【2013年10月11日 51CTO外电头条】本文将 LinkedIn 工程师 Apurva Mehta 在 Blog 上分享的《面向低延迟/高吞吐量数据库(GraphDB)的 Linux 内存管理优化》做了简单的翻译整理,希望对大家有所帮助。
简介
GraphDB在LinkedIn的实时分布式社交图谱服务当中充当着存储层的角色。我们的服务旨在处理简单查询(例如来自LinkedIn成员的一级与二级网络请求)与复杂查询(例如成员之间的距离以及成员之间的关联路径等图谱结果)。我们支持多种节点及边界类型,而且能够直接处理所有正处于执行当中的查询。感兴趣的朋友不妨点击此处的博文,对应用程序使用我们社交图谱的方式进行初步了解。
LinkedIn上的每一个页面视图都会产生多条指向GraphDB的查询请求。这意味着GraphDB每秒钟都要处理成千上万条查询请求,而且99%的查询都能在微秒级别的延迟之内得到响应(通常延迟为十几微秒)。有鉴于此,即使GraphDB的响应延迟提高到仅仅5毫秒,LinkedIn的全局访问效果也将受到严重影响。
在2013年的大部分时段,我们已经发现GraphDB会在使用高峰当中偶尔出现间歇性响应延迟。我们深入调查了这些高峰时段,并努力了解Linux内核如何管理NUMA(即非统一内存访问)系统上的虚拟内存。概括来说,针对NUMA的一部分Linux优化存在严重的负面作用,会因此对延迟产生直接性不利影响。我们认为此次研究的成果足以帮助任何一套运行在Linux系统环境下、对延迟要求较高的在线数据库系统获得性能改进。经过我们的优化调整,问题出现几率(例如响应缓慢或者查询超时的出现比例)已经下降到原先的四分之一。
在文章的***部分,我们将共同了解相关背景资料,包括:GraphDB在数据管理方面的流程大纲、性能问题的具体表现以及Linux虚拟内存管理(简称VMM)子系统的运作方式。在文章的第二部分,我们将详细探讨解决办法、指导意见以及结论汇总,旨在通过实验找到问题出现的根源。***,我们将归纳通过此次实例所获得的经验。
本文适合对操作系统运行机制具备一定了解的朋友。
背景资料
1) GraphDB如何管理数据
GraphDB在本质上是一种内存内数据库。在读取方面,我们将所有数据文件映射到虚拟内存页面当中,并始终将其保留在内存中的活动集之下。我们的读取活动具备很强的随机性,指向目标遍布整个数据集,且99%的请求都要求将延迟控制在微秒级别。一台典型的GraphDB主机能够拥有48GB物理内存,常用内存量为20GB:其中15GB用于处理堆外虚拟内存页面映射数据,5GB用于JVM堆。
而在写入方面,我们拥有一套日志-结构化存储系统。我们将全部数据划分为以10MB为单位的纯追加部分。目前,每一台GraphDB主机大约拥有1500个活动部分,其中只有25个能够随时接受写入操作,其它1475个则处于只读状态。
由于数据采用日志结构化存储方式,我们需要定期对其进行压缩。此外,由于我们所采取的压缩计划比较积极,因此每天每台主机上约有九百个数据片段会被遗弃。换言之,每天每台主机上约有容量达9GB的数据文件彻底消失,但这还仅仅是LinkedIn全局数据增量中的一小部分。概括来讲,每台48GB主机在运行五天之后页面缓存就会被垃圾堆满。
2) 问题症状
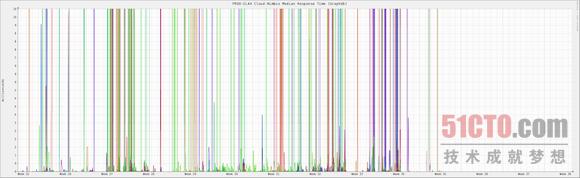
我们所遇到的性能问题主要表现为在使用高峰期GraphDB出现响应延迟。在高峰期出现的同时,我们往往会面临数量庞大的直接页面扫描以及内存执行效率低下等困扰,具体情况如sar所示。在个别情况下,sar -B 下"每秒pqsand(pqscand/s)"列的输出效率将拖慢至每秒100万到500万页面扫描,虚拟内存效率也会降至0%--这些症状往往会持续数小时。
在性能表现急剧下滑的过程中,系统的内存压力却并不明显:这是因为我们可以通过/proc/meminfo的记录看到大量无效缓存页面。此外,并不是pqscand/s中的所有高峰时段都会引发GraphDB的延迟问题。
最让我们感到困惑的两个问题是:
1、如果系统中不存在明显的内存压力,为什么系统内核会对页面进行扫描?
