了解启发式搜索领域及其在人工智能上的应用。本文作者展示了他们如何成功用 Java 实现了最广为使用的启发式搜索算法。他们的解决方案利用一个替代的 Java 集合框架,并使用最佳实践来避免过多的垃圾收集。
通过搜寻可行解决方案空间来解决问题是人工智能中一项名为状态空间搜索 的基本技术。 启发式搜索 是状态空 间搜索的一种形式,利用有关一个问题的知识来更高效地查找解决方案。启发式搜索在各个领域荣获众多殊荣。在本文中,我们将向您介绍启发式搜索领域,并展示 如何利用 Java 编程语言实现 A*,即最广为使用的启发式搜索算法。启发式搜索算法对计算资源和内存提出了较高的要求。我们还将展示如何避免昂贵的垃圾收集,以及如何利用一个替代的高 性能 Java 集合框架 (JCF),通过这些改进 Java 实现。本文的所有代码都可以从 下载 部分获得。
启发式搜索
计算机科学中的许多问题可用一个图形数据结构表示,其中图形中的路径表示潜在的解决方案。查找最优解决方案需要找到一个最短路径。例如,以自主视频游戏角色为例。角色做出的每个动作都与图形中的一个边缘相对应,而且角色的目标是找到最短路径,与对手角色交手。
深度优先 搜索和广度优先 搜索等算法是流行的图形遍历算法。但它们被视为非启发式 算法,而且常常受到它们可以解决的问题规模的严格限制。此外,不能保证深度优先搜索能找到最优解决方案(或某些情况下的任何解决方案),可以保证广度优先搜索仅能在特殊情况下找到最优解决方案。相比之下,启发式搜索是一种提示性 搜索,利用有关一个问题的知识,以启发式 方式进行编码,从而更高效地解决问题。启发式搜索可以解决非启发式算法无法解决的很多难题。
视频游戏寻路是启发式搜索的一个受欢迎的领域,它还可以解决更复杂的问题。2007 年举行的无人驾驶汽车比赛 “DARPA 城市挑战赛” 的优胜者就利用了启发式搜索来规划平坦的、直接的可行使路线。启发式搜索在自然语言处理中也有成功应用,它被用于语音识别中的文本和堆栈解码句法解析。它 在机器人学和生物信息学领域也有应用。与传统的动态编程方法相比较,使用启发式搜索可以使用更少的内存更快地解决多序列比对 (Multiple Sequence Alignment, MSA),这是一个经过深入研究的信息学问题。
通过 Java 实现启发式搜索
Java 编程语言不是实现启发式搜索的一种受欢迎的选择,因为它对内存和计算资源的要求很高。出于性能原因,C/C++ 通常是首选语言。我们将证明 Java 是实现启发式搜索的一种合适的编程语言。我们首先表明,在解决受欢迎的基准问题集时,A* 的 textbook 实现确实很缓慢,并且会耗尽可用内存。我们通过重访一些关键实现细节和利用替代的 JCF 来解决这些性能问题。
很多这方面的工作都是本文作者合著的一篇学术论文中发表的作品的一个扩展。尽管原作专注于 C/C++ 编程,但在这里,我们展示了适用于 Java 的许多同样的概念。
广度优先搜索
熟悉广度优先搜索(一个共享许多相同概念和术语的更简单的算法)的实现,将帮助您理解实现启发式搜索的细节。我们将使用广度优先搜索的一个以代理为中心 的视图。在一个以代理为中心的视图中,代理据说处于某种状态,并且可从该状态获取一组适用的操作。应用操作可将代理从其当前状态转换到一个新的后继 状态。该视图适用于多种类型的问题。
广度优先搜索的目标是设计一系列操作,将代理从其初始状态引导至一个目标状态。从初始状态开始,广度优先搜索首先访问最近生成的状态。所有适用的操作在每个访问状态都可以得到应用,生成新的状态,然后该状态被添加到未访问状态列表(也称为搜索的前沿)。访问状态并生成所有后继状态的过程被称为扩展 该状态。
您可以将该搜索过程看作是生成了一个树:树的根节点表示初始状态,子节点由边缘连接,该边缘表示用于生成它们的操作。图 1 显示该搜索树的一个图解。白圈表示搜索前沿的节点。灰圈表示已展开的节点。
图 1. 二叉树上的广度优先搜索顺序
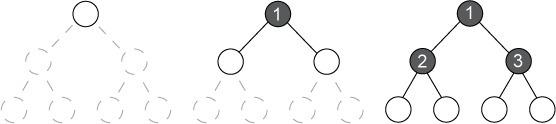
搜索树中的每一个节点表示某种状态,但两个独特的节点可表示同一状态。例如,搜索树中处于不同深度的一个节点可以与树中较高层的另一个节点具有同样的状态。这些重复 节点表示在搜索问题中达到同一状态的两种不同方式。重复节点可能存在问题,因此必须记住所有受访节点。
清单 1 显示广度优先搜索的伪代码:
清单 1. 广度优先搜索的伪代码
- function: BREADTH-FIRST-SEARCH(initial)
- open ← {initial}
- closed ← 0
- loop do:
- if EMPTY(open) then return failure
- node ← SHALLOWEST(open)
- closed ← ADD(closed, node)
