有人说“大数据不是Hadoop;Hadoop也不代表大数据”,不知说的人什么目的,但在我看来,如今业内对大数据认知尚不深刻的情况下,过多纠缠于概念无助于大数据应用。在我看来,如果强调“Hadoop就是大数据”利多弊少。
有关大数据,“奥巴马连任总统和大数据、2009年谷歌在甲型H1N1流感爆发前几周成功预测,公共卫生部门震惊、美国折扣店零售商塔吉特与怀孕预测、UPS快递最佳行车路线和汽车修理预测、亚马逊大数据书评推荐下调战胜专家团……”这样几个案例耳熟能详,管中窥豹,我们可以大数据应用的价值,但我们的盲点在于不知道它们是如何做的,大数据应用是如何实现的。
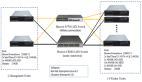
从这个意义上说,了解Hadoop就非常有意义。它可以帮助我们了解什么是大数据,以及如何进行大数据的应用。Hadoop,分布式数据库,仅从字面上还是很难了解其作用和价值。对此不妨看一个简单的实例,看看搜索引擎是如何进行大数据应用的。首先,搜索引擎通过网络爬虫自动获取网页内容,按照一定算法对内容建立索引,这些索引和原始的数据用Hadoop存储起来,并根据规则制作副本(通常是3副本)。当用户发起检索需求,搜索引擎就将Map为多个并行操作,对Hadoop数据库中的索引进行检索,其结果经过Reduce,聚合为一个结果,提交给发起请求的终端。这就是搜索引擎大致一个工作过程。
我们很少把搜索引擎称为大数据应用,但它确实是一个典型的大数据应用。其中的关键在于应用Hadoop,用相对廉价的X86服务器,对海量低价值密度的非结构化数据进行存储和处理。 从横向扩展性来看,其存储和处理能力接近无限,只需要不断添加服务器就可以了。至于存储,可以依赖服务器自带的磁盘,也可以理解用磁盘阵列。从Hadoop的角度,采用多副本的策略,数据可靠性已经有所保证,如此也大大降低了对RAID、快照、复制/备份技术的依赖和要求,进一步降低了成本。
所以,把大数据理解Hadoop没有什么不好,至少我们知道了分布式组织和存储数据、多副本、NFS、Map/Reduce,这很好,至少我们不会为BI、ETL与大数据应用的关系而纠结,两者各有适合应用的场景,虽有交叉,但更多是相互补充。
应该承认,没有Hadoop+X86服务器这种廉价的手段,就不会有大数据应用。正是因为有了这种廉价的手段,我们才能够对海量的非结构化数据的全局进行分析。而在著名的《大数据时代》一书中,特别强到“不是随机抽样,而是全体数据”,这是大数据应用的核心特征,对全体数据进行分析的结果,会让我们迅速了解事情的结果。至于所采用的手段,叫不叫Hadoop、NFS、Map/Reduce,这并不知道,但核心思路和思想一定会延续,从这个意义上,将Hadoop称为大数据应用又有什么不可以呢?!至少我是这么看的。