【51CTO专稿】由51CTO传媒举办的为期两天的2013云计算架构师峰会已于10月26日圆满落幕,会议内容涵盖了云计算落地的重要环节,包括有:基础架构、开发应用、安全、存储以及云计算生态圈等方面。来自迅达云成(SpeedyCloud)的***技术官董伟在会上做了主题为《云平台上的NoSQL集群的自动化扩展》的演讲。为小伙伴们演示了在云主机上创建并初始化NoSQL集群的方法;以及如何通过监控系统发现主机故障,并且自动调用云端API进行故障设备替换的过程,***还展示了如何通过命令行的方式销毁主机的整个过程。
但是因为时间仓促,没有给小伙伴们留出太多时间进行问题解答和难点的详细介绍,所以董伟在会后将大家比较关注的一些问题整合起来,并分析了在搭建的过程中碰到的一些难点问题及解决方案,以下是他整理出来的关于这部分的内容:
大家好,很荣幸作为主讲嘉宾,在会上做了分享。不过由于时间仓促,未和大家做充分交流,所以会后我想通过该文章来解答一些大家关注的问题,并且介绍一些我们在搭建的过程中碰到的一些难点及解决方案。
在这之前,我先给大家介绍一下我们在构建过程中使用到的这款NoSQL数据库MongoDB集群的架构以及它的一些特性。
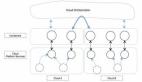
我们要构建的集群是MongoDB的复制集(Replica Set, 可以参考官方文档), 集群的结构类似于下图这样(在会上我们演示时用了1个主,4个副的结构,但原理都一样)。
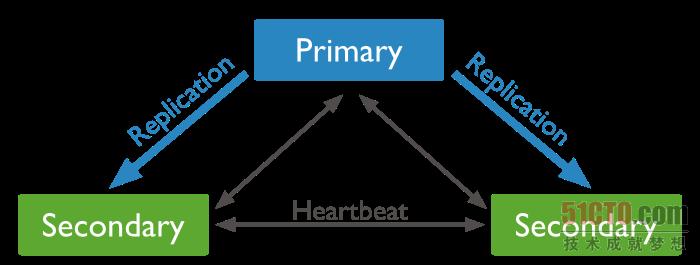
在这个集群中有一个主(Primary)节点,用来接收写入操作,剩下的都是副(Secondary)节点,他们会从主节点通过同步Oplog过来,并应用到本地数据来实现数据的同步,而且集群中各个节点之间都有心跳(Heartbeat)探测,以确保集群之间的互通性。
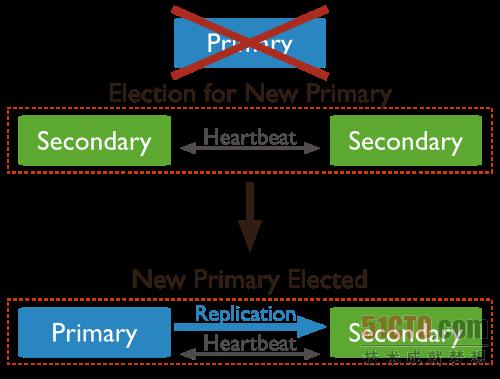
当该集群中的主节点不可用后,剩下的节点会自动通过选举的方式产生一个新的主节点,这个过程是MongoDB集群的特性,过程如下图所示:
我当时为大家演示了三个场景:
***个,MongoDB集群的初始化过程。我们先调用了SpeedyCloud云端的API完成了云主机的创建及启动单个MongoDB实例,当分别确认完毕数据库状态之后,通过执行一段初始化代码完成了整个集群的初始化。
第二个,MongoDB集群故障设备替换。为了模拟集群中设备故障,我们手工关闭了一台主机,然后通过监控系统的侦测,自动发现故障设备,并且调用云主机创建过程,然后调用添加成员过程实现了集群中故障设备的自动替换。