- for each action in ACTIONS(node)
- successor ← APPLY(action, node)
- if successor in closed then continue
- if GOAL(successor) then return SOLUTION(node)
- open ← INSERT(open, successor)
在清单1中,我们将搜索前沿保留在一个 open 列表(第 2 行)中。将访问过的节点保留在 closed 列表(第 3 行)中。closed 列表有助于确保我们不会多次重访任何节点,从而不会重复搜索工作。仅当一个节点不在 closed 列表中时才能将其添加到前沿。搜索循环持续至 open 列表为空或找到目标为止。
在图1中,您可能已经注意到,在移至下一层之前,广度优先搜索会访问搜索树的每个深度层的所有节点。在所有操作具有相同成本的问题中,搜素树中的所有边缘具 有相同的权重,这样可保证广度优先搜索能找到最优解决方案。也就是说,生成的第一个目标在从初始状态开始的最短路径上。
在某些域中,每个操作有不同的成本。对于这些域,搜索树中的边缘具有不统一的权重。在这种情况下,一个解决方案的成本是从根到目标的路径上所有边缘 权重的总和。对于这些域,无法保证广度优先搜索能找到最优解决方案。此外,广度优先搜索必须展开树的每个深度层的所有节点,直至生成目标。存储这些深度层 所需的内存可能会快速超过最现代的计算机上的可用内存。这将广度优先搜索限制于很窄的几个小问题。
Dijkstra 的算法是广度优先搜索的一个扩展,它根据从初始状态到达节点的成本对搜索前沿上的节点进行排序(排列 open 列表)。不管操作成本是否统一(假设成本是非负值),它都确保可以找到最优解决方案。然而,它必须访问成本少于最优解决方案的所有节点,因此它被限制于解 决较少的问题。下一节将描述一个能解决大量问题的算法,该算法能大幅减少查找最优解决方案所需访问的节点数量。
#p#
A* 搜索算法
A* 算法或其变体是最广为使用的启发式搜索算法之一。可以将 A* 看作是 Dijkstra 的算法的一个扩展,它利用与一个问题有关的知识来减少查找一个解决方案所需的计算数量,同时仍然保证最优的解决方案。A* 和 Dijkstra 的算法是最佳优先 图形遍历算法的典型示例。它们是最佳优先算法,是因为他们首先访问最佳的节点,即出现在通往目标的最短路径上的那些节点,直至找到一个解决方案。对于许多问题,找到最佳解决方案至关重要,这是让 A* 这样的算法如此重要的原因。
A* 与其他图形遍历算法的不同之处在于使用了启发式估值。启发式估值是有关一个问题的一些知识( 经验法则),该知识能让您做出更好的决策。在搜索算法的上下文中,启发式估值 有具体的含义:估算从特定节点到一个目标的成本的一个函数。A* 可以利用启发式估值来决定哪些节点是最应该访问的,从而避免不必要的计算。A* 尝试避免访问图形中几乎不通向最优解决方案的节点,通常可用比非启发式算法更少的内存快速找到解决方案。
A* 确定最应该访问哪些节点的方式是为每个节点计算一个值(我们将其称为 f 值),并根据该值对 open 列表进行排序。f 值是使用另外两个值计算出来的,即节点的 g 值 和 h 值。一个节点的 g 值是从初始状态到达一个节点所需的所有操作的总成本。从节点到目标的估算成本是其 h 值。这一估算值是启发式搜索中的启发式估值。f 值最小的节点是最应该访问的节点。
图 2 展示该搜索过程:
图 2. 基于 f 值的 A* 搜索顺序
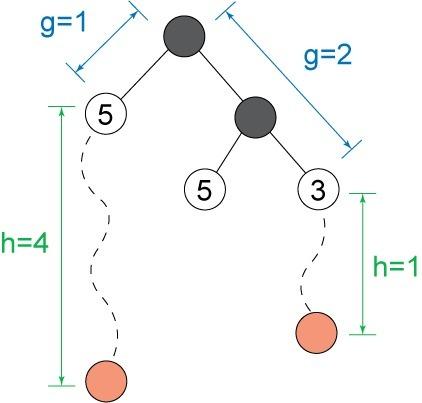
在 图 2 的示例中,前沿有三个节点。有两个节点的 f 值是 5,一个节点的 f 值是 3。接下来展开 f 值最小的节点,该节点直接通往一个目标。这样一来 A* 就无需访问其他两个节点下的任何子树,如图 3 所示。这使得 A* 比广度优先搜索等算法要高效得多。
图 3. A* 不必访问 f 值较高的节点下的子树
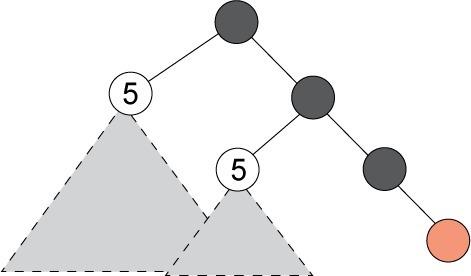
如果 A* 使用的启发式估值是可接受的,那么 A* 仅访问找到最优解决方案所需的节点。为此 A* 很受欢迎。没有其他算法能用可接受的启发式估值,通过访问比 A* 更少的节点保证找到一个最优解决方案。要让启发式估算成为可接受的,它必须是一个下限值:一个小于或等于到达目标的成本的值。如果启发满足另一个属性,即一致性,那么将首次通过最优路径生成每个状态,而且该算法可以更高效地处理重复节点。
