Linux内核使用伙伴系统来解决内存分配引起的外部碎片问题。伙伴系统分配器大体上分为两类。__get_free_pages()类函数返回分配的第一个页面的线性地址;alloc_pages()类函数返回页面描述符地址。不管以哪种函数进行分配,最终会调用alloc_pages()进行分配页面。
为清楚了解其分配制度,先给个伙伴系统数据的存储框图。
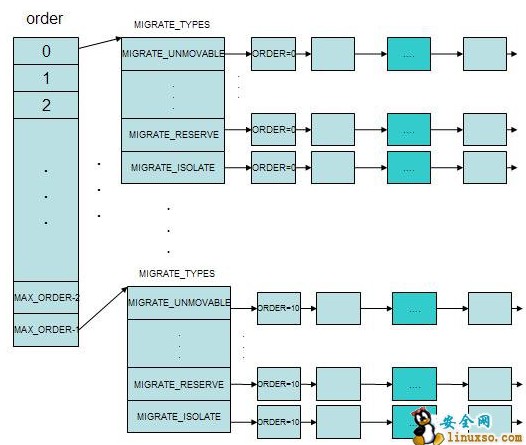
也就是每个order对应一个free_area结构,free_area以不同的类型以链表的方式存储这些内存块。
一、页框的管理
所有的页框描述符都存放在mem_map数组中。
1、page数据结构
- struct page {
- page_flags_t flags; //标志
- atomic_t _count;//该页框的引用计数,该引用计数为-1时表示该页框是个空闲页框
- atomic_t _mapcount;//页框在页表项中的数目,即该页框在多少个页表中被引用为页表 项
- unsigned long private;//可用于多种内核成分,若该页为缓冲区所组成的页,其用来组 织缓冲区首部链表
- struct address_space *mapping;//当页面属于页高速缓存时指向对应文件的 address _space ,当页面属于匿名区时,指向anon_vma描述符,anon_vma中有链表链接所有的vm_area_struct.
- pgoff_t index; //存放换出页标识符或者在页磁盘映像或者匿名区中的数据块的位置
- struct list_head lru; //将页面链入最近最少使用链表中
- };
2、页框管理区
- struct zone {
- unsigned long free_pages;//管理区空闲页的数目
- unsigned long pages_min, pages_low, pages_high;
- //pages_min记录了管理区保留页的数目,pages_low,pages_high
- //分别是用于页面回收的阈值
- struct per_cpu_pageset pageset[NR_CPUS];//pageset用于各个cpu的单一页面缓存,用于伙伴系统
- spinlock_t lock; //用于保护的自旋锁
- struct free_area free_area[MAX_ORDER];//标示出管理区的空闲页面,用于伙伴系统
- spinlock_t lru_lock; //用于保护lru链表的自旋锁
- struct list_head active_list;//记录管理区内处于active状态页面的链表
- struct list_head inactive_list;//记录管理区内处于inactive状态页面的链表
- unsigned long nr_scan_active;//回收时需要扫描的活跃页数目,与页面回收扫描时的优先级有关
- unsigned long nr_scan_inactive;//回收时需要扫描的非活跃页数目
- unsigned long nr_active;//管理区内活跃页的数目
- unsigned long nr_inactive;//管理区内非活跃页的数目
- unsigned long pages_scanned;//回收页框时使用的计数器
- int all_unreclaimable;//管理区内都是不能回收的页面时,置此标记位
- int temp_priority; //当前回收页面时的优先级
- int prev_priority; //上次回收页面时的优先级
- wait_queue_head_t * wait_table;//进程等待队列的散列表,可能进程正在等待管理区中的某页
- unsigned long wait_table_size;//散列表的大小
- unsigned long wait_table_bits;//散列表数组大小
- struct pglist_data *zone_pgdat;//管理区所属的内存节点
- struct page *zone_mem_map;//指向管理区的第一个页描述符
- unsigned long zone_start_pfn;//管理区第一个页框的下标
- unsigned long spanned_pages;//以页为单位的管理区的大小
- unsigned long present_pages;//以页为单位的管理区的大小,不包括洞
- char *name;//管理区名称
- } ____cacheline_maxaligned_in_smp;
3、内存节点
Linux2.6支持numa的计算机模型,在这种模型中,cpu对不同的内存单元的存取访问时间是不一样的,系统的物理内存被划分为几个节点,在给定的节点内,任一给定的cpu对内存的访问时间都是一样的,当然不同的cpu访问该节点的内存其访问时间是不一样的,内核需要把cpu访问节点的时间降到最小,这就要小心的选择cpu常用内核数据所在的内存节点的位置。
节点描述符用pg_data_t数据结构来表示。
- typedef struct pglist_data {
- struct zone node_zones[MAX_NR_ZONES];//该节点上内存管理区数组
- struct zonelist node_zonelists[GFP_ZONETYPES];//zonelist数组,用于内存分配器进行内存分配
- int nr_zones;//内存管理区的个数
- struct page *node_mem_map;//该节点内存的起始内存描述符
- struct bootmem_data *bdata;
- unsigned long node_start_pfn;//该节点内存的起始内存的下标
- unsigned long node_present_pages; //节点的大小,不包括洞
- unsigned long node_spanned_pages; //节点的大小,包括洞
- int node_id;//节点id
- struct pglist_data *pgdat_next;//用于组成内存节点链表
- wait_queue_head_t kswapd_wait;//kswapd进程使用的等待队列,平时kswapd会睡眠在该队列上