第三个,销毁整个集群。当整个集群的生命周期结束后,通过调用SpeedyCloud云端API,传入云主机的ID号来实现云主机的自动销毁过程。
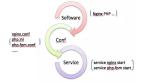
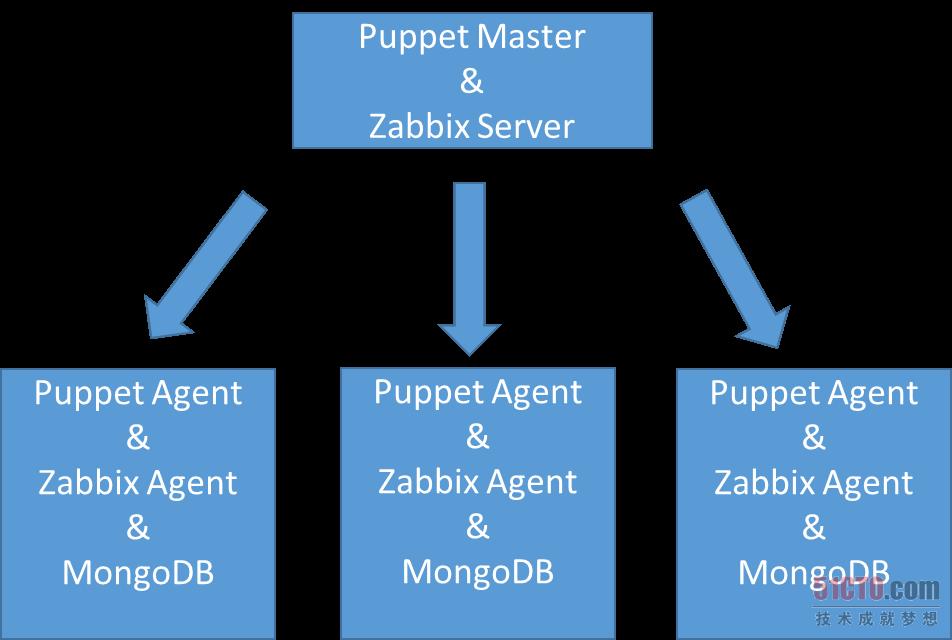
在整个过程中涉及到了四个方面的技术应用:SpeedyCloud云端API的调用、Puppet配置管理系统的使用、MongoDB集群的维护以及Zabbix监控系统的使用。
我们通过在云主机中内置Puppet Agent的方式,让它和Puppet Master进行交互,实现了密码修改以及一些配置文件的管理等;通过Zabbix Agent来实现了设备到监控系统的自动注册,及监控数据的上报功能;同时又通过Zabbix Server的Trigger实现了对故障主机的发现,以及发现故障后的处理脚本调用。这套系统的整体结构图如下所示:
下面开始我们的答疑部分,就大家会上以及会后问到的一些问题进行解答。#p#
答疑部分
问题1:假如我们构建的是一个通过HA-proxy实现的Web负载均衡系统,那么当某台设备宕机之后,自动调用云端API生成了新的主机后,由于IP发生了变化,所以需要重新更改HA-proxy的配置,并手工添加该设备,请问可以让IP不变吗?
答: 因为在SpeedyCloud的整个运行系统中,设备在未销毁前,它的IP是始终跟随着它的,不会发生变化,所以新生成的设备只能启用新的IP。这时候可能就需要通过一段脚本将新加入的IP写入到HA的配置文件haproxy.cfg中,并放置到Puppet对应的目录,然后通过Puppet Agent将该文件下发到Ha-proxy设备上,并且调用它的重启命令完成新设备的添加。
问题2:MongoDB集群中的设备宕机之后,那么它上面的数据怎么办?
答:因为我们采用的是MongoDB的复制集(Replica Set)模式,这种方式的优点是,在一个集群中,同一份数据会被存到多个节点上,因为设备都是通过内网相连,所以主节点上的数据会以最快的速度全部同步到所有集群中的节点上,所以,集群中任何一台设备宕机之后,其实都不会影响系统整体的数据完整性。
问题3:当调用API时,调用的安全性及账户安全性如何来进行保证,因为我看到您调用时并没有输入用户名密码这样的参数?