与上一节的广度优先搜索一样,A* 维护两个数据结构。已生成但尚未访问的节点存储在一个 open 列表 中,而且访问的所有标准节点都存储在一个 closed 列表 中。这些数据结构的实现以及使用它们的方式对性能有很大的影响。我们将在后面的一节中对此进行详细探讨。清单 2 显示 textbook A* 搜索的完整伪代码。
清单 2. A* 搜索的伪代码
- function: A*-SEARCH(initial)
- open ← {initial}
- closed ← 0
- loop do:
- if EMPTY(open) then return failure
- node ← BEST(open)
- if GOAL(node) then return SOLUTION(node)
- closed ← ADD(closed, node)
- for each action in ACTIONS(node)
- successor ← APPLY(action, node)
- if successor in open or successor in closed
- IMPROVE(successor)
- else
- open ← INSERT(open, successor)
在清单 2 中,A* 从 open 列表中的初始节点入手。在每次循环迭代中,open 列表上的最佳节点被删除。接下来,open 上 最佳节点的所有适用操作被应用,生成所有可能的后继节点。对于每个后继节点,我们将通过检查确认它表示的状态是否已被访问。如果没有,则将其添加到 open 列表。如果它已经被访问,则需要通过一个更好的路径确定我们是否达到了这一状态。如果是,则需要将该节点放在 open 列表上,并删除次优的节点。
我们可以使用有关要解决的问题的两个假设简化这一段伪代码:我们假设所有操作有相同的成本,而且我们有可接受的、一致的启发式估值。因为启发式估值 是一致的,且域中的所有操作具有相同的成本,那么我们永远无法通过一个更好的路径重访一个状态。结果还表明,对于一些域,在 open 列表中放置重复节点比每次生成新节点时检查是否有重复节点更高效。因此,我们可以通过将所有新后继节点附加到 open 列表来简化实现,不管它们是否已经被访问。我们通过将 清单 2 中的最后四行组合为一行来简化伪代码。我们仍然需要避免循环,因此在展开一个节点之前,必须检查是否有重复节点。我们可以省略掉 IMPROVE 函数的细节,因为在简化版本中不再需要它。清单 3 显示简化的伪代码:
清单 3. A* 搜索的简化伪代码
- function: A*-SEARCH(initial)
- open ← {initial}
- closed ← 0
- loop do:
- if EMPTY(open) then return failure
- node ← BEST(open)
- if node in closed continue
- if GOAL(node) then return SOLUTION(node)
- closed ← ADD(closed, node)
- for each action in ACTIONS(node)
- successor ← APPLY(action, node)
- open ← INSERT(open, successor)
A* 的 Java textbook 实现
本节我们将介绍如何基于 清单 3 中简化的伪代码完成 A* 的 Java textbook 实现。您会看到,这一实现无法解决 30GB 内存限制下的一个标准启发式搜索基准。
我们希望我们的实现尽量大众化,因此我们首先定义了一些接口来提取 A* 要解决的问题。我们想通过 A* 解决的任何问题都必须实现 Domain接口。Domain 接口提供具有以下用途的方法:
- 查询初始状态
- 查询一个状态的适用操作
- 计算一个状态的启发式估值
- 生成后继状态
清单 4 显示了 Domain 接口的完整代码:
清单 4. Domain 接口的 Java 源代码
- public interface Domain<T> {
- public T initial();
- public int h(T state);
- public boolean isGoal(T state);
- public int numActions(T state);
- public int nthAction(T state, int nth);
- public Edge<T> apply (T state, int op);
- public T copy(T state);
- }
A* 搜索为搜索树生成边缘和节点对象,因此我们需要 Edge 和 Node 类。每个节点包含 4 个字段:节点表示的状态、对父节点的引用,以及节点的 g 和 h 值。清单 5 显示 Node 类的完整代码:
#p#
