












在html 5中,其中一个引人注意的新特性,那就是允许使用Indexed DB。用户可以从这个链接(http://www.w3.org/TR/IndexedDB/)了解到Indexed DB的详细标准。在本文中,将对Indexed DB作简单的入门介绍。
概述
从本质上说,IndexedDB允许用户在浏览器中保存大量的数据。任何需要发送大量数据的应用都可以得益于这个特性,可以把数据存储在用户的浏览器端。当前这只是IndexedDB的其中一项功能,IndexedDB也提供了强大的基于索引的搜索api功能以获得用户所需要的数据。
用户可能会问:IndexedDB是和其他以前的存储机制(如cookie,session)有什么不同?
Cookies是最常用的浏览器端保存数据的机制,但其保存数据的大小有限制并且有隐私问题。Cookies并且会在每个请求中来回发送数据,完全没办法发挥客户端数据存储的优势。
再来看下Local Storage本地存储机制的特点。Local Storage在HTML 5中有不错的支持,但就总的存储量而言依然是有所限制的。Local Storage并不提供真正的“检索API”,本地存储的数据只是通过键值对去访问。Local Storage对于一些特定的需要存储数据的场景是很适合的,例如,用户的喜好习惯,而IndexedDB则更适合存储如广告等数据(它更象一个真正的数据库)。
在我们进一步探讨Indexed DB前,我们先看下目前的主流浏览器对Indexed DB的支持。 IndexedDB目前依然是一个w3c中候选的建议规范,在这一点上规范目前还是令人感到满意的,但现在正在寻找开发者社区的反馈。该规范可能会在到***确认阶段前会因应w3c的建议有所变化。在一般情况下,目前的浏览器对IndexedDB的支持都以比较统一的方式实现,但开发者应注意在未来的更新及对此作出一定的修改。
我们来看来自CanIUse.com的对于各浏览器对IndexedDB的支持的图表,可以看到,目前桌面端浏览器对其的支持是不错的,但移动端浏览器的支持就比较少了:
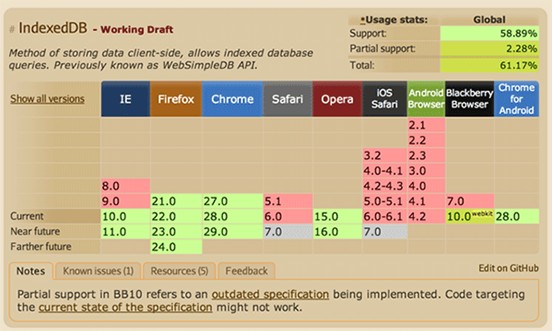
Chrome for Android支持IndexedDB,但很少人目前在Android设备上使用这款浏览器。是否缺乏移动端浏览器的支持就意味着不应该使用它呢?当然不是!幸好我们的开发者都懂得持续改进的概念。象IndexedDB这样的特性可以用其他的方式添加到那些不支持该功能的浏览器中。用户可以使用包装过的类库去转换到移动端的WebSQL,又或者干脆不在移动端进行本地存储数据。我个人认为能在客户端缓存大量的数据,对使用上来说是很重要的功能,即使缺乏移动端的支持。
开始学习
首先,在使用IndexedDB前,要做的是检查当前的浏览器对IndexedDB是否支持,做法只需要使用如下代码就可以实现:
document.addEventListener("DOMContentLoaded", function(){
if("indexedDB" in window) {
console.log("YES!!! I CAN DO IT!!! WOOT!!!");
} else {
console.log("I has a sad.");
}
},false);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
上面的代码中(可以在本文下载代码中的test1.html中找到),使用了DOMContentLoaded事件在加载的过程中,通过判断在window对象中是否存在indexedDB,当然为了在接下来的过程中记住判断的最终结果,可以使用如下的代码更好地保存(test2.html):
var idbSupported = false;
document.addEventListener("DOMContentLoaded", function(){
if("indexedDB" in window) {
idbSupported = true;
}
},false);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
操作数据库
下面要讲解的是如何操作IndexedDB数据库。首先要了解的是,IndexedDB并不象传统的如SQL Server那样需要额外安装。Indexed是存在于浏览器端的并且能被用户所访问控制。IndexedDB和cookies和local storage的原则是一样的,就是一个IndexedDB是和一个唯一的DOMAIN相关联的。比如名为“Foo”的数据库是由foo.com所关联的,是不会和goo.com所创建的同名“Foo”数据库冲突的,因为他们属于不同的domain,并且他们之间是不能互相访问的。
打开一个数据库是通过命令执行的。基本的用法是提供数据库的名称和版本号即可,其中版本是十分重要的,稍候会作解析。下面是基本的例子:
var openRequest = indexedDB.open("test",1);
- 1.
打开一个IndexedDB数据库是异步的操作。为了处理操作的返回结果,需要增加一些事件的监听,目前有四种不同类型的事件监听事件:
- success
- error
- upgradeneeded
- blocked
大家可能已经能知道success和error事件的含义了。而upgradeneeded事件是在***打开数据库或者改变数据库版本的时候被触发。blocked事件是在前一个连接没有被关闭的时候被触发。
让我们看下接下来的例子(test3.html),其中当***访问网站的时候会触发upgradeneeded事件,然后是success事件。
var idbSupported = false;
var db;
document.addEventListener("DOMContentLoaded", function(){
if("indexedDB" in window) {
idbSupported = true;
}
if(idbSupported) {
var openRequest = indexedDB.open("test",1);
openRequest.onupgradeneeded = function(e) {
console.log("Upgrading...");
}
openRequest.onsuccess = function(e) {
console.log("Success!");
db = e.target.result;
}
openRequest.onerror = function(e) {
console.log("Error");
console.dir(e);
}
}
},false);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
#p#
在上面的代码中,我们再一次检查当前浏览器是否支持IndexedDB,如果支持,则打开一个数据库。在这段代码中我们使用了三个事件 ――upgrade事件、成功事件和错误事件。首先看success事件,该事件通过target.result传入句柄,然后将其复制到一个全局变量db中,用作稍候添加数据用。如果用户在支持IndexedDB的浏览器中运行上面的代码,应该会在控制台看到看到Upgrading...和success的输出信息,如果再次运行的话,则只会看到输出成功的信息,因为upgradedneed事件只在***打开数据库或升级的时候被调用。
对象存储
接下来,我们学习如何存储数据。IndexedDB有一个概念称为“对象存储”。
用户可以认为这是一张典型的关系数据库中的表。对象中当然会存储了数据,但也有一个keypath和可选的索引集合。所谓的Keypaths是用户数据的唯一标识,并且可以用不同的格式表示。索引则在后面会进行讲解。
还记得之前提到的upgrademeeded事件么?要注意的是只能在upgradeneeded事件中创建一个对象。目前,默认是在用户***访问你的网站的时候会自动创建对象。同时如果要修改你的对象,则必须更新数据的版本,并且要为此编写代码,让我们来看代码的例子如下:
var idbSupported = false;
var db;
document.addEventListener("DOMContentLoaded", function(){
if("indexedDB" in window) {
idbSupported = true;
}
if(idbSupported) {
var openRequest = indexedDB.open("test_v2",1);
openRequest.onupgradeneeded = function(e) {
console.log("running onupgradeneeded");
var thisDB = e.target.result;
if(!thisDB.objectStoreNames.contains("firstOS")) {
thisDB.createObjectStore("firstOS");
}
}
openRequest.onsuccess = function(e) {
console.log("Success!");
db = e.target.result;
}
openRequest.onerror = function(e) {
console.log("Error");
console.dir(e);
}
}
},false);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
上面的代码(见test4.html)中,请看upgradeneeded事件,首先是通过变量thisDB获得了打开的数据库,这个变量的其中一个属性是一个已存在的对象存储的list,名为objectStoreNames。我们可以使用contains方法检查某个对象是否已经存在了,如果不存在则可以进行创建,使用的方法是createObjectStore,因为这个是IndexedDB的同步操作,因此不需要为此进行事件监听。
总结一下,当用户访问你的网站时,如果用户的浏览器支持IndexedDB,则首先触发的是upgradeneeded事件,代码中检查是否有“firstOS”对象存在,如果没有的话则新创建一个,当用户第二次访问网站的时候,数据库的版本依然和***次访问时是相同的。
假如需要新增加另外一个对象存储,则只需要增加版本号并复制上面contains/ createObjectStore部分的代码,代码如下(见test5.html):
var openRequest = indexedDB.open("test_v2",2);
openRequest.onupgradeneeded = function(e) {
console.log("running onupgradeneeded");
var thisDB = e.target.result;
if(!thisDB.objectStoreNames.contains("firstOS")) {
thisDB.createObjectStore("firstOS");
}
if(!thisDB.objectStoreNames.contains("secondOS")) {
thisDB.createObjectStore("secondOS");
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
如何增加数据
下面我们可以开始增加数据。和传统的关系型数据库有点不同,IndexedDB允许保存对象。这意味着开发者甚至可以保存一个Javascript对象。对于数据查询是需要使用事务,事务需要两个参数,***个是将要处理的表的数组,其中的元素是表,第二个参数是事务的类型。目前有两种事务的类型:只读和读写。增加数据是属于读写操作,代码如下:
var transaction = db.transaction(["people"],"readwrite");
- 1.
这里指出了要设置存储对象people为读写操作,然后使用objectStore指定要操作的存储对象,存储到变量store中去
var store = transaction.objectStore("people");
- 1.
接下来就可以增加数据了,我们定义一个person对象,然后增加到这个store中去:
var person = {
name:name,
email:email,
created:new Date()
}
var request = store.add(person,1);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
可以看到,这里声明了一个Javascript的普通对象,然后使用store的add方法就可以增加这个对象到对象存储中,其中add的第2个参数是标识数据的唯一标识,在这里只是暂时硬编码了,在接下来我们将不再使用硬编码的方法。
要注意增加数据的操作是异步的,所以增加两个事件监听,代码如下:
request.onerror = function(e) {
console.log("Error",e.target.error.name);
}
request.onsuccess = function(e) {
console.log("Woot! Did it");
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
现在我们看下test6.html,这个是包含html的完整代码:
<!doctype html>
<html>
<head>
</head>
<body>
<script>
var db;
function indexedDBOk() {
return "indexedDB" in window;
}
document.addEventListener("DOMContentLoaded", function() {
//No support? Go in the corner and pout.
if(!indexedDBOk) return;
var openRequest = indexedDB.open("idarticle_people",1);
openRequest.onupgradeneeded = function(e) {
var thisDB = e.target.result;
if(!thisDB.objectStoreNames.contains("people")) {
thisDB.createObjectStore("people");
}
}
openRequest.onsuccess = function(e) {
console.log("running onsuccess");
db = e.target.result;
//Listen for add clicks
document.querySelector("#addButton").addEventListener("click", addPerson, false);
}
openRequest.onerror = function(e) {
//Do something for the error
}
},false);
function addPerson(e) {
var name = document.querySelector("#name").value;
var email = document.querySelector("#email").value;
console.log("About to add "+name+"/"+email);
var transaction = db.transaction(["people"],"readwrite");
var store = transaction.objectStore("people");
var person = {
name:name,
email:email,
created:new Date()
}
var request = store.add(person,1);
request.onerror = function(e) {
console.log("Error",e.target.error.name);
//some type of error handler
}
request.onsuccess = function(e) {
console.log("Woot! Did it");
}
}
</script>
<input type="text" id="name" placeholder="Name"><br/>
<input type="email" id="email" placeholder="Email"><br/>
<button id="addButton">Add Data</button>
</body>
</html>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
#p#
在浏览器中运行这段代码,则可以看到如下图的HTML页面,其中在文本框输入内容,点按钮,则会在浏览器的调试工具中(我们使用的是Chrome)看到有如下的输出:
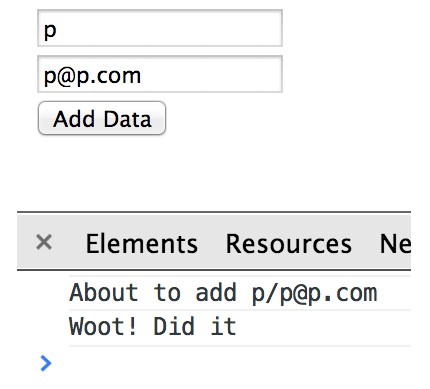
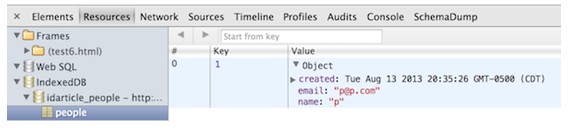
.如果使用Chrome,则可以充分利用其调试工具中对IndexedDB的可视化支持,如果点资源的TAB,展开IndexedDB的部分,则可以看到如下图所示的,我们之前创建的people存储对象。
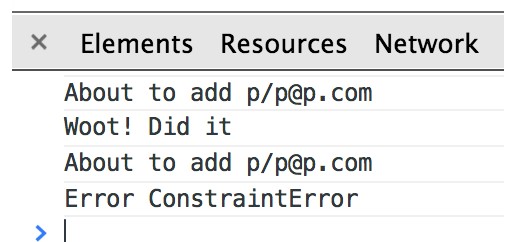
接下来我们尝试再次点击增加按钮,这个时候注意到会输出错误的提示信息如下图,其信息表示试图增加一个已经存储的对象,违反数据约束了:
关于Key
Keys是IndexedDB的主键,传统的关系数据库可以没有keys,但每个对象存储都必须有一个key。IndexedDB允许多个不同类型的KEY。
***种方法是象上文中的那样手工指定。第二种方法是使用keypath,其中的key是基于数据自身的属性,比如people中的例子可以使用email地址作为key。第三种方法是建议采用的方法,就是使用key生成器,这有点象自动编号的主键的方法。下面是关于key的两个例子,其中一个是使用keypath,另外的是使用key生成器:
hisDb.createObjectStore("test", { keyPath: "email" });
thisDb.createObjectStore("test2", { autoIncrement: true });
- 1.
- 2.
并且我们可以修改上一个例子中,用带key的方法创建对象:
thisDB.createObjectStore("people", {autoIncrement:true});
- 1.
这样的话,就可以取消之前硬编码的做法了:
var request = store.add(person);
- 1.
读取数据
再来看如何读取数据,读取数据要在一个事务中进行并且是异步的,下面是例子:
var transaction = db.transaction(["test"], "readonly");
var objectStore = transaction.objectStore("test");
var ob = objectStore.get(x);
ob.onsuccess = function(e) {
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
在上面的代码中,首先设置为只读的事务。然后使用objectStore.get方法就可以了,要注意编写其onsuccess事件,也可以使用链式调用,如下:
db.transaction(["test"], "readonly").objectStore("test").get(X).onsuccess = function(e) {}
- 1.
现在我们在test8.html中,为我们之前的例子加上读取数据的部分,运行后的效果如下图:
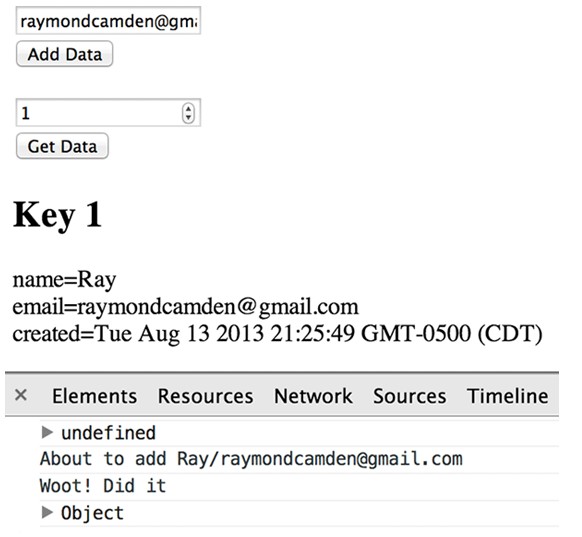
其中读取数据的代码为:
function getPerson(e) {
var key = document.querySelector("#key").value;
if(key === "" || isNaN(key)) return;
var transaction = db.transaction(["people"],"readonly");
var store = transaction.objectStore("people");
var request = store.get(Number(key));
request.onsuccess = function(e) {
var result = e.target.result;
console.dir(result);
if(result) {
var s = "<h2>Key "+key+"</h2><p>";
for(var field in result) {
s+= field+"="+result[field]+"<br/>";
}
document.querySelector("#status").innerHTML = s;
} else {
document.querySelector("#status").innerHTML = "<h2>No match</h2>";
}
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
#p#
如何读取更多数据
如何读取批量的数据?也就是象传统关系数据库中读取数据集?IndexedDB支持游标的概念,这对有数据库基础的读者来说是很容易理解的,下面的代码演示了如何读取数据集:
var transaction = db.transaction(["test"], "readonly");
var objectStore = transaction.objectStore("test");
var cursor = objectStore.openCursor();
cursor.onsuccess = function(e) {
var res = e.target.result;
if(res) {
console.log("Key", res.key);
console.dir("Data", res.value);
res.continue();
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
其中使用objectStore的openCursor打开游标,并且在onsuccess事件中进行处理,注意使用res获得了结果集,然后用res.continue()方法去循环读取记录集。同样,我们用这个方法去遍历之前的people存储集,代码如下:
function getPeople(e) {
var s = "";
db.transaction(["people"], "readonly").objectStore("people").openCursor().onsuccess = function(e) {
var cursor = e.target.result;
if(cursor) {
s += "<h2>Key "+cursor.key+"</h2><p>";
for(var field in cursor.value) {
s+= field+"="+cursor.value[field]+"<br/>";
}
s+="</p>";
cursor.continue();
}
document.querySelector("#status2").innerHTML = s;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
可以在test9.html中看到完整的代码,我们可以不断增加人员信息,然后点获取所有信息,如下图运行效果:
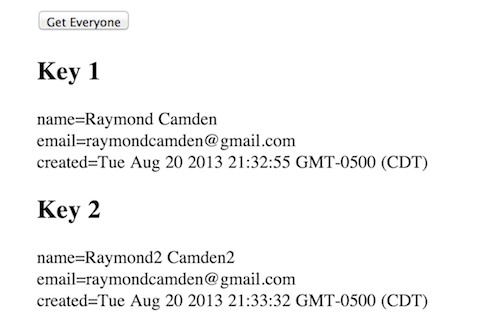
IndexedDB中的索引
在本教程的***部分,讲解IndexedDB中最重要的部分就是索引了。首先是如何创建索引,这需要在upgrade事件中进行,下面是方法:
var objectStore = thisDb.createObjectStore("people",
{ autoIncrement:true });
objectStore.createIndex("name","name", {unique:false});
objectStore.createIndex("email","email", {unique:true});
- 1.