答:我们通过这几个手段来保证调用安全性:
***,在调用时,不需要提供用户名及密码,而是通过提供API-Key来实现的身份识别,这个API是一串经过加密的64位字符串,以此来保证账户密码的安全;这个API-Key可以通过登录到系统中进行查看,如下图所示:
第二,在提交时我们需要验证系统时间,并且要求将系统时间和API-Key做SHA1加密,以此来保证URL的时间唯一性和***性;
第三,客户在调用API时,可以基于HTTPS的方式来进行调用,这样可以进一步来保证调用的安全性。
问题4:通过调用API创建出来的这些设备,你们是怎么计算费用的?
答:我们对于通过API创建出来的云主机采用按小时后付费的策略。客户需要预先往自己的账户里充入一些金额,然后每个小时会统计客户在这一个小时中主机的使用情况,根据主机配置及使用情况作做相应的扣费操作,如果发现客户的剩余金额不够扣除,我们会提前一个小时发邮件来提醒客户进行充值。
问题5:我知道使用Puppet进行配置文件下发时,是要对客户端做认证的,可是我看到您在新加了一台设备之后,就自动从Puppet上面获取到了配置文件,是如何实现的?
答:Puppet Master支持一种叫做自动授权(autosign)的功能,它需要在Puppet Master的配置文件中(通常这个文件为/etc/puppet/puppet.conf)增加三行配置:
[master]
autosign = true #指明要支持自动认证功能
autosign = /etc/puppet/autosign.conf #指明自动认证的规则保存在哪里
- 1.
- 2.
- 3.
- 4.
- 5.
同时需要在/etc/puppet/目录下创建一个叫autosign.conf的文件,用来保存自动认证的规则,添加 * 表示所有,或者添加域名,举例:
doc.speedycloud.cn
*.speedycloud.cn
- 1.
- 2.
- 3.
问题6:我看你在调用API创建云主机时,传入了一个bootscrip参数,这个是做什么用的?
答:这是一段可执行的命令,写在这个参数里面的命令会被写入到/etc/rc.local文件中。这个文件的作用是用来在开机启动时执行一些命令。所以你可以将一些你想在系统启动时运行的命令写入到这个脚本文件中,这样当系统启动时就会执行这些脚本来完成你想要做的一些事情了。#p#
难点及解决方案
难点1:初始化一台MongoDB主机时,由于要从国外的官网下载大量的安装文件,所以导致安装时间会很久,这样会影响演示时的效果以及加长演示时间,怎么办?
解决方案:其实先开始是通过Puppet来实现MongoDB的安装的,但是发现每次都需要好久, 因为要下载很多安装包,这样就不能够保证演示时的时间。所以后来就想了一个办法,因为在SpeedyCloud的云平台上,支持自定义模板功能,也就是说,可以以一台安装好的云主机作为系统镜像,这样新建一台设备时,将该镜像的名字作为参数传进去, 就可以以此镜像为模板来生成云主机了,我们将一台已经安装好了MongoDB的设备作为模板,这样演示的时候就大大缩短了创建一个MongoDB节点的时间。
难点2:MongoDB集群在搭建时需要通过域名或者主机名进行互相访问(可以参照这个文档), 演示的例子中我们采用了主机名的方式,也就是说通过在/etc/hosts文件中来指定主机名。但有一个问题:因为每台的/etc/hosts文件中都会包含一行对自己的定义,类似这样:127.0.01 i-gblrwptp ,而在其他的机器上对这台主机的定义又可能变成了类似这样:10.70.0.52 i-gblrwptp 也就是说同一个hostname在不同的主机上可能所映射的IP不一样,所以不能用Puppet进行整体文件的替换,这个难题怎么解决?