清单 5. Node 类的 Java 源代码
- class Node<T> {
- final int f, g, pop;
- final Node parent;
- final T state;
- private Node (T state, Node parent, int cost, int pop) {
- this.g = (parent != null) ? parent.g+cost : cost;
- this.f = g + domain.h(state);
- this.pop = pop;
- this.parent = parent;
- this.state = state;
- }
- }
每个边缘有三个字段:边缘的成本或权重、用于为边缘生成后继节点的操作,以及用于为边缘生成父节点的操作。清单 6 显示了 Edge 类的完整代码:
清单 6. Edge 类的 Java 源代码
- public class Edge<T> {
- public int cost;
- public int action;
- public int parentAction;
- public Edge(int cost, int action, int parentAction) {
- this.cost = cost;
- this.action = action;
- this.parentAction = parentAction;
- }
- }
A* 算法本身会实现 SearchAlgorithm 接口,而且仅需要 Domain 和 Edge 接口。SearchAlgorithm 接口仅提供一个方法来执行具有指定初始状态的搜索。search() 方法返回 SearchResult 的一个实例。SearchResult 类提供搜索统计。SearchAlgorithm 接口的定义如清单 7 所示:
清单 7. SearchAlgorithm 接口的 Java 源代码
- public interface SearchAlgorithm<T> {
- public SearchResult<T> search(T state);
- }
用于 open 和 closed 列表的数据结构的选择是一个重要的实现细节。我们将使用 Java 的 PriorityQueue 实现 open 列表。PriorityQueue 是一个平衡的二进制堆的实现,包含用于元素入列和出列的 O(log n) 时间、用于测试一个元素是否在队列中的线性时间,以及用于访问队列头的约束时间。二进制堆是实现 open 列表的一个流行数据结构。稍后您会看到,对于一些域,可以使用一个名为桶优先级队列 的更高效的数据结构来实现 open 列表。
我们必须实现 Comparator 接口让 PriorityQueue 合理地对节点进行排序。对于 A* 算法,我们需要根据 f 值对每个节点排序。在许多节点的 f 值相同的域中,一个简单的优化是通过选择 g 值较高的节点来打破平局。试着花点时间说服自己为何以这种方式打破平局能提高 A* 的性能(提示:h 是一个估算值;而 g 不是)。清单 8 包含完整的 Comparator 实现代码:
清单 8. NodeComparator 类的 Java 源代码
- class NodeComparator implements Comparator<Node> {
- public int compare(Node a, Node b) {
- if (a.f == b.f) {
- return b.g - a.g;
- }
- else {
- return a.f - b.f;
- }
- }
- }
我们需要实现的其他数据结构是 closed 列表。对此的一个明显的选择是 Java 的 HashMap 类。HashMap 类是散列表的一个实现,只要我们提供一个好的散列函数,预期会有用于检索和添加元素的恒定时间。我们必须重写负责实现域状态的类的 hashcode() 和 equals() 方法。我们将在下一节中探讨该实现。
最后我们需要实现 SearchAlgorithm 接口。为此,我们使用 清单 3 中的伪代码实现 search() 方法。清单 9 显示了 A* search() 方法的完整代码:
清单 9. A* search() 方法的 Java 源代码
- public SearchResult<T> search(T init) {
- Node initNode = new Node(init, null, 0, 0 -1);
- open.add(initNode);
- while (!open.isEmpty() && path.isEmpty()) {
- Node n = open.poll();
- if (closed.containsKey(n.state)) continue;
- if (domain.isGoal(n.state)) {
- for (Node p = n; p != null; p = p.parent)
- path.add(p.state);
- break;
- }
- closed.put(n.state, n);
- for (int i = 0; i < domain.numActions(n.state); i++) {
- int op = domain.nthAction(n.state, i);
- if (op == n.pop) continue;
- T successor = domain.copy(n.state);
- Edge<T> edge = domain.apply(successor, op);
- Node node = new Node(successor, n, edge.cost, edge.pop);
- open.add(node);
- }
- }
- return new SearchResult<T>(path, expanded, generated);
- }
要评估我们的 A* 实现,需要对一个问题运行该实现。在下一节中,我们将描述一个用于评估启发式搜索算法的流行域。该域中的所有操作都具有相同的成本,而且我们使用的启发式估值是可接受的,因此我们的简化实现是足够的。
15 puzzle 基准
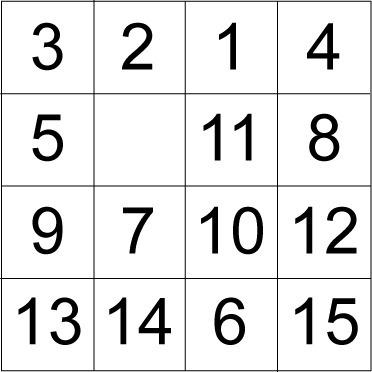
本文中,我们侧重于一个名为 15 puzzle 的 toy 域。这个简单的域有易于理解的属性,是评估启发式搜索算法的一个 标准基准。(有人将这些拼图称为 AI 研究的 “果蝇”。)15 puzzle 是一种滑块拼图,在 4×4 网格上排列 15 个滑块。一个滑块有 16 个位置可供选择,总有一个位置是空的。与空白位置相邻的滑块可从一个位置滑动 到另一个位置。其目的是滑动滑块,直至达到拼图的目标布局。图 4 显示了随机布局下的滑块拼图:
图 4. 15 puzzle 的随机布局
#p#
图 5 显示了目标布局下的滑块:
图 5. 15 puzzle 的目标布局
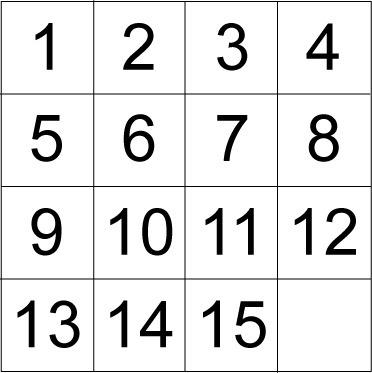
作为一个启发式搜索基准,我们希望通过尽量少的移动从某个初始布局开始找到该拼图的目标布局。
我们将为该域使用的启发式算法叫作曼哈坦距离 算法。一个滑块的曼哈坦距离是滑块到达目标位置所需做出的垂直和水平移动数量。要 计算一个状态的启发式估值,我们需要算出拼图中所有滑块的曼哈坦距离的总和,忽略空白位置。对于任何状态,所有这些距离之和必须是达到拼图目标状态所需成 本的下限值,因为您永远无法通过减少移动量将滑块移动到每个目标布局。
一开始似乎不太直观,但我们可以用图形建模 15 puzzle,将滑块的每个可能布局表示为节点。如果有一个操作将一个布局转化为另一个布局,一个边缘连接两个节点。在该域中,一个操作将滑块滑到空白区域。图 4 展示了这一搜索图:
图 6. 15 puzzle 的状态空间搜索图
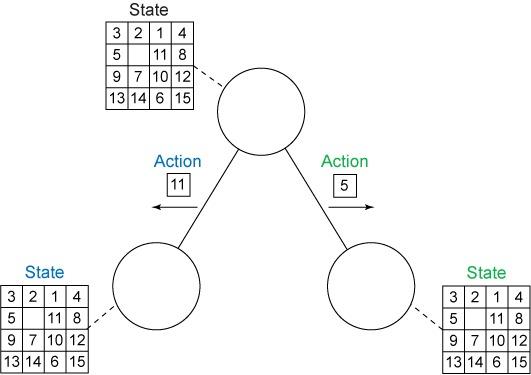
有 16! 种在网格上排列 15 个滑块的可能方式,不过实际上 “只有” 16!/2 = 10,461,394,944,000 种 15 puzzle 的可达布局或状态。这是因为拼图的物理约束让我们刚好达到所有可能布局的一半。为了了解该状态空间的大小,假设我们可以用一个字节表示一种状态(这是不可 能的)。为了存储整个状态空间,我们需要超过 10TB 的内存。这将远远超过最现代的计算机的内存限制。我们将展示启发式搜索如何在仅访问一小部分状态空间的同时以最佳方式解决这个难题。
运行实验
我们的实验使用 15 puzzle 的一组著名起始布局,叫 Korf 100 集合。这一集合得名于 Richard E. Korf,他发布了首批结果,表明可以使用 A* 的一个迭代加深 变体,即 IDA*,解决随机的 15 puzzle 布局。由于这些结果被发布,Korf 在其实验中使用的 100 个随机实例在无数随后的启发式搜索实验中得到重用。我们还优化了我们的实现,因而无需再使用迭代加深技术。
我们一次解决一个起始布局。每个起始布局都存储在一个独立的普通文本文件中。文件的位置在启动实验的命令行参数中指定。我们需要一个 Java 程序入口点来处理命令行参数,生成问题实例,并运行 A* 搜索。我们将这个入口点称为 TileSolver 类。
在每次运行结束时会将有关搜索性能的统计数据打印为标准输出。我们最感兴趣的统计数据是挂钟时间(wall clock time)。我们将所有运行的挂钟时间加起来,得出该基准测试的总运行时间。
本文 源代码 包含自动完成实验的 Ant 任务。您可以使用以下代码运行整个实验:
- ant TileSolver.korf100 -Dalgorithm="efficient"
可以为 algorithm 指定 efficient 或 textbook。
- ant TileSolver -Dinstance="12" -Dalgorithm="textbook"
而且我们提供一个 Ant 目标来运行基准测试子集,其中不包括三个最难的实例:
- ant TileSolver.korf97 -Dalgorithm="textbook"
很可能您的计算机没有足够的内存来使用 textbook 实现完成整个实验。为了避免存储交换,您应当谨慎地限制 Java 进程可用的内存量。如果您要在 Linux 上运行该实验,可以使用像 ulimit 这样的 shell 命令来设置活动 shell 的内存限制。
一开始没有成功
表 1 显示我们使用的所有技术的结果。Textbook A* 实现的结果在第一行。(在后面的章节中我们描述了 Packed states 和 HPPC 及其相关结果。)
表 1. 解决 97 个 Korf 100 15 puzzle 基准测试实例的三个 A* 变体的结果
| 算法 | 最大内存使用量 | 总运行时间 |
|---|---|---|
| Textbook | 25GB | 1,846 秒 |
| Packed states | 11GB | 1,628 秒 |
| HPPC | 7GB | 1,084 秒 |
textbook 实现无法解决所有测试实例。我们未能解决三个最难的实例,而且对于我们可以解决的实例,我们花了超过 1,800 秒的时间。这些结果不算很好,因为 C/C++ 中最好的实现可在不到 600 秒的时间内解决 100 个实例。
由于内存约束我们未能解决最难的那三个实例。在每一次搜索迭代中,从 open 列表中删除一个节点并展开它通常会导致生成更多的节点。随着所生成节点数量的增加,在 open 列表中存储它们所需的内存量也在增加。但是,这一内存需求不是 Java 实现所特有的;同等的 C/C++ 实现也会失败。
Burns 等人在其论文中表明,A* 搜索的一个高效 C/C++ 实现可以用不到 30GB 的内存解决该基准测试,因此我们还没打算放弃 Java A* 实现。我们还可以应用后续章节中讨论的其他技术,更高效地使用内存。最终得出一个能够快速解决整个基准测试的高效的 A* Java 实现。
包装状态
在使用像 VisualVM 这样的探查器检查 A* 搜索的内存使用情况时,我们看到所有内存都被 Node 类占用,更直接地说由 TileState 类占用。为了降低内存使用量,我们需要重访这些类的实现。
每个滑块状态必须存储所有 15 个滑块的位置。为此我们将每个滑块的位置存储在一个包含 15 个整数的数组中。我们可以更简明地表示这些位置,将它们包装成一个 64 位的整数(在 Java 中是 long)。当我们需要在 open 列表中存储一个节点时,可以仅存储状态的包装表示。这么做会为每个节点节省 52 个字节。要解决基准测试中最难的实例,需要存储大约 5.33 亿个节点。通过包装状态表示,我们可以节省 25GB 的内存!
为了维护我们的实现的一般性,我们需要扩展 SearchDomain 接口,使用包装和拆装状态的方法。在 open 列表上存储一个节点之前,我们将生成状态的一个包装表示,并将该包装表示存储在 Node 类(而非状态指针)中。当我们需要生成一个节点的后续节点时,只需拆装状态。清单 10 显示了 pack() 方法的实现:
#p#
清单 10. pack() 方法的 Java 源代码
- public long pack(TileState s) {
- long word = 0;
- s.tiles[s.blank] = 0;
- for (int i = 0; i < Ntiles; i++)
- word = (word << 4) | s.tiles[i];
- return word;
- }
清单 11 显示了 unpack() 方法的实现:
清单 11. unpack() 方法的 Java 源代码
- public void unpack(long packed, TileState state) {
- state.h = 0;
- state.blank = -1;
- for (int i = numTiles - 1; i >= 0; i--) {
- int t = (int) packed & 0xF;
- packed >>= 4;
- state.tiles[i] = t;
- if (t == 0)
- state.blank = i;
- else
- state.h += md[t][i];
- }
- }
由于包装表示是状态的一种规范形式,我们可以将包装表示存储在 closed 列表中。我们无法将基元存储在 HashMap 类中。需要将它们包装在Long 类的一个实例中。
表 1 中的第二行显示使用包装状态表示运行实验的结果。通过使用包装状态表示,我们将内存使用量减少了 55%,并缩短了运行时间,但我们仍然无法解决整个基准测试。
Java 集合框架的问题
如果您认为将每个包装状态表示包装在一个 Long 实例中似乎需要很大开销,那么您说得没错。它浪费内存,而且可能导致过度的垃圾收集。JDK 1.5 增加了对 autoboxing 的支持,autoboxing 会自动转换其对象表示的基元值(long 到 Long),反之亦然。对于大型集合,这些转换可能会降低内存和 CPU 性能。
JDK 1.5 还引入了 Java 泛型:一个通常相对于 C++ 模板的特性。Burns 等人表明,C++ 模板在实施启发式搜索时提供了巨大的性能优势。泛型不提供这种优势。泛型是使用 type-erasure 实现的,这会在编译时删除(消除)所有类型信息。因此,必须在运行时检查类型信息,对于大型集合来说这会导致性能问题。
HashMap 类的实现揭露出一些其他内存开销。HashMap 存储包含内部 HashMap$Entry 类实例的一个数组。每当我们将一个元素添加到 HashMap 时,都会有一个新条目被创建并添加到数组。该条目类的实现通常包含三个对象引用和一个 32 位整数的引用,每个条目总共 32 个字节。由于 closed 列表中有 5.33 亿个节点,我们将有超过 15GB 的内存开销。
接下来,我们将介绍 HashMap 类的一个替代方法,该方法支持我们通过直接存储基元进一步减少内存使用。
高性能的原生集合
由于我们现在仅在 closed 列表中存储基元,我们可以利用高性能的原生集合(High Performance Primitive Collections,HPPC)。HPPC 是一个替代的集合框架,支持您直接存储基元值,而没有 JCF 带来的所有那些开销。与 Java 泛型相比,HPPC 使用了一种类似 C++ 模板的技术,在编译时生成每个集合类和 Java 基元类型的独立实现。这样一来,在将基元值存储到一个集合中时就无需使用 Long 和Integer 这样的类包装基元值。其另外一个作用是可以避免对于 JCF 来说必需的大量强制转换。
另外还有用于存储基元值的其他 JCF 替代方法。Apache Commons Primitive Collections 和 fastutils 就是两个不错的示例。不过,我们认为 HPPC 的设计在实现高性能算法时有一个显著的优势:它为每个集合类公开内部数据存储。直接访问这一存储可以实现许多优化。例如,如果我们想将 open 或 closed 列表存储在磁盘上,直接访问底层数据数组比通过一个迭代器间接访问数据更有效。
我们可以修改 A* 实现,对 closed 列表使用 LongOpenHashSet 类的一个实例。我们需要做的更改相当简单。我们不再需要重写 state class 的hashcode 和 equals 方法,因为我们仅需存储基元值。closed 列表是一个集合(它不包含重复元素),因此我们仅需要存储值,而无需存储键/值对。
表 1 中的第三行显示了用 HPPC 取代 JCF 后运行实验的结果。凭借 HPPC,我们将内存使用量减少了 27%,将运行时间减少了 33%。
既然内存总共减少了 82%,我们就可以在内存约束内解决整个基准测试了。结果显示于表 2 中的第一行:
表 2. 解决全部 100 个 Korf 100 基准测试实例的三个 A* 变体的结果
| 算法 | 最大内存使用量 | 总运行时间 |
|---|---|---|
| HPPC | 30GB | 1,892 秒 |
| 嵌套桶队列 | 30GB | 1,090 sec |
| 避免垃圾收集 | 30GB | 925 秒 |
通过 HPPC,我们可以用 30GB 内存解决全部 100 个实例,但所用时间超过 1,800 秒。表 2 中的其他结果反映了我们通过改进其他重要数据结构加速实现的方式:open 列表。
PriorityQueue 的问题
每次我们将一个元素添加到 open 列表时,都需要再次排队。PriorityQueue 有 O(log(n)) 入列和出列操作时间。涉及到排序时,PriorityQueue 是高效的,但显然是不自由的,特别在 n 值较大时。记得对于最难的问题实例,我们添加了超过 5 亿个节点到 open 列表。此外,由于我们的基准测试问题中的所有操作都具有相同的成本,可能的 f 值的范围较小。因此使用 PriorityQueue 的优势与开销相比可能得不偿失。
另一个替代方法是使用基于桶的优先级队列。假设我们域中的操作成本在一个狭窄的值域内,我们可以定义一个固定的存储桶范围:每个 f 值一个存储桶。当我们生成一个节点时,只需将它放在与 f 值对应的存储桶中。当我们需要访问队列头时,可以首先从 f 值最小的存储桶看起,直至我们找到一个节点。这种数据结构叫作 1 级桶优先级队列,它支持恒定入列和出列操作。图 7 展示了这一数据结构:
图 7. 1 级桶优先级队列
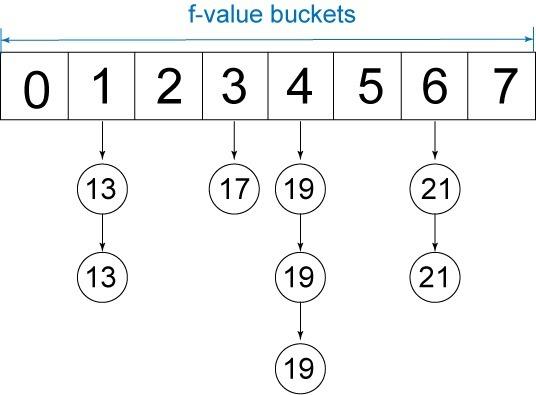
精明的读者会注意到,如果我们实现这里描述的 1 级桶优先级队列,就失去了使用 g 值打破节点间关系的能力。您之前应当已经意识到,以这种方式打破关系是一种值得的优化。为了维持这一优化,我们可以实现一个嵌套 桶优先级队列。1 级存储桶用于表示 f 值的范围,嵌套级别用于表示 g 值的范围。图 8 展示了这一数据结构:
图 8. 嵌套桶优先级队列
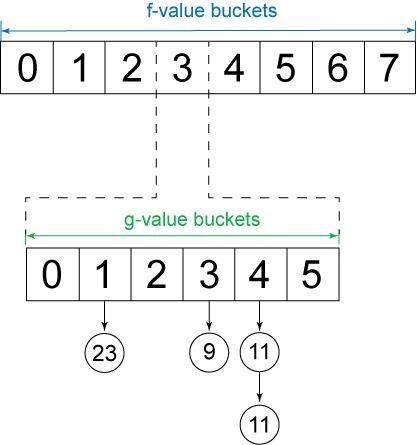
现在我们可以更新我们的 A* 实现,为 open 列表使用一个嵌套桶优先级队列。嵌套桶优先级队列的完整实现可在本文源代码中包含的 BucketHeap.java 文件中找到(参见 下载 部分)。
表 2 的第二行显示使用嵌套桶优先级队列运行实验的结果。通过使用一个嵌套桶优先级队列,而非 PriorityQueue,我们将运行时间缩短了将近 58%,所用时间是 1,000 多秒。我们可以再做一件事来缩短运行时间。
#p#
避免垃圾收集
垃圾收集常被视为 Java 中的一个瓶颈。有许多关于 JVM 中垃圾收集调优的优秀文章可应用于这里,因此我们不会详细讨论该主题。
A* 通常生成许多短暂的状态和边缘对象并招致大量昂贵的垃圾收集。通过重用对象,我们可以减少所需的垃圾收集量。为此我们可以做一些简单的更改。在 A* 搜索循环的每一次迭代中,我们分配一个新边缘和一个新状态(对于最难的问题是 5.33 亿个节点)。与其每次分配新对象,我们可以在所有循环迭代中重用相同的状态和边缘对象。
为了拥有可重用的边缘和状态对象,我们需要修改 Domain 接口。 与其让 apply() 方法返回 Edge 的一个实例,我们需要提供自己的实例,该实例通过调用 apply() 加以修改。对 edge 的更改不是递增的,因此在将其传递给 apply() 之前,我们无需担心哪些值存储在 edge 中。不过,apply() 对 state 对象所做的更改是 递增的。为了合理生成所有可能的后继状态,而无需复制状态,我们需要一种撤销所做更改的方式。为此,我们必须扩展 Domain 接口,得到一个 undo() 方法。清单 12 显示 Domain 接口更改:
清单 12. 更新的 Domain 接口
- public interface Domain<T> {
- ...
- public void apply(T state, Edge<T> edge, int op);
- public void undo(T state, Edge<T> edge);
- ...
- }
表 2 中的第三行显示最终实验的结果。通过循环利用我们的状态和边缘对象,我们可以避免昂贵的垃圾收集,并将运行时间缩短超过 15%。利用我们高效的 A* Java 实现,我们现在可以仅用 30GB 的内存在 925 秒内解决整个基准测试。鉴于最好的 C/C++ 实现需要 27GB 内存且花费 540 秒,这个结果已经很好了。我们的 Java 实现仅比 C/C++ 实现慢 1.7 倍,且需要大约同样的内存量。
结束语
在本文中,我们向您介绍了启发式搜索。我们提出了 A* 算法,并阐述了 Java textbook 实现。我们指出该实现存在性能问题,无法在合理的时间或内存约束内解决一个标准的基准测试问题。我们利用 HPPC 和一些可降低内存使用和避免昂贵的垃圾收集的技术解决了这些问题。我们改进的实现能够在适当的时间和内存约束内解决基准测试,这证明了 Java 是实现启发式搜索算法的一个不错选择。此外,我们在本文提供的技术也可应用于许多实际 Java 应用程序。例如,在某些情况下,使用 HPPC 可以立即提高存储大量基元值的任何 Java 应用程序的性能。
下载
| 描述 | 名字 | 大小 |
|---|---|---|
| 样例代码 | j-ai-code.zip | 58KB |
原文链接:http://www.ibm.com/developerworks/cn/java/j-ai-search/index.html