- struct task_struct *kswapd; //该内存节点上用于内存回收的kswapd内存描述符,该进程在alloc_page内存不足时,会被激活
- } pg_data_t;
下面的图表明了内存节点,内存管理区和page之间的关系,page->flag的低几位保存了node id和zone id。
二、伙伴系统
通常我们用alloc_pages(), alloc_page(), __get_free_pages(), __get_free_page(), get_zeroed_page() 来获取页框,前两个返回的是页描述符的地址,后面两个返回的是物理页的线性地址。高端内存的分配只能通过前两个分配函数,后面两个由于是线性地址,不可以直接使用。这四个函数接口最终都会调用到伙伴系统的相关接口进行内存的分配工作。
linux内核的伙伴算法最大限度的减少了内存的碎片,其实应该说成是尽自己最大的努力减少了内存的碎片。其思想就是将物理内存分成11个块链表,每个链表包含的是大小为1,2,4,8...512,1024的连续页框块。举例来说要分配256个连续页框,会先到块大小为256的链表中查找空闲块,若有直接返回,若没有,去大小为512的链表中进行查找,将512大小块分为两部分,一部分返回,一部分插入256大小的链表中,若512大小的链表中还没有,到1024大小的链表中查找,取出256大小的块,将剩下的512,256的块分别插入到各个链表中,内存释放的过程则是相反的。
在分配过程中由大块分解而成的小块中没有被分配的块将一直等着被分配的块被释放从而和其合并,合并的操作正是在页面释放的过程中,最终的结果就是相当与没有分解大块,伙伴系统一直在向这个结果收敛,这就是为何伙伴系统能避免碎片的原因。伙伴系统在分配和释放两个方向上执行分解和合并两个互逆的操作,如果一开始系统没有碎片,那么最终的碎片将最小化,因为互逆的操作将最大力度的抵消碎片的产生,这就是精髓了。
伙伴系统的算法主要使用了zone描述符中的zone_mem_map字段和free_area数组,zone_mem_map指向了内存管理区的物理页的起始地址,free_area则代表着我们上面提到的11个链表。
- struct free_area {
- struct list_head
- free_list;//块链表头
- unsigned long *map;//块分配的位图
- };
struct free_area中的free_list字段是空闲内存块的链表头,空闲内存块通过内存描述符的lru字段链接成链表,一个大小为1024页框的内存块中,其第一个页框的private字段保存了对应的order即10,第一个页框也有一个标记位,表明是否是buddy的内存块。在页框被释放时用该字段判断是否可以和它的伙伴内存块合为更大的内存块。
1、内存块的分配
- static struct page *__rmqueue(struct zone *zone, unsigned int order)
- {
- struct free_area * area;
- unsigned int current_order;
- struct page *page;
- //从order大小的内存块链表开始进行遍历
- for (current_order = order; current_order < MAX_ORDER; ++current_order) {
- //找到current_order对应的内存块链表
- area = zone->free_area + current_order;
- //内存块链表为空,继续下一个内存块链表
- if (list_empty(&area->free_list))
- continue;
- //通过内存块包含的第一个page的lru将其从空闲链表上摘链
- page = list_entry(area->free_list.next, struct page, lru);
- list_del(&page->lru);
- //清除page的buddy标记,将private置为0
- rmv_page_order(page);
- area->nr_free--;
- zone->free_pages -= 1UL << order;
- //将current_order大小的内存块刨去order大小后,将其余的内存页面分布到
- //各个空闲链表中
- expand(zone, page, order, current_order, area);
- return page;
- }
- return NULL;
- }
2、内存块的释放
- static inline void __free_one_page(struct page *page,
- struct zone *zone, unsigned int order)
- {
- unsigned long page_idx;
- int order_size = 1 << order;
- if (unlikely(PageCompound(page)))
- destroy_compound_page(page, order);
- page_idx = page_to_pfn(page) & ((1 << MAX_ORDER) - 1);
- //增加空闲页面的值
- zone->free_pages += order_size;
- while (order < MAX_ORDER-1) {
- unsigned long combined_idx;
- struct free_area *area;
- struct page *buddy;
- //找到对应的伙伴块
- buddy = page + (page_idx^(1<<order) -page_idx);
- //判断页面与伙伴块能否合为一个内存块
- if (!page_is_buddy(page, buddy, order))
- break; /* Move the buddy up one level. */
- //将伙伴块从空闲链表上摘除掉
- list_del(&buddy->lru);
- area = zone->free_area + order;
- area->nr_free--;
- rmv_page_order(buddy);
