一、Storm基本概念
在运行一个Storm任务之前,需要了解一些概念:
- Topologies
- Streams
- Spouts
- Bolts
- Stream groupings
- Reliability
- Tasks
- Workers
- Configuration
Storm集群和Hadoop集群表面上看很类似。但是Hadoop上运行的是MapReduce jobs,而在Storm上运行的是拓扑(topology),这两者之间是非常不一样的。一个关键的区别是: 一个MapReduce job最终会结束, 而一个topology永远会运行(除非你手动kill掉)。
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个叫Nimbus后台程序,它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分发代码,分配计算任务给机器, 并且监控状态。
每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程组成。
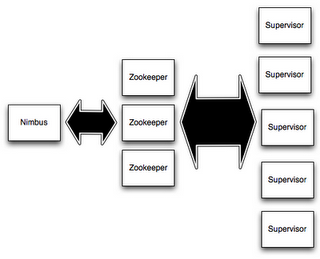
Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成。另外,Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有的状态要么在zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,就好像什么都没有发生过。这个设计使得Storm异常的稳定。
1、Topologies
一个topology是spouts和bolts组成的图, 通过stream groupings将图中的spouts和bolts连接起来,如下图:
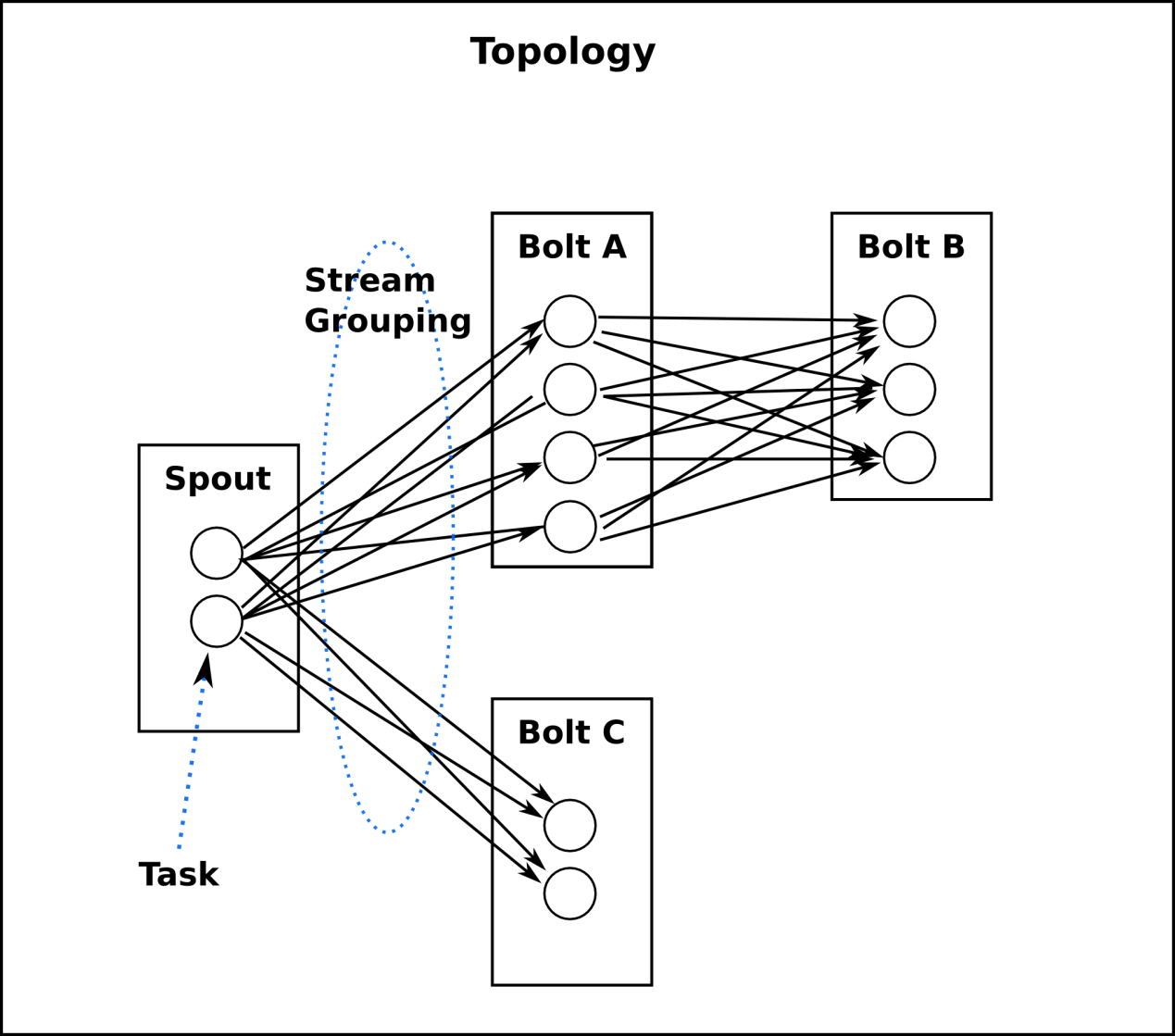
一个topology会一直运行直到你手动kill掉,Storm自动重新分配执行失败的任务, 并且Storm可以保证你不会有数据丢失(如果开启了高可靠性的话)。如果一些机器意外停机它上面的所有任务会被转移到其他机器上。
运行一个topology很简单。首先,把你所有的代码以及所依赖的jar打进一个jar包。然后运行类似下面的这个命令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2
这个命令会运行主类: backtype.strom.MyTopology, 参数是arg1, arg2。这个类的main函数定义这个topology并且把它提交给Nimbus。storm jar负责连接到Nimbus并且上传jar包。
Topology的定义是一个Thrift结构,并且Nimbus就是一个Thrift服务, 你可以提交由任何语言创建的topology。上面的方面是用JVM-based语言提交的最简单的方法。
2、Streams
消息流stream是storm里的关键抽象。一个消息流是一个没有边界的tuple序列, 而这些tuple序列会以一种分布式的方式并行地创建和处理。通过对stream中tuple序列中每个字段命名来定义stream。在默认的情况下,tuple的字段类型可以是:integer,long,short, byte,string,double,float,boolean和byte array。你也可以自定义类型(只要实现相应的序列化器)。
每个消息流在定义的时候会被分配给一个id,因为单向消息流使用的相当普遍, OutputFieldsDeclarer定义了一些方法让你可以定义一个stream而不用指定这个id。在这种情况下这个stream会分配个值为‘default’默认的id 。
Storm提供的最基本的处理stream的原语是spout和bolt。你可以实现spout和bolt提供的接口来处理你的业务逻辑。
3、Spouts
