近日,LinkedIn开源了一项技术——Samza,它是一个分布式流处理框架,专用于实时数据的处理,非常像Twitter的流处理系统Storm。不同的是Samza基于Hadoop,而且使用了LinkedIn自家的Kafka分布式消息系统。
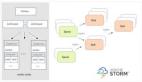
Storm和Samza极其相似,就像LinkedIn的Chris Riccomini在博客中阐述的那样:“[Samza]可以帮助你构建应用,处理消息队列——更新数据库、计数以及其他的聚合、转换消息等等。”而这些其实都是很经典的Storm应用,只不过迁移到Samza之上了,Samza文档也对比了这两个系统。
上个月,Samza在各种论坛和社区上被广泛传播,其中有评论指出了Samza可能带来的好处:
“跟很多人一样,我们使用Storm来处理基于Kafka的流数据,然后,再将这些数据发送到Hadoop上进行离线分析。如果能把这三个环境整合到一起,就是一个很大的胜利。“
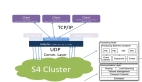
表面上看,这似乎是一个很不错的想法。Apache软件基金会的项目主页,介绍了搭配使用Kafka和YARN的特点和优势。
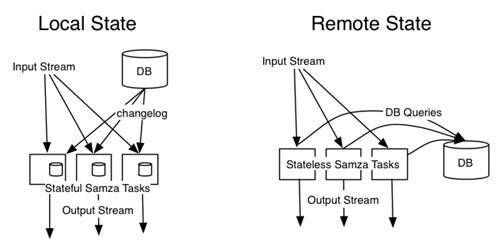
高容错: 如果服务器或者处理器出现故障,Samza将与YARN一起重新启动流处理器。
高可靠性:Samza使用Kafka来保证所有消息都会按照写入分区的顺序进行处理,绝对不会丢失任何消息。
可扩展性:Samza在各个等级进行分割和分布;Kafka提供一个有序、可分割、可重部署、高容错的系统;YARN提供了一个分布式环境供Samza容器来运行。
Samza的未来
至于Samza能不能像Storm一样吸引大量的用户和社区参与创新,还有待观察。但是LinkedIn肯定会像Twitter开发Storm一样来保证Samza的发展,而且后者在可用性上更具优势,毕竟运行在YARN或者Mesos框架上的Samza多了一些灵活性。
如果Samza未来有一个很好的前景,那么YARN也对得起Hadoop社区在过去18月的“炒作”,它不仅可以运行Storm,还可以运行Samza,甚至还可以运行其他很多的东西。这点很重要,毕竟很多软件厂商都把大数据的“期货”(甚至整个未来)压在了Hadoop上,他们希望这个平台能成为最后的赢家。
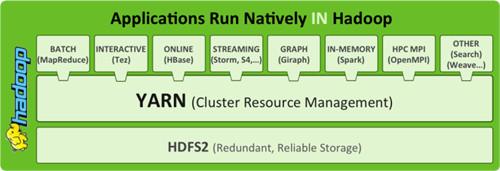
以往对MapReduce技术的依赖限制了Hadoop的适用性,但是YARN已经开放了对大规模的流处理、交互式SQL查询、机器学习和图像处理负载的支持。随着技术的日新月异,Hadoop成为支撑所有大数据应用库的想法变得更加现实。