2、即使内核开始对页面进行扫描,为什么我们的响应延迟会急剧升高?只有写入线程需要占用新的内存分配,而且写入与读取线程池是彼此独立的。因此,为什么实际结果是双方会相互产生影响?
正是这些问题的答案促使我们对NUMA系统的Linux优化方案做出调整。需要强调的是,我们最终将注意力集中在了Linux的"区回收(zone reclaim)"功能方面。如果大家对于NUMA、Linux以及区回收不太了解,别担心,我们会在下一部分内容中做出详细讲解。在这些资料的辅助下,大家应该可以顺利理解文章其它部分的论证过程。
3) 关于Linux、NUMA以及区回收的那些事儿
要想深入理解问题产生的根源,我们首先需要明确Linux系统如何处理NUMA架构。我为大家甄选了一部分优秀的讲解资源,希望能帮助各位快速掌握相关的背景知识:
- Jeff Frost:《Linux中的PostgreSQL、NUMA以及区回收模式》 。 如果大家时间有限,优先推荐各位阅读这篇文章。
- Christoph Lameter:《非统一内存访问概述》。大家需要着重阅读其中关于Linux如何从NUMA区中回收内存的部分。
- Jeremy Cole:《MySQL“交换错乱”问题以及NUMA架构的影响》。
同样重要的是,大家需要理解Linux从页面缓存中使用回收页面的具体机制。
简而言之,Linux为每个NUMA区保留着一组三个页面列表:活动列表、非活动列表以及空闲列表。新页面进行分配时会被从空闲列表转移到活动列表。而LRU算法则负责将页面从活动列表转移到非活动列表,而后再由非活动列表转移至空闲列表。下面我为大家推荐一份学习Linux页面缓存管理知识的***资料:
- Mel Gorman: 《了解Linux虚拟内存管理器》,第十三章:页面回收。
我们首先认真阅读了上述资料,而后尝试关闭掉生产主机上的区回收模式。关闭之后,我们的性能表现立刻获得显著提升。有鉴于此,我们决定在本文中详细描述区回收的运作机制以及对性能造成影响的原因。
本文的其它内容深入探讨了Linux区回收的相关内容,如果大家对区回收还不太熟悉,请首先阅读前文推荐的Jeff Frost的相关论述。
重现并理解Linux的区回收活动
1) 设置实验环境
为了理解区回收的触发原理以及区回收如何影响性能表现,我们编写了一款程序,用于模拟GraphDB的读取与写入活动。我们以二十四小时为期限运行该程序,在前面十七个小时内、我们开启了区回收模式。而在***七个小时中,我们关闭了区回收模式。该程序在整个二十四小时当中不间断地运行,环境中的惟一变化就是在第十七小时通过向/proc/sys/vm/zone_reclaim_mode中写入"0"来禁用区回收。
下面我们来解读该程序的运行内容:
1、它将2500个10MB数据文件映射至页面缓存当中,全部读取一遍,而后取消映射,这样Linux页面缓存当中就充斥着垃圾数据。如此一来,系统的运行状态类似于GraphDB主机在正常运行数天后的情况。
2、一组读取线程会将另一组2500个10MB文件映射至页面缓存当中,再随机读取其中的一部分内容。这2500个文件构成了活动集合,用于模拟GraphDB在日常使用中的读取状态。
3、一组写入进程不断创建10MB文件。一旦某个文件创建完成,写入线程就会从活动集合中随机挑选一个文件、取消其映射并用刚刚创建的新文件加以取代。这一过程旨在模拟GraphDB在日常使用中的写入活动。
4、***,如果读取线程完成读取所消耗的时间超过100毫秒,则自动输出该次访问流程的usr、sys以及elapsed time。这使我们得以成功追踪到读取性能的变化轨迹。
我们用于运行该程序的主机拥有48GB物理内存。我们的工作组大约占用了其中的25GB,除此之外系统中没有运行其它任何任务。通过这种方式,我们保证主机不会遇到任何形式的内存压力。
大家可以点击此处在Github上查看我们的模拟流程。
2) 了解区回收机制如何被触发
