慧毕业于中科院计算所,后加入IBM实验室-分布式计算部,主要工作在云计算和并行数据处理领域,为大规模数据中心提供最优监控和运维工业解决方案。有9项专利在美国和中国注册,在国际知名会议、学术期刊上发表论文5篇。