***版发布的3年后,Facebook开源了新版Flashcache。对比旧版本,新版本缓存命中率由原来的60%提升到80%,磁盘读写更减少了一半。 近日该公司数据库工程师Domas Mituzas撰文盘点了Flashcache在Facebook的发展历程,以下为译文:
Flashcache 在 Facebook 的历史
Facebook 于2010年***使用Fashcache。那时,工程师仍在做基于SAS或SATA硬盘和完全基于闪存方案的选择。然而,这两个方案都不尽人意:2010年,SATA读写慢,SAS需要很多硬盘,而闪存的价格又居高不下。
其中一个可行的方法就是把我们的数据库分成多层——一部分处理请求最多的数据,这些层需要高性能的硬件设备做支撑,而在需求较少冷数据的处理上,性能低的设备也能跑起来。当时,这种方法在技术是可行的,因为我们的数据存取模式呈现为典型的Zipfian分布:即使我们使用了很多RAM缓存机制(memcache、TAO、InnoDB 缓冲池),通常热数据的存取要高出普通数据10倍。但缺点是该方法却相对复杂,依当时的数据规模,额外增加复杂性显然不是一个明智的选择。
2010年,我们嗅到了从软件层解决这个问题的机会。于是评估了直接在InnoDB中为L2缓存增加支持的可行性,结果发现为MySQL等设备加缓存效果会更理想。因此,选择把Flashcache做成Linux内核设备映射模块,并大规模地将其部署到生产环境。
性能分析和优化
在随后的几年中,系统的性能状况发生了变化:借助InnoDB 的压缩性能,我们存储更多的逻辑数据,它们通常要求较高的IOPS;随后一些旧数据被迁移到其他层,并进行了相应的优化,在不影响正常读取的前提下尽可能使其少占空间。随后因负载需求磁盘IO也不断增加,某些服务器上的硬盘IO限制达到饱和。鉴于此,深入探究生产环境中的Flashcache的性能也被提上台面,我们开始查看性能进一步提升的可能。
不同类型磁盘驱动器运行特性由多个因素决定,其中包括了硬盘转速、磁头速度以及每一转所读取的次数等。过去,SATA硬盘性能普遍不敌企业版SAS组件,因此,就像到了优化软件栈来提升系统性能。
虽然在很多情况下,“iostat”之类的工具对理解系统的整体性能有所帮助,但是却无助于深层次的研究。这里使用了Linux的blktrace工具来跟踪数据库软件发起的每一次请求,并分析闪存、硬件缓存机制如何处理这些请求。从而得到了3处可以提升的地方:读写分布、缓存回收和高效地写操作。
1. 读写分布
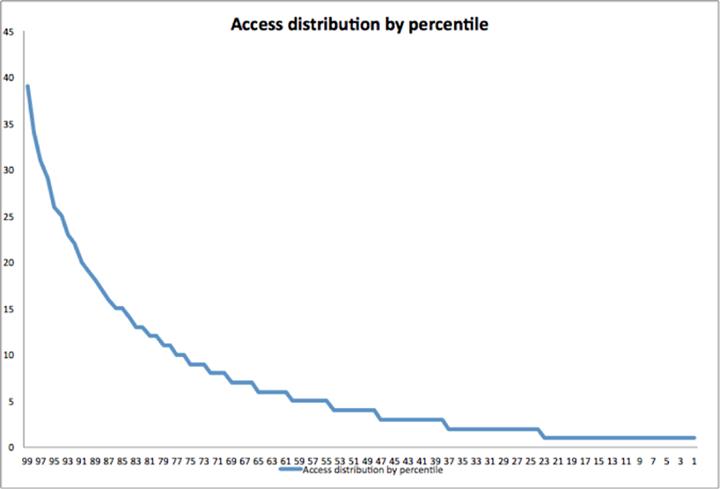