解决方案:这个问题的解决方案主要还是通过Puppet进行的,当然也涉及到一些中间过程,主要有以下几个步骤:
***步,在调用完创建设备的API之后,通过调用查看设备详细信息的API接口,在Puppet Master上将新创建出来的设备的IP和主机名的对应关系写入到一个hosts的文件中。内容及路径如下所示:
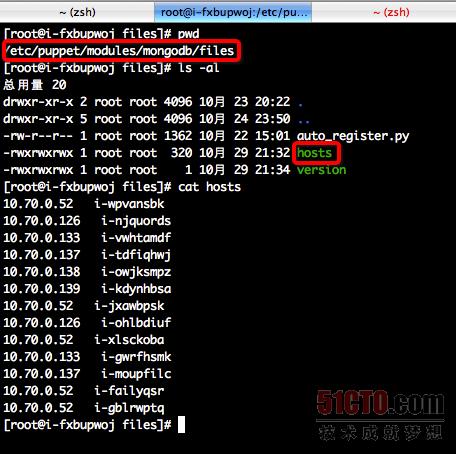
第二步,通过Puppet将该配置文件下发到所有新创建的主机的该位置/etc/puppet/config/hosts。Puppet中的配置如下所示,我们可以看到,如果该文件更新了之后,会触发一个称为auto_register.py的脚本。
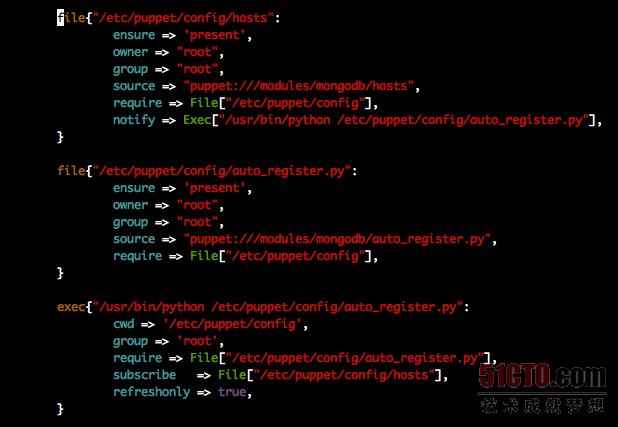
第三步,向所有新创建主机的/etc/puppet/config/目录下, 下发一个脚本auto_register.py,从上图中我们可以看出该脚本的Puppet定义。该脚本是用来将上一步下发的host文件,加入到系统的/etc/hosts文件中。该脚本的内容如下:
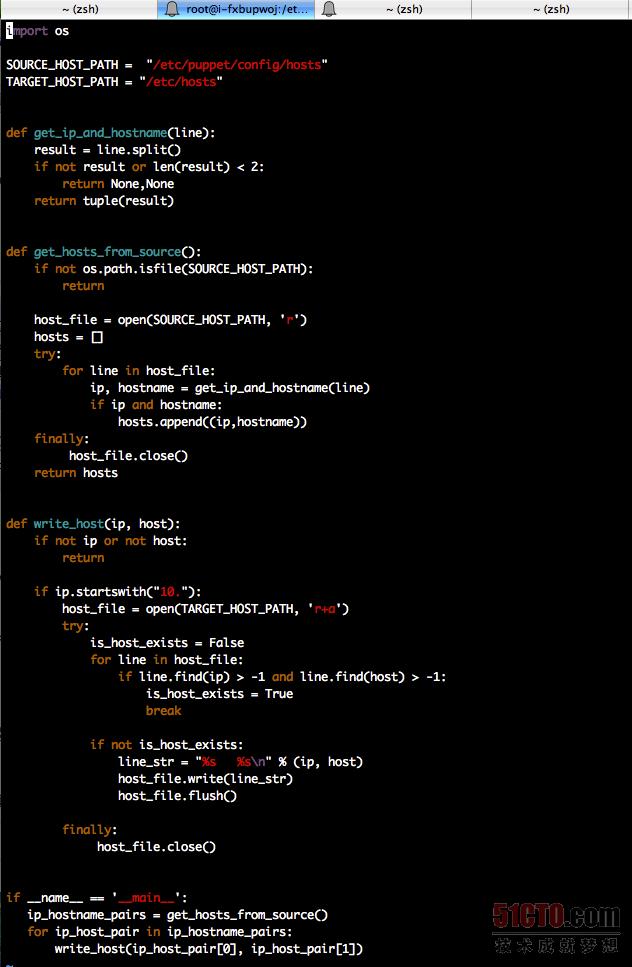
难点3:如何来配置Zabbix的Auto registration(自动注册)功能,让设备可以将自己的信息自动注册到Zabbix Server里面去?
