今日面试题:鸡蛋挺住体
两个鸡蛋:两个软硬程度一样但未知的鸡蛋,它们有可能都在一楼就摔碎,也可能从一百层楼摔下来没事。有座100层的建筑,要你用这两个鸡蛋以最少的次数确定哪一层是鸡蛋可以安全落下的最高位置。可以摔碎两个鸡蛋。
MapReduce矩阵的分析
题目:
一个很大的2D矩阵,如果某点的值,由它周围某些点的值决定,例如下一时刻(i,j) 的值取当前时刻它的8邻点的平均,那么怎么用MapReduce来实现。
分析:
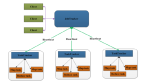
首先,让我们以WordCount为例来解释MapReduce是怎么工作的。
原始状态下,输入–Map — Shuffle — Reduce — 输出
假设有如下的两个文本文件来运行WorkCount程序:
- Hello World Bye World
- Hello Hadoop GoodBye Hadoop
map数据输入
Hadoop针对文本文件缺省使用LineRecordReader类来实现读取,一行一个key/value对,key取偏移量,value为行内容。
如下是map1的输入数据:
- Key1 Value1
- 0 Hello World Bye World
如下是map2的输入数据:
- Key1 Value1
- 0 Hello Hadoop GoodBye Hadoop
map输出/combine输入
如下是map1的输出结果
- Key2 Value2
- Hello 1
- World 1
- Bye 1
- World 1
如下是map2的输出结果
- Key2 Value2
- Hello 1
- Hadoop 1
- GoodBye 1
- Hadoop 1
combine输出 Combiner类实现将相同key的值合并起来,它也是一个Reducer的实现。
如下是combine1的输出
- Key2 Value2
- Hello 1
- World 2
- Bye 1
如下是combine2的输出
- Key2 Value2
- Hello 1
- Hadoop 2
- GoodBye 1
combiner视业务情况来用,减少MAP->REDUCE的数据传输,提高shuffle速度,就是在map中再做一次reduce操作。combiner使用的合适,可以在满足业务的情况下提升job的速度,如果不合适,则将导致输出的结果不正确。
对于wordcount来说,value就是一个叠加的数字,所以map一结束就可以进行reduce的value叠加,而不必要等到所有的map结束再去进行reduce的value叠加。
reduce输出
Reducer类实现将相同key的值合并起来。
如下是reduce的输出
- Key2 Value2
- Hello 2
- World 2
- Bye 1
- Hadoop 2
- GoodBye 1
即实现了WordCount的处理。
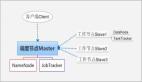
下图是官方的流程图:
有了这个基础知识,我们来看如何用MapReduce来解决上述问题。
以下标对作为map的key,遇到(i,j),生成(i-1,j-1),(i-1,j),etc,然后在reduce时merge相同的key,并计算value。
当你理解了MapReduce的工作原理,是不是很简单?