通过分析后发现写操作集中在硬盘上的少数区域,而读操作分布很不均匀。我们在Flashcache中增加了更多的设备来监控工作负载,以更好地测量缓存行为。从高层次上看,情况大抵是这样的:
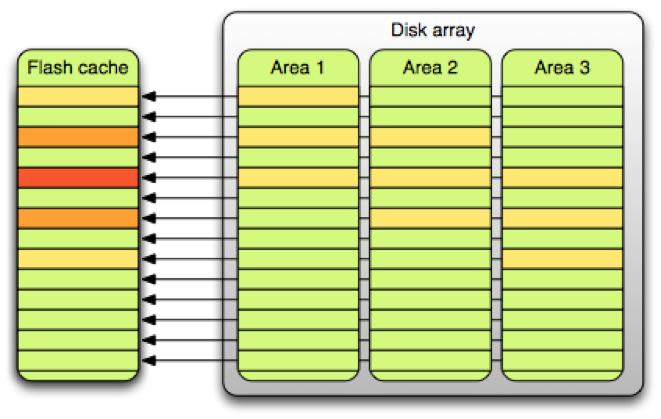
为了简化缓存维护操作,缓存设备被分割为许多大小为2M的单元,总体存储中2M大小的部分线性映射到缓存。然而,这种架构导致热点表排列在相同的缓存单元上,冷表则占用了其它闲置的单元。(这与“生日悖论”没有什么不同,“生日悖论”指的是与大多数人的期望相反的是——两人生日是同一天的概率要达到50%的话,至少要有23个人。)
要解决这个问题,要么是有好的配置算法能够将小块缓存考虑在内,或是增加某一单元内的数据类型。经过简单的策略调整后,果断的选择了后一个方案。
将硬盘端的相关数据从2M降至256K (使用RAID阵列)
将闪存端的相关数据从2M增加到16M(每单元为4096页而不是512页)
用随机哈希取代替线性映射
以上变动将热数据打散至更多的缓存区域。下图显示了这样做带来的好处:
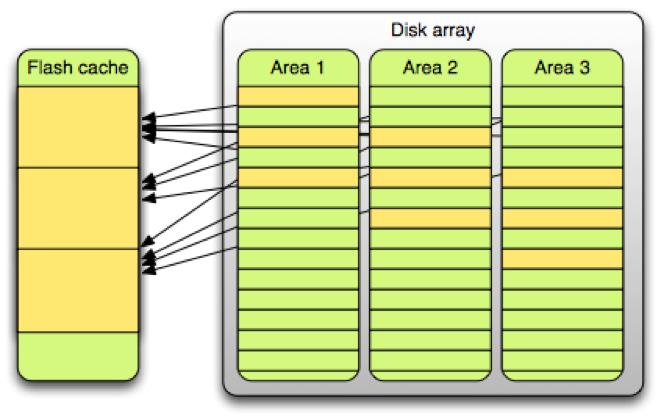
变动前,50%的缓存“贡献”了80%的硬盘操作。而变动后,同比例的缓存,硬盘操作仅为50%。
2. 缓存回收
在Facebook,数据库服务器使用小型的逻辑块——压缩过的InnoDB表仅用4或8K,而未压缩过的用16K大小的逻辑块。用2M大小的缓存单元的话,各缓存回收算法,FIFO和LRU,并没有明显差别。z在增加Flashcache单元大小后,工作负载随之改变,因此不得不开始寻找FIFO的替代方案。
由于使用了blktrace子系统提供的跟踪功能,因此不再需要实现整套机制来为不同的缓存回收算法的表现建模。回收算法通常非常简单——因为它们要管理所有经过缓存的动作,它们不得不简单有效。用Python写的LRU装饰器仅有不到20行代码,加上中点插入功能不过是增加了15行代码( 示例)。最终我们写了简单的模拟器来为回收算法在我们的数据集上的不同表现建模。我们发现带中点插入功能的LRU较为有效——但是我们仍然需要确定LRU中的***中点以插入新读入的数据块。
我们发现被多次引用的数据块由中点移到了LRU的头部。如果在***次被读取时,把这些数据块置于LRU的头部,很多只读一次的数据块将会把读操作更频繁的页面推出LRU。如果我们把它们置于LRU的中部,它们将处于第50百分位。如果我们把它们置于头部,它们将处于0百分位。如图所示,插入点至少要到第85百分位,缓存才有效。
