












此处已是系列博文的第二篇,你最好从头开始看吧。
这篇文章会讲解 Visual C++ 编译器的数据流——首先会以一段C++源程序开始,以对应的二进制程序结束。这篇文章很简单——一切才刚刚开始。
首先我们来看看从命令行开始,编译一个单一文件的程序 APP.cpp 时会发生什么(如果你想从Vistual Studio 来启动编译,下图还必须包含一些高层软件,然而,结束时,它们会给出一些很特别的命令,我后面会讲到)。
假设我们刚才键入了: CL/02 App.cpp
CL代表‘编译和链接’,02告诉编译器优化速度—-生成一些执行速度尽可能快的机器码。该命令启动一个进程去运行CL.EXE程序—- 一个调用了其他软件的驱动器:连接到一起时,他们会处理APP.cpp里的文本,最终生产一个二进制文件,成为App.exe。 执行时,该二进制文件会执行我们源代码里的操作。
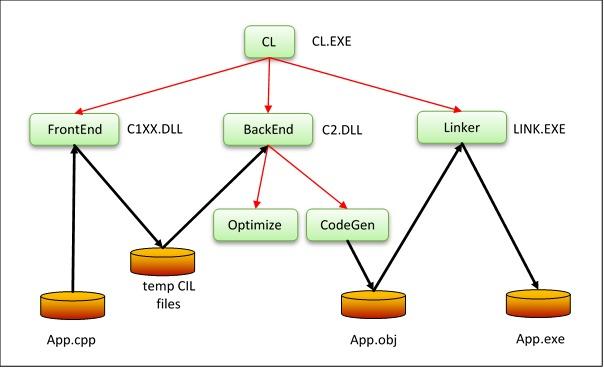
我们浏览下上个图表,看看发生了什么。
CL.EXE 解析我们的命令行,并检查它是否有意义。然后调用位于C1XX.DLL的 C++‘前端’(“CXX”是指C++,因为以前‘+’不能用于文件名。)前端是用于理解C++语言的一条链。它扫描,解析并将APP.cpp文件转换为 一颗等价树,通过五个临时文件传递给下一个组件。这五个文件被称为CIL,意为C中间语言。不要把它跟托管语言,例如C#生产的中间代码混淆。有时,也成 为MSIL,但是不幸的是,在ECMA-335标准里,它被命名为CIL。
接下来,CL.EXE会调用 所谓的‘后端’,位于C2.DLL。我们把后端成为‘UTC’,意思为‘通用元组编译器’,但是这个名字并没有出现在Visual Studio所包含的的任何二进制文件里。后端先将信息从前端转换为元组—–一个二进制流的指令。显示出来会看到它们看上去就像是一种高级汇编语言。感觉 上很高级:
- 操作是通用的,例如,一个分支(LE)指令,以及它最终如何被翻译成64位的机器码CMP指令。
- 操作数是象征性的,例如,一个由编译器生成的临时变量t66和一个运行时保存其值得64位寄存器eax。
因为我们要求编译器优化速度,通过/02开关,优化部分后端,分析元组并将其转化为另一种形式,使其运行得更快,但是语义上来讲,却是等价的,和原来的元组产生的同样的结果。完成这步后,元组就会被传给后端的CodeGen部分,最终会决定二进制码的产生。
CodeGen模块会在磁盘上生成APP.obj文件,最后,链接器会利用该文件,并分析所有的引用库,生成最终的二进制文件App.exe。
在上面的图表中,黑色箭头显示数据流(文本或者二进制文件),红色箭头表示控制流。
(在该系列的后面文章里,当我们涉及到整个程序的优化,关于特定的/GL开关编译器和/LTCG开关的链接器时,还会再回到这个图表。 我们看到的是相同的框图,但是却以不同方式连接起来的。)
小结:
1. 前端需要理解C++源代码,其他环节,像后端和链接器,大部分都是独立于原始源语言的。他们工作在上面提到的元组上,形成一种更高层次的二进制汇编语言。原始的源程序可以是任何的命令式语言,像FORTRAN或者Pascal。后端真的不会在意。
2. 后端的优化部分会将元组转换成运行更快的更有效的形式,这种转换,我们称之为优化。(其实我们应该称之为’改进’,因为还有其他的改进,可以产生运行更快 的代码——我们只是尽力接近理想状态。 然而,几十年前,有人创造了一个术语’优化’,我们都深陷其中。) 还有很多这样的优化方法,像’常量合并’、’消除公共子表达式’、 ‘提升’、 ‘外提不变表达式’、‘冗余代码消除’、’ 内联函数’、 ‘自动向量化’等等.。大多数情况下。这些优化都是独立于程序所运行的最终处理器—–他们都是独立于机器的优化。
3. 后端的CodeGen部分决定如何制定运行时堆栈(用于实现’激活框架’);怎么样充分利用可用的机器寄存器;添加函数调用约定的细节;使用目标机器的详细介绍来转换代码,让它运行得更快。
(举一个小例子,如果你看汇编代码,例如,你在调试代码的时候,同时使用Visual Studio(Alt+8)的反汇编窗口—- 你可能会注意到一些用于将EAX置为0的指令像 xor eax, eax ,优于一些更直接的指令 move eax,0. 为什么呢?因为XOR 指令更小(只有2个字节),执行速度更快。我们也称它为“微优化”,也许你会怀疑是否值得这么麻烦?还记得那句谚语吗?积少才能成多。)
与优化相比,CodeGen就必须很清楚代码将要运行的处理器架构。有些情况下,在理解目标处理器的基础上,它甚至会改变机器指令的布局顺序—–称 之为‘调度’。我最好还是再解释一下: CodeGen知道它是针对x86,x64还是ARM-32, 知道代码将要运行的处理器的具体的微架构还是很罕见的,以 Nehalem和Sandy Bridge为例(看看/favor:ATOM 这个案例,可以更多的详情)
这篇文章重点讲编译器的优化部分,很少提及构成前端, CodeGen或者链接器的其他组件。
这篇文章介绍了大量的术语,我没有打算让你全部理解它们:毕竟这只是一篇概述,传播一些思想,希望你会感兴趣,确保读完你下次还会再来,我会开始讲解所有的术语。
下次,我们一起来看看最简单的一种优化方法和它的工作原理——–合并常量。
原文链接:http://blogs.msdn.com/b/vcblog/archive/2013/06/12/optimizing-c-code-new-title.aspx