解决方案:实现这个功能,需要同时在Zabbix Server端和 Zabbix Client端进行设置,步骤如下:
***步,首先要在新建的主机中安装好Zabbix Agent,这个可以在难点答疑1的里面创建虚拟机模板的时候就安装好,只不过后来我们要通过PuppetServer下发Zabbix Agent的配置。
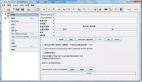
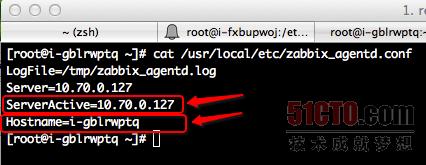
第二步,修改Zabbix Agent的配置文件/usr/local/etc/zabbix_agentd.conf,如下图所示,关键点是配置ServerActive(Zabbix Server的IP)和 Hostname(本机主机名,该名字会显示在Zabbix Server中)
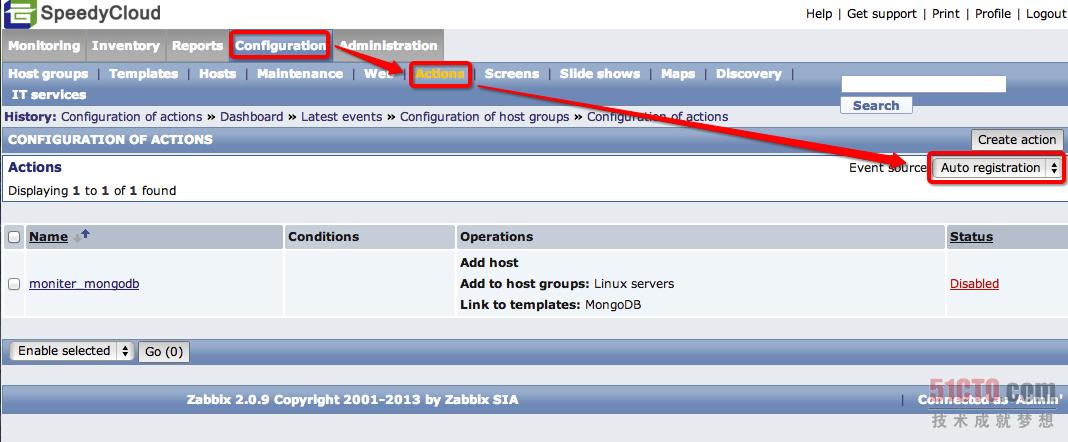
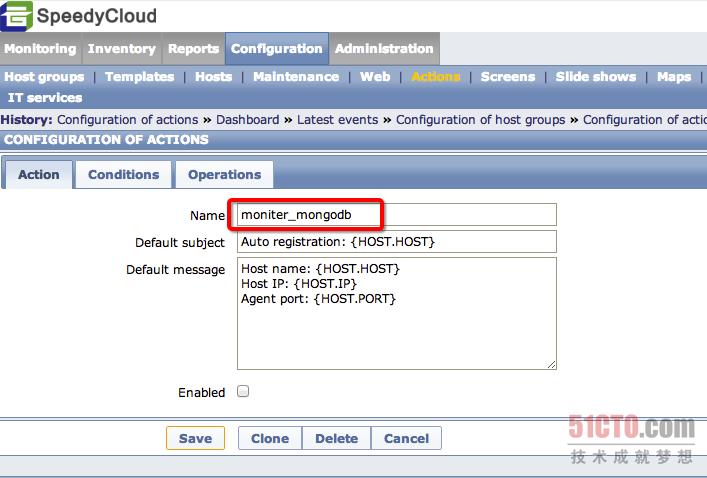
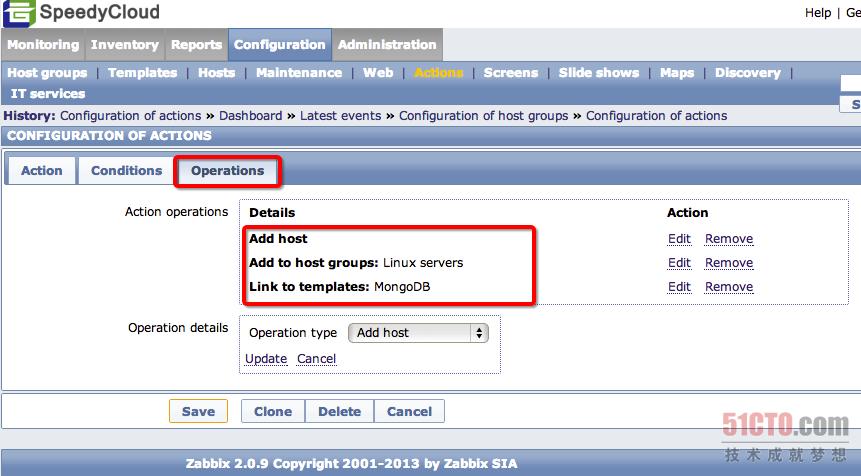
第三步,配置Zabbix Server的自动注册功能,通过如下图所示的路径进入Action定义区,然后点击"Create action"进入配置界面,相应的配置如下所示,需要修改的地方会圈出,完成这几个步骤之后,那么重启Zabbix Agent之后,就会将客户端注册到监控系统里面了:
难点4:Zabbix客户端的配置文件中需要配置自己的主机名,而每台设备的主机名是不一样的,这个配置通过Puppet是怎么做到的?