当某个进程针对页面发出请求时,系统内核会首先检查***NUMA区是否拥有足够的空余内存以及是否存在1%以上可以回收的页面。这一百分比可以调节,并由vm.min_unmapped_ratio sysctl来决定。可回收页面属于由文件支持的页面(即与页面缓存存在映射关系的文件所产生的页面),但其目前并未被映射到任何进程当中。在/proc/meminfo中,我们可以很清楚地看到,所谓"可回收页面(reclaimable pages)"就是那些"活动(文件)-非活动(文件)-被映射"(Active(file)+Inactive(file)-Mapped)的内容。
那么系统内核如何判断多少空闲内存才够用呢?内存会使用区"水平标记(watermarks)",通过/proc/sys/vm/min_free_kbytes 中的值来进行判断。它们同时也会检查/proc/sys/vm/lowmem_reserve_ratio 中的值。特定主机内经过计算的值会被保存在/proc/zoneinfo 当中,并搭配如下所示的"低/中/高(low/min/high)"标签:
- Node 1, zone Normal
- pages free 17353
- min 11284
- low 14105
- high 16926
- scanned 0
- spanned 6291456
- present 6205440
内存会在区内空闲页面数量低于水平标记时执行页面回收。而当空闲页面的数量高于"低"水平标记后,页面回收操作就会中止。此外,这一计算过程针对的是各独立区:即使其它区仍拥有足够的空闲内存,只要当前区被触发,回收机制就会付诸实施。
下面我们通过图表来展示实验过程中的活动表现。其中值得注意的包括以下几点:
- 黑色线条代表区中的页面扫描,并以右侧的y轴为基准生成图形。
- 红色线条代表区中的空闲页面数量。
- 绿色线条代表的是"低"水平标记。
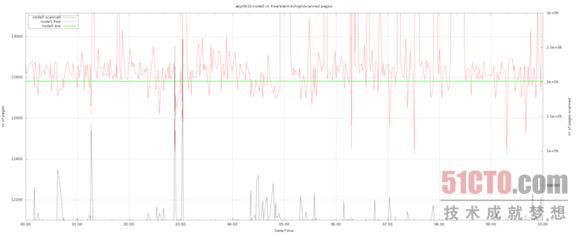
通过实验,我们观察到了与生产主机类似的表现。在所有情况下,页面扫描情况都与空闲页面情况保持吻合--二者的数值恰好相反。换句话来说,Linux会在空闲页面数量低于"低"水平标记时触发区回收机制。
3) 系统区回收机制的特性
理解了区回收模式的触发原理,下面我们将关注重点放在其它方面--区回收模式如何影响性能表现。为了实现这一目标,我们在实验过程中每秒一次收集来自下列源的信息:
- /proc/zoneinfo
- /proc/vmstat
- /proc/meminfo
- numactl -H
在根据这些文件中的数据绘制图表并总结活动模式后,我们发现了一些非常有趣的特性--这些特性正是解答区回收机制对读取性能产生负面影响的关键所在。
在前期观察中,区回收机制处于启用状态,这时Linux执行的大多是直接回收(即回收任务在应用程序线程内直接执行,并被计作直接页面扫描)。一旦区回收模式被关闭,直接回收活动立刻停止,但由kswapd执行的回收数量却开始增加。这就解释了我们为何会在sar中观察到每秒pqscand如此之高:

其次,即使我们的读取与写入操作并未发生变化,Linux活动与非活动列表内的页面数量也在区回收模式关闭后发生了显著变化。需要强调的是,在区回收机制的开启时,Linux会在活动列表中保留总大小约20GB的页面信息。而在区回收机制关闭后,Linux在活动列表内的信息保留量增加到约25GB,这正是我们整个工作集的大小:
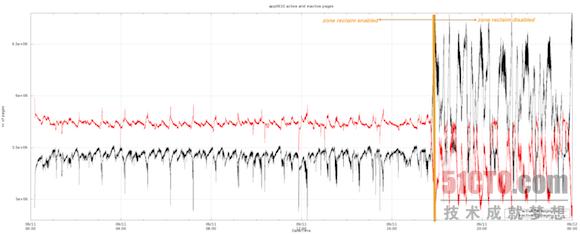
***,我们观察到在区回收模式被关闭后,页面内活动出现了显著差别。值得关注的一点在于,虽然从页面缓存到磁盘驻留的速率保持不变,但区回收被关闭后从磁盘驻留到页面内的速率显著降低。主要故障率的变动情况与页面内传输速率完全一致。下面的图表证明了这一结论:
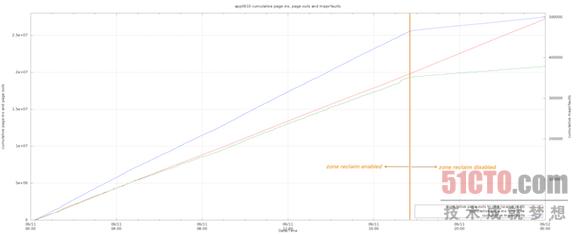
***,我们发现程序中的高占用内存访问活动的数量在区回收模式被关闭后大幅减少。以下图表显示了内存访问延迟(单位为毫秒)以及响应时间在系统及用户CPU层面的具体消耗。可以看到,该程序的大部分运行时间被消耗在了I/O等待方面,而且偶尔还会在系统CPU当中遭遇阻塞。
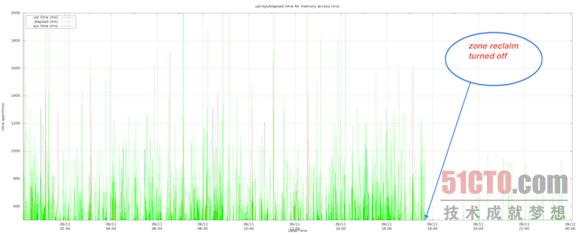
4) 区回收模式如何影响读取性能