- //得到合并后的内存块的page index
- combined_idx = __find_combined_index(page_idx, order);
- //获取合并后内存块的起始page
- page = page + (combined_idx - page_idx);
- page_idx = combined_idx;
- order++;
- }
- //设置page->private字段,表明内存块的大小
- set_page_order(page, order);
- //插入到对应内存块的空闲链表中
- list_add(&page->lru, &zone->free_area[order].free_list);
- zone->free_area[order].nr_free++;
- }
3、每CPU页框高速缓存
系统中很多情况下只是去申请单一的页框,提供一个单个页框的本地高速缓存对于提高单一页框的效率会有很大的帮助,每个内存管理区都定义了一个每cpu的页框高速缓存,每个高速缓存都会存放一些页框,用于满足本地cpu发出的分配单一页框的请求。
每个内存缓冲区为每个cpu提供了2个页框高速缓存:热页框高速缓存和冷页框高速缓存,热高速缓存用于大多数的情况,如果获取到页面,cpu立刻进行读或者写操作的话,可以改善硬件高速缓存的使用效率,冷高速缓存通常用与dma传输等情况,这种情况无需使用硬件高速缓存。
每cpu页框高速缓存的主要数据结构在zone的pageset字段,类型为per_cpu_pageset,
- struct per_cpu_pageset {
- struct per_cpu_pages pcp[2];
- /* 0: hot. 1: cold */
- }
- struct per_cpu_pages {
- int count; //本地高速缓存页面的个数
- int high; //高水位,当本地高速缓存页面数超过high时,即需要清空
- int batch; //没有页框,或者页框数超过high时,向伙伴系统申请或者释放batc个 页框
- struct list_head list;
- //本地高速缓存页框链表
- };
分配单一页框使用的内核函数是buffered_rmqueue()
- static struct page *buffered_rmqueue(struct zonelist *zonelist,
- struct zone *zone, int order, gfp_t gfp_flags)
- {
- unsigned long flags;
- struct page *page;
- //获取标记位,决定从冷还是热本地页框高速缓存中获取页面
- int cold = !!(gfp_flags & __GFP_COLD);
- int cpu;
- again:
- //获取本地cpu
- cpu = get_cpu();
- //分配单一页面,到高速缓存中获取
- if (likely(order == 0)) {
- struct per_cpu_pages *pcp;
- pcp = &zone_pcp(zone, cpu)->pcp[cold];
- local_irq_save(flags);
- //本地高速缓存中已经没有了,填充本地高速缓存
- if (!pcp->count) {
- //到伙伴系统中分配页面填充到本地高速缓存,每次去伙伴系统中
- //分配1个页面,分配batch各页面为止
- pcp->count += rmqueue_bulk(zone, 0,
- pcp->batch, &pcp->list);
- if (unlikely(!pcp->count))
- goto failed;
- }
- //从本地高速缓存链表上摘除page
- page = list_entry(pcp->list.next, struct page, lru);
- list_del(&page->lru);
- pcp->count--;
- } else {
- //非分配单一页面,使用__rmqueue()直接去分配即可
- spin_lock_irqsave(&zone->lock, flags);
- page = __rmqueue(zone, order);
- spin_unlock(&zone->lock);
- if (!page)
- goto failed;
- }
- local_irq_restore(flags);
- put_cpu();
- :
- return page;
- failed:
- local_irq_restore(flags);
- put_cpu();
- return NULL;
- }
- 释放单一页框的函数是free_hot_cold_page():
- static void fastcall free_hot_cold_page(struct page *page, int cold)
- {
- //通过page->flag低几位得到其所处的zone
- struct zone *zone = page_zone(page);
- struct per_cpu_pages *pcp;
- unsigned long flags;
- kernel_map_pages(page, 1, 0);
- //根据冷热标记找到对应的本地页框高速缓存对应的链表
- pcp = &zone_pcp(zone, get_cpu())->pcp[cold];
- local_irq_save(flags);
- __count_vm_event(PGFREE);
- //将页面插入对应的链表
- list_add(&page->lru, &pcp->list);
- pcp->count++;
- //若本地页框高速缓存的页面数目超过了pcp->high,将batch个页面
- //归还给伙伴系统
- if (pcp->count >= pcp->high) {
- free_pages_bulk(zone, pcp->batch, &pcp->list, 0);
- pcp->count -= pcp->batch;
- }
- local_irq_restore(flags);
- put_cpu();
- }
三、内存管理区分配器
内存管理区分配器需要满足下列的几个目标:
- 应该保护需要保留的内存池。
- 当页框不足且允许进程阻塞时,应该触发页框回收算法,当一些页框被释放出来,再次进行分配。
- 在尽可能的情况下,保留小而珍贵的ZONE_DMA区的内存。
__alloc_pages()
- struct page * fastcall
- __alloc_pages(gfp_t gfp_mask, unsigned int order,
- struct zonelist *zonelist)
- {
- const gfp_t wait = gfp_mask & __GFP_WAIT;
- struct zone **z;
- struct page *page;
- struct reclaim_state reclaim_state;
- struct task_struct *p = current;
- int do_retry;
- int alloc_flags;
- int did_some_progress;
- might_sleep_if(wait);
- restart:
- //zonelist->zones代表了内存分配时使用内存管理区的顺序
- z = zonelist->zones;
- //一开始先以zone->page_low做为基准进行内存分配
- page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, order,
- zonelist, ALLOC_WMARK_LOW|ALLOC_CPUSET);
- //分配到页框,退出
- if (page)
- goto got_pg;
- //没有分配到页框, 唤醒kswapd进行内存回收
- do {
- wakeup_kswapd(*z, order);
- } while (*(++z));
- //调用kswapd进程回收内存后,进行第二次回收,页面基准值为zone->min_pages,
- alloc_flags = ALLOC_WMARK_MIN;
- //当前进程是实时进程且不在中断中或者进程不允许等待,内存分配会比较
- //紧迫,需要置ALLOC_HARDER标记进一步来缩小内存基准值
- if ((unlikely(rt_task(p)) && !in_interrupt()) || !wait)
- alloc_flags |= ALLOC_HARDER;
- //__GFP_HIGH标志着允许访问紧急内存池
- if (gfp_mask & __GFP_HIGH)
- alloc_flags |= ALLOC_HIGH;
- //通常GFP_ATOMIC是不允许进程休眠来等待内存释放的
- if (wait)
- alloc_flags |= ALLOC_CPUSET;
- //再次获取页面
- page = get_page_from_freelist(gfp_mask, order, zonelist, alloc_flags);
- //获取到了,OK,退出
- if (page)
- goto got_pg;
- //还是无法获取页面,系统内存肯定不足,在非中断和软中断的情况下,进行第三次扫描
- //PF_MEMALLOC标记的意思是不想让内存分配失败,可以动用紧急内存
- if (((p->flags & PF_MEMALLOC) || unlikely(test_thread_flag(TIF_MEMDIE)))
- && !in_interrupt()) {
- //__GFP_NOMEMALLOC表明了不允许没有内存分配,进行第三次扫描,第三次扫描绘忽略阈值判断,
- //动用紧急内存
- if (!(gfp_mask & __GFP_NOMEMALLOC)) {
- nofail_alloc:
- /* go through the zonelist yet again, ignoring mins */
- page = get_page_from_freelist(gfp_mask, order,
- zonelist, ALLOC_NO_WATERMARKS);
- //分配到了页面,退出
- if (page)
- goto got_pg;
- //没有分配到页面,不允许失败
- if (gfp_mask & __GFP_NOFAIL) {
- blk_congestion_wait(WRITE, HZ/50);
- goto nofail_alloc;
- }
- }
- goto nopage;
- }
- //进程不允许睡眠等待,苦逼了,只能返回NULL了
- if (!wait)
- goto nopage;
- rebalance:
- //检查是否有其它进程需要调度运行
- cond_resched();
- /* We now go into synchronous reclaim */
- cpuset_memory_pressure_bump();
- //给进程设定PF_MEMALLOC标记位
- p->flags |= PF_MEMALLOC;
- reclaim_state.reclaimed_slab = 0;
- p->reclaim_state = &reclaim_state;
- //调用内存回收函数进行内存回收
- did_some_progress = try_to_free_pages(zonelist->zones, gfp_mask);
- p->reclaim_state = NULL;
- p->flags &= ~PF_MEMALLOC;
- //内存回收过程可能耗时太多,检查是否有进程需要进行调度
- cond_resched();
- //如果内存回收的确回收到了一些页面
- if (likely(did_some_progress)) {
- //再次尝试回收页面
- page = get_page_from_freelist(gfp_mask, order,
- zonelist, alloc_flags);
- if (page)
- goto got_pg;
- } else if ((gfp_mask & __GFP_FS) && !(gfp_mask & __GFP_NORETRY)) {
- //该情况下页面回收并没有回收到任何页框,或许系统到了
- //危急的时刻了!!!杀死一个其他的进程,然后一切从头再来!