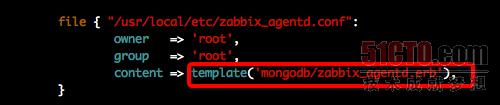
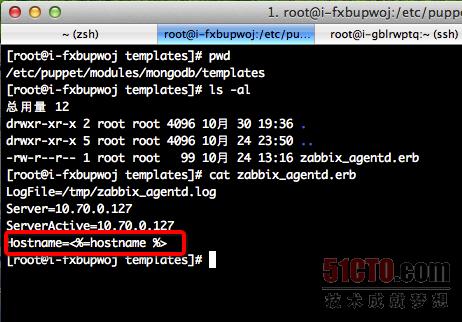
解决方案:这里用到了puppet的facter功能,以及Puppet的内容定义模板功能。其实所谓的Facter,就是运行在客户端里面的一个ruby命令,通过该命令可以获得所有关于这台主机的信息,然后当Puppet客户端向服务端请求资源的时候,会将这些可以通过Facter命令取到的信息都告诉Puppet Server,因此Server端就可以使用这些信息来生成一些文件内容。下面的***张图为在客户端执行facter命令的效果。第二张图为Puppet Server端对Zabbix agent的配置文件定义,可以看到要使用一个ruby文件。第三张图为该ruby文件的内容,可以看到里面使用到了一个hostname的变量,这个就是通过facter取到的值。

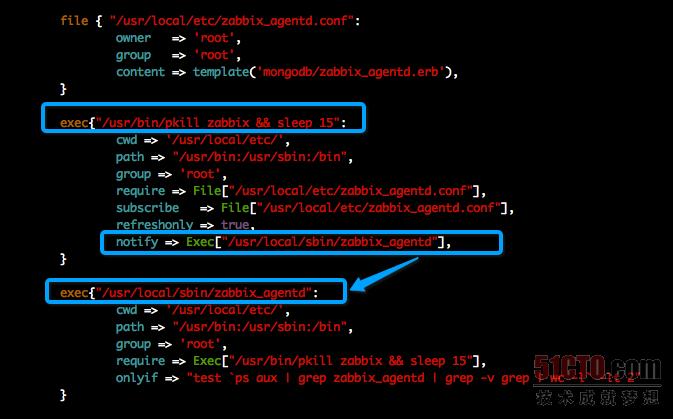
难点5:当Zabbix Agent的配置文件被更新之后需要重启才可以生效,如何让客户端在正确的时机来进行重启?
解决方案:这部分我们先开始也遇到了难题,发现调用pkill zabbix之后,马上启动zabbix_agentd是起不来的,后来才知道,调用了pkill之后,会在ps -ef | grep zabbix里面看到很多僵尸进程,所以只能在这些僵尸进程被回收之后,才可以启动,为此,我们用了一个简单的办法,就是在调用pkill zabbix之后,让该命令等待15秒(sleep 15)来释放资源,然后再启动zabbix_agentd 就可以了,当然这个15秒是一个经验值,大家在使用时可以根据实际情况来进行调整。在Puppet Server上关于这部分的配置如下: