













近日在《量子杂志》上刊登了一篇文章,讲述了量子物理学研究的过程中,各种计算机技术的变迁,作者是物理学的专栏作家,文中并没有谈及专业的计算机技术细节,但也提供给我们一个新的视角去看待近年来计算机技术的发展。以下为译文:
2013年诺贝尔物理学奖10月8日在瑞典揭晓, 比利时理论物理学家François Englert和英国理论物理学家Peter W. Higgs因希格斯玻色子的理论预言获奖,2012年这一预言在位于瑞士的CERN(欧洲核子中心)粒子物理实验室中得到了证实。
在CERN的 LHC(大型强子对撞机)中,亚原子颗粒不停高速碰撞,产生新的粒子,四个监视器在持续记录这些粒子的情况,每秒产生的数据量高达5TB,相当于全球图书馆数据量的总和。这些数据被滤波算法处理后,99%以上的数据都被过滤掉了,但是每年这个系统需要存储和处理的数据仍然高达25PB。研究组正是在这数以十亿计的粒子对撞结果中提取到了希格斯粒子存在的证据。支撑这些数据计算的是遍布全球的160个数据中心,这个分布式网络的数据传输速率***可达10GB/S。LHC解决大数据问题的方法反映了近十年来计算本质的戏剧性变化。
从摩尔定律到多核技术
摩尔定律自1965年被Intel联合创始人Gordon E. Moore提出以来,就一直主导着计算机产业。根据摩尔定律,集成电路中的晶体管数量每隔两年会增加一倍,然而目前看来,这个速度是***弹性的。麻省理工学院理论计算机科学家 Scott Aaronson认为“摩尔定律已经基本失效”。
自2005年以来,许多计算能力的增长都来自多核技术带来的并发性上。更快的处理器固然重要,但已不再居首位。斯坦福大学电气工程师 Stephen Boyd认为“5年来,处理器速度对于计算能力的提高已经不多了,解决问题的挑战并不在于如何利用一个超快的处理器,而是如何整合10万个较慢的处理器”。Aaronson指出简单地增加并行处理并不能充分解决大数据问题,这些问题更连续,有时可以分割成小任务分配给多个处理器,有时很难做到分割,并且这些处理器也很难得到充分利用。好比是20个人完成一项工作,通常情况下并不能达到20倍的速度。
数据传输的问题
研究人员在集成不同架构的数据集时也面临着挑战,同时在一个高度分布式的网络中有效传输数据也面临巨大困难。随着数据集的规模和复杂性不断增长,这个问题会变得愈发明显。据加州科技学会物理学家 Harvey Newman(他的团队开发了LHC的网格数据中心和横跨大西洋的网络系统)。他估计照目前的形势发展,LHC数据处理系统的计算能力将不能再满足需求,甚至需要重新设计。
内存与数据传输
数据传输有时比处理延时更耗时,Aaronson说:“计算机运行慢的原因不一定是微处理器的问题,还有可能是微处理器在等从磁盘传来的数据。”大数据研究人员更喜欢数据传输时间尽可能的少,因为存储在分布式网络或云端的数据会使情况恶化。
分布式计算
解决这个问题的方案之一是使用新的模式:除了存储,分析数据也采用分布式的方法。LHC的方案就类似于这种模式,对撞机中的产生的原始数据被存储在瑞士的CERN研究设备中,另外还有一份备份数据被按批量划分并分布到世界各地的数据中心。每个数据中心对各自的数据块进行处理,然后在处理下一批数据前,将处理结果发送给各地区的计算机。
Boyd的系统基于所谓的 一致性算法,他介绍说:“这是一个数学优化问题,用以前的数据‘教育’这个系统来处理未来的数据。”这个算法在SPAM过滤器中也得到了很好的应用。
当问题变得太大时,一致性优化方法非常有效,数据集被分割成块,分布在1000个“代理”中分别处理,并产生一个数据模型。关键是要满足临界条件:每个“代理”的模型可以不同,但***这些模型要达成一致。
在Boyd的系统中,这个过程是迭代的,创建一个反馈环路,所有的代理会共享初始情况的一致状态,继而根据新的信息更新各自的模型,并达到新的一致状态。这个过程不断重复,直到所有的代理都达成一致。采用这种分布优化的方法可以显著减小每次需要传输的数据量。
量子计算
去年的纳帕谷会议上,MIT的物理学家 Seth Lloyd引起了Sergey Brin和Larry Page的关注。在演讲中Lloyd提出了一个量子版本的Google搜索引擎,Google在对用户的搜索关键词情况下,用户也可以做查询和收到结果。但是第二天Lloyd被告知这个方案和Google的商业计划有冲突。Lloyd开玩笑说:“Google想要对他们的每个用户做到了如指掌”。量子计算机可以提供强大的处理能力,对于某些复杂算法可大幅度提高速度。实际上,Google从一家加拿大公司D-Wave以1500万美元购买了所谓的量子计算机, 虽然这个项目目前也面临一些问题。