基于以上统计结果,看起来由区回收所触发的直接回收途径似乎在将页面从活动列表中移除并转移到非活动列表方面表现得太过激进。特别是在区回收机制启用时,活动页面似乎会被直接清盘并被塞进非活动列表,而后再被移出到空闲列表当中。有鉴于此,读取活动会遭遇极高的主要故障机率,性能表现也变得一落千丈。
导致问题进一步加剧的则是shrink_inactive_list函数,作为直接回收路径的组成部分、它似乎在区中采用了一种全局自旋锁,从而阻止其它线程在回收过程中对区产生修改。正因为如此,我们才会在高峰时段发现系统CPU在读取线程中出现锁定,这很可能是因为多个线程之间存在冲突。
NUMA内存平衡机制同样会触发直接页面扫描
我们刚刚了解了区回收模式如何触发直接页面扫描,也证实了这类将页面数据挤出活动列表的粗暴扫描正是读取性能下滑的罪魁祸首。除了区回收之外,我们还发现一项名为Transparent HugePages (简称THP)的红帽Linux功能在对NUMA区进行内存"平衡调整"时同样会触发直接页面扫描。
在THP功能的推动下,系统会以透明化方式为匿名(即非文件支持)内存分配2MB"大型页面"。这种做法能够提高TLB中的命中率并降低系统中页面列表的大小。红帽方面表示,THP在特定工作负载中能够带来高达10%的性能提升。
另外,由于这项功能以透明化方式运作,因此它还利用一部分代码将大型页面分割成多个常规页面(在/proc/vmsat中被统计为thp_split),或者将多个常规页面汇聚成巨大页面(被统计为thp_collapse)。
我们已经看到,即使区中不存在内存压力,thp_split仍然会导致很高的直接页面扫描比率。我们还发现Linux系统会将我们的5GB Java堆分割成巨大页面,从而将其在不同NUMA区之间进行移动。大家请看如下图表:总大小约5GB、来自两个NUMA区的数据被分割成巨大页面,其中一部分被从Node 1移动到了Node 0。这类活动必然会带来很高的直接页面扫描比率。

我们无法在自己的实验环境下重现这一状况,而且这似乎也不能算是导致直接页面扫描的常见原因。不过我们手中有大量数据可以证明,Transparent HugePages功能与NUMA系统的协作效果并不理想,因此我们决定在自己的RHEL设备上运行下列命令来禁用该功能。
- echo never > /sys/kernel/mm/transparent_hugepage/enabled
经验教训
1) Linux的NUMA优化对于典型数据库负载并无意义
数据库的主要性能提升源自在内存中对大量数据进行缓存处理,而NUMA优化并不能做到这一点。需要强调的是,利用内存缓存规避磁盘读写所节约的时间要远远超过将内存接入多插槽系统中特定插槽所换来的延迟改进。
Linux的NUMA优化机制可以通过以下几种方式禁用,从而提高性能表现:
- 关闭区回收模式:向 /etc/sysctl.conf 中添加vm.zone_reclaim_mode = 0并运行sysctl -p以载入新设定。
- 为自己的应用程序启用NUMA交叉存取功能: 在运行应用时加入numactl --interleave=all 命令。
以上两种设置已经成为我们全部生产系统中的默认状态。
2) 不要对Linux设置掉以轻心:亲手管理页面缓存中的垃圾内容
由于GraphDB的日志结构化存储系统无法重新使用其数据片段,因此承受着时间的推移我们在Linux页面缓存中产生了大量垃圾内容。事实证明,Linux在正确清理这类垃圾内容时表现得相当糟糕:它通常会不由分说地把一切数据扔进废纸篓,这种过分激进的处理方式令我们的读取性能遭遇极高的主要故障比率。直接回收与kswapd都起到了助纣为虐的作用,但前者的负面作用更为明显。
我们已经为自己的存储系统添加了片段池,这样我们就能够重复使用这些片段。通过这种方式,我们降低了需要创建的文件数量,同时减小了对Linux页面缓存造成的处理压力。通过初步测试,我们发现片段池机制带来了令人鼓舞的出色效果。
写在***的话
自从对区回收机制产生怀疑,我们就立即着手在生产系统中关闭这一模式。事实证明,我们的调整带来了显著成效。在过去的四个月中,我们的生产主机一直处于中位延迟状态下。不必掌声鼓励、也无需鲜花簇拥,关闭区回收机制这样一个小小的决定让LinkedIn迎来了显而易见的性能提升--这正是我们技术人员的***乐趣!