- page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, order,
- zonelist, ALLOC_WMARK_HIGH|ALLOC_CPUSET);
- if (page)
- goto got_pg;
- out_of_memory(zonelist, gfp_mask, order);
- goto restart;
- }
- do_retry = 0;
- //gfp_mask标记中GFP_NORETRY表明了是否允许再次扫描内存管理区
- if (!(gfp_mask & __GFP_NORETRY)) {
- //GFP_REPEAT,GFP_NOFAIL都要求反复对内存管理区进行扫描
- if ((order <= 3) || (gfp_mask & __GFP_REPEAT))
- do_retry = 1;
- if (gfp_mask & __GFP_NOFAIL)
- do_retry = 1;
- }
- //需要再次尝试内存分配的话,调用blk_congestion_wait()等待一会,
- if (do_retry) {
- blk_congestion_wait(WRITE, HZ/50);
- goto rebalance;
- }
- nopage:
- if (!(gfp_mask & __GFP_NOWARN) && printk_ratelimit()) {
- dump_stack();
- show_mem();
- }
- got_pg:
- return page;
- }
- 3.3.2get_page_from_freelist
- 在代码中到伙伴系统分配内存的代码实现实际在get_page_from_freelist()中。
- static struct page *
- get_page_from_freelist(gfp_t gfp_mask, unsigned int order,
- struct zonelist *zonelist, int alloc_flags)
- {
- struct zone **z = zonelist->zones;
- struct page *page = NULL;
- int classzone_idx = zone_idx(*z);
- do {
- if ((alloc_flags & ALLOC_CPUSET) &&
- !cpuset_zone_allowed(*z, gfp_mask))
- continue;
- if (!(alloc_flags & ALLOC_NO_WATERMARKS)) {
- unsigned long mark;
- //alloc_flags决定了mark的大小,mark是衡量是否可以从该内存管理区分配页框的标准
- //用于下面的zone_watermark_ok
- if (alloc_flags & ALLOC_WMARK_MIN)
- mark = (*z)->pages_min;
- else if (alloc_flags & ALLOC_WMARK_LOW)
- mark = (*z)->pages_low;
- else
- mark = (*z)->pages_high;
- //zone中的剩余内存不能达到标准,需要回收内存
- if (!zone_watermark_ok(*z, order, mark,
- classzone_idx, alloc_flags))
- if (!zone_reclaim_mode ||
- !zone_reclaim(*z, gfp_mask, order))
- continue;
- }
- //调用bufferd_rmqueue向伙伴系统申请内存页框
- page = buffered_rmqueue(zonelist, *z, order, gfp_mask);
- if (page) {
- break;
- }
- } while (*(++z) != NULL);
- return page;
- }
- 3.3.3 zone_watermark_ok
- int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
- int classzone_idx, int alloc_flags)
- {
- //基准值是mark,可以使zone->low,high,min中的任何一个值
- long min = mark, free_pages = z->free_pages - (1 << order) + 1;
- int o;
- //如果__GFP_WAIT被置位,通常ALLOC_HIGH被置位,将最小值减去1/2
- if (alloc_flags & ALLOC_HIGH)
- min -= min / 2;
- //如果__GFP_WAIT被置位,如果当前进程是一个实时进程并且已经在进程上下文中,已经完成了
- //内存分配,则alloc_flag中的ALLOC_HARDER被置位,min再减少1/4
- if (alloc_flags & ALLOC_HARDER)
- min -= min / 4;
- //空闲页面少于min 加上管理区的保留页面数
- if (free_pages <= min + z->lowmem_reserve[classzone_idx])
- return 0;
- //对于0-order个大小的页面空闲链表,对于每个链表,都
- //对于order为k的块至少有min/2(k)个页框
- for (o = 0; o < order; o++) {
- /* At the next order, this order's pages become unavailable */
- free_pages -= z->free_area[o].nr_free << o;
- /* Require fewer higher order pages to be free */
- min >>= 1;
- if (free_pages <= min)
- return 0;
- }
- return 1;
- }