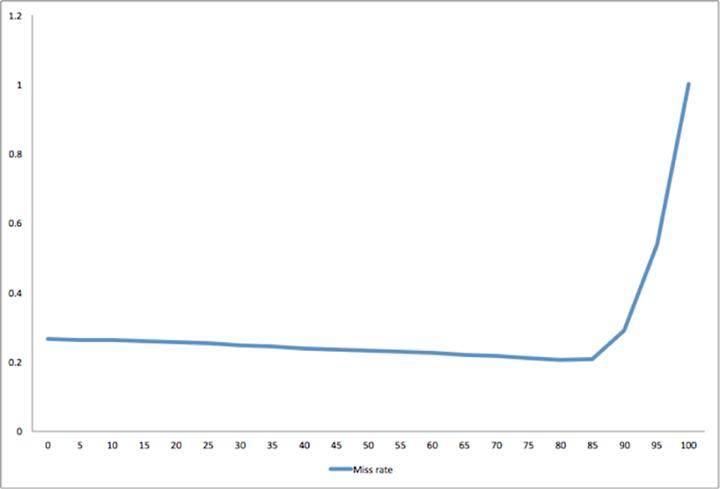
这种行为是基于特定工作负载的,理解这一点有助于提升Flashcache的效率。当前,我们使用Flashcache时是在第75百分位使用中点(实现为LRU-2Q)插入单元。该设置有些保守,它允许25%的旧页面存在,但仍然要比标准的LRU要出色,因为重构、迁移等缓存行为在先前的建模中是没有考虑在内。
在Facebook,每台机器上运行多个数据库实例,我们优先选用运行时间最长的实例的旧表区域,对新表则谨慎对待。
3. 写操作的效率
另一个需要解决的问题是写操作效率。Flashcache能够充当可靠的写入前高速缓存,对硬盘的很多写操作可以事先合并到闪存中。
之前,我们尝试固定每缓存单元的脏页占比。由于不同的缓存单元有不同的行为,在这种模型下,我们最终会为修改过的页面配置underallocating或overallocating缓存。有些部分被不停地写入,有的脏页被缓存一周,这严重影响了读缓存。
为了解决这个问题,我们实现了不再分离读写操作的脏数据回收方法。所有的数据同等对待,如果缓存要重用一页面,它只须查找LRU中最旧的那页即可。如果最旧的页面是脏的,缓存调用后台的回收算法回收该页面,重用次旧页来缓存新数据。
在***化地保留写入前高速缓存的写-合并效率和速写能力的同时,解决了写操作问题。它还增加了可用于读操作的空间,并从整体上提升了缓存效率。
未来工作
实现了以上三处改进,目光被投到未来的工作上。首先调整了元数据结构来提升数据读取的效率,但是要让Flashcache支持下一代建立在TB级的缓存设备和硬盘存储的系统,仍然存在许多挑战。为了支持多核CPU的并行数据读取,细粒度锁机制的开发也正在进行中。
同时,虽然每G闪存的价格在下降,但离理想区间还有段距离。价格下降也对容量规划带来了挑战。SSD写次数有限,这里还必须确保写的次数不会超过上限。将数据写入闪存时,缓存的数据会丢失,所以使用太小的闪存设备存在隐患。在这种情况下,***使用转速不要太快的硬盘,因为任何缓存层级取决于多层间的巨大的性能差距。
有了这些改进,Flashcache已经成为Facebook软件栈的构建模块。我们在新的分支上跑成千上万的服务器,其性能自flashcache-1系列有大幅提高。我们最繁忙的系统的读操作I/O下降了40%,写操作I/O下降了75%。自此,高效地服务于10亿用户只须轻弹一内核模块。flashcache-3系列的代码已经提交到 GitHub。