- 2.
- 3.
- 4.
其中,在objectStore.createIndex("name","name", {unique:false});
中,***个参数就是索引的名称,第二个参数就是列。并且使用unique指定某个列是否唯一,这里只是认为email是唯一的,name是不唯一的。
那么如何使用索引呢?一旦我们在事务中获得对象存储,则可以通过索引去获得数据,一个例子如下:
var transaction = db.transaction(["people"],"readonly");
var store = transaction.objectStore("people");
var index = store.index("name");
var request = index.get(name);
- 1.
- 2.
- 3.
- 4.
- 5.
接下来,可以在onsuccess事件中进行编码处理,参考test10.html,代码如下:
request.onsuccess = function(e) {
var result = e.target.result;
if(result) {
var s = "<h2>Name "+name+"</h2><p>";
for(var field in result) {
s+= field+"="+result[field]+"<br/>";
}
document.querySelector("#status").innerHTML = s;
} else {
document.querySelector("#status").innerHTML = "<h2>No match</h2>";
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
接下来看下另外一个基于索引的Range的用法,通过Range,可以获得某个数据范围之间的数据,比如字母a到字母c之间的所有name,同时还可以设置是否包含或者不包含边界(如是否包含字母a),并且可以对范围之间的数据进行排序,来看例子:
//大于39
var oldRange = IDBKeyRange.lowerBound(39);
//大于40
var oldRange2 = IDBKeyRange.lowerBound(40,true);
//小于39
var youngRange = IDBKeyRange.upperBound(40);
//小于39
var youngRange2 = IDBKeyRange.upperBound(39,true);
//20到40之间
var okRange = IDBKeyRange.bound(20,40)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
这里使用的是一个顶层的对象名为IDBKeyRange。其中lowerBound方法指定返回的数据是大于指定的参数的,upperBound则相反,bound则返回指定范围之间的数据。下面给出一个检索的例子,其中在页面表单中可以输入搜索名称的开始和结束范围,如下:
Starting with: <input type="text" id="nameSearch" placeholder="Name"><br/>
Ending with: <input type="text" id="nameSearchEnd" placeholder="Name"><br/>
- 1.
- 2.
其事件代码为:
function getPeople(e) {
var name = document.querySelector("#nameSearch").value;
var endname = document.querySelector("#nameSearchEnd").value;
if(name == "" && endname == "") return;
var transaction = db.transaction(["people"],"readonly");
var store = transaction.objectStore("people");
var index = store.index("name");
if(name != "" && endname != "") {
range = IDBKeyRange.bound(name, endname);
} else if(name == "") {
range = IDBKeyRange.upperBound(endname);
} else {
range = IDBKeyRange.lowerBound(name);
}
var s = "";
index.openCursor(range).onsuccess = function(e) {
var cursor = e.target.result;
if(cursor) {
s += "<h2>Key "+cursor.key+"</h2><p>";
for(var field in cursor.value) {
s+= field+"="+cursor.value[field]+"<br/>";
}
s+="</p>";
cursor.continue();
}
document.querySelector("#status").innerHTML = s;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
在上面的代码中,我们首先判断用户到底在哪个文本框中输入了检索条件,然后通过条件判断组合成了range,然后将range传递给打开游标的方法index.openCursor(range)就可以了,IndexedDB则会自动检索出符合条件的记录,例子的代码在test11.html。
在接下来的第二部分的教程中,将探讨包括更新、删除和数组方面的操作,敬请期待。
本文代码下载参见:https://github.com/tutsplus/working-with-indexeddb