Aaronson认为量子计算机并不是并行地尝试所有可能的答案,它与并行处理有着本质上的不同。普通的计算机用0或1来存储数据,量子计算机有着更多的状态位。比如,抛硬币的结果只能是正面朝上或背面朝上。但从技术上来说,在看到结果前,量子状态下的硬币正面朝上还是背面朝上是不确定的。
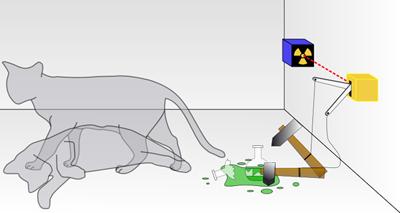
量子学的宏观解释:著名的薛定谔猫
一个真正的量子计算机可以将信息编码为所谓的量子比特——同时为0和1的 叠加态。这样做可以将处理复杂问题的时间从几年缩短到几秒。这种设想很美好,实现起来并不容易,尤其是因为这样一个设备对外界的干扰非常敏感,轻微的扰动都相当于将抛硬币的结果“公之于众”,量子的叠加态也将消失。
然而,Aaronson认为不要对量子计算机报太大期望,即使量子计算能够实现,它们也仅适用于特定的问题。比如,模拟量子力学系统或用于经典密码学的密码破解,然而有一种大数据问题是量子计算可以处理的:对大量的无序数据集进行检索,例如随机排列的电话本。
1996年,贝尔实验室的 Lov Grover提出了这个问题的量子计算算法,但Aaronson说:“真正实现这个算法时,你需要一个原子内存可以在量子叠加态被访问,同时保证这种访问不会破坏量子叠加态。”
换而言之,你需要一个量子RAM(A-RAM),Lloyd曾经开发过一个概念原型以及一个用于机器学习的应用程序,他称之为Q-App。他认为这个系统可以在不查看个人记录的情况下,找到数据的模式,从而保持原子的叠加态和用户的隐私。“可以在同一时间高效地访问这数亿条数据,实际上你并没有访问这些数据,你只是在访问它们的共同特征。”
Lloyd认为如果拥有一个足够大的量子RAM,量子计算尤其适用于在大量的数据集中找出规律的机器学习算法,例如确定某个关键字相关联的集群数据,或拥有共同特性的数据块。
如果构建一个存储了地球上所有人基因的数据库,可以利用Lloyd的量子算法查询不同基因的共同模式,这个过程中只会访问一小部分个人数据,并且耗时很少。随着人类基因组排序成本下降,以及商业基因服务的价格上升,未来很有可能会出现这样的数据库。假设一个基因组占60亿字节的话,这可能将是全球***的数据集。
数据聚合是未来
谷歌的计算机科学家 Alon Halevy认为大数据领域的最重大突破可能将来自于数据集成——尤其是跨数据集的集成。不管你的计算机速度有多快,或计算机集群做得有多好,真正的问题还是来自于数据层面。例如,一个原始的数据集可能包括成千上万个遍布全球的表格,看似简单的全球咖啡生产量查询操作,后台整合的复杂度却出人意料。
NASA喷气推进实验室资深计算机科学家兼 Apache软件基金会董事Chris Mattmann就面临这样一个复杂问题,他正在进行一项研究项目,整合两个不同来源的天气信息:来自卫星的气象遥感信息以及计算机模拟的天气模型输出。IPCC(政府间气候变化专门委员会)会对这些天气模型与遥感数据进行比较,以确定最适合的模型,而这些模型都采用不同类型的数据。
许多研究人员强调有必要开发灵活的工具处理不同类型的数据。Mattmann提到了一个名为Tika的Apache软件程序,这个程序允许用户整合1200常用文件类型的数据,但有时需要一些人工干预的工作。最终,Mattmann选择了一个可以整合不同结构数据集的完全自动化智能软件。
跨数据集的整合同时也需要一个协调性比较好的分布式网路系统。LHC在加州理工学院的Newman的研究小组负责监控成千上万的处理器以及十几个主要网络链接。Newsman预测大数据计算的未来在于各智能代理间的互相协调,在网络各个节点跟踪数据的行为,从而识别瓶颈和调度处理任务。每个可能仅仅记录本地发生的事情,但是会以这种方式向整个网络共享信息。
Newman说:“不同层级中,成千上万的代理互相协调,帮助人类理解这个复杂和分布的系统中正在发生的事情。”未来这个数据量将会更大,当这些智能代理达到数十亿时,将会形成一个巨大的遍布全球的分布式智能实体。



