消息源spout是Storm里面一个topology里面的消息生产者。一般来说消息源会从一个外部源读取数据并且向topology里面发出消息:tuple。Spout可以是可靠的也可以是不可靠的。如果这个tuple没有被storm成功处理,可靠的消息源spouts可以重新发射一个tuple, 但是不可靠的消息源spouts一旦发出一个tuple就不能重发了。
消息源可以发射多条消息流stream。使用OutputFieldsDeclarer.declareStream来定义多个stream,然后使用SpoutOutputCollector来发射指定的stream。
Spout类里面最重要的方法是nextTuple。要么发射一个新的tuple到topology里面或者简单的返回如果已经没有新的tuple。要注意的是nextTuple方法不能阻塞,因为storm在同一个线程上面调用所有消息源spout的方法。
另外两个比较重要的spout方法是ack和fail。storm在检测到一个tuple被整个topology成功处理的时候调用ack,否则调用fail。storm只对可靠的spout调用ack和fail。
4、Bolts
所有的消息处理逻辑被封装在bolts里面。Bolts可以做很多事情:过滤,聚合,查询数据库等等。
Bolts可以简单的做消息流的传递。复杂的消息流处理往往需要很多步骤,从而也就需要经过很多bolts。比如算出一堆图片里面被转发最多的图片就至少需要两步:***步算出每个图片的转发数量。第二步找出转发最多的前10个图片。(如果要把这个过程做得更具有扩展性那么可能需要更多的步骤)。
Bolts可以发射多条消息流, 使用OutputFieldsDeclarer.declareStream定义stream,使用OutputCollector.emit来选择要发射的stream。
Bolts的主要方法是execute, 它以一个tuple作为输入,bolts使用OutputCollector来发射tuple,bolts必须要为它处理的每一个tuple调用OutputCollector的ack方法,以通知Storm这个tuple被处理完成了,从而通知这个tuple的发射者spouts。 一般的流程是: bolts处理一个输入tuple, 发射0个或者多个tuple, 然后调用ack通知storm自己已经处理过这个tuple了。storm提供了一个IBasicBolt会自动调用ack。
5、Stream groupings
定义一个topology的其中一步是定义每个bolt接收什么样的流作为输入。stream grouping就是用来定义一个stream应该如果分配数据给bolts上面的多个tasks。
Storm里面有7种类型的stream grouping
- Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
- Fields Grouping:按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts里的一个task, 而不同的userid则会被分配到不同的bolts里的task。
- All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
- Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值***的那个task。
- Non Grouping:不分组,这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
- Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
6、Reliability
Storm保证每个tuple会被topology完整的执行。Storm会追踪由每个spout tuple所产生的tuple树(一个bolt处理一个tuple之后可能会发射别的tuple从而形成树状结构),并且跟踪这棵tuple树什么时候成功处理完。每个topology都有一个消息超时的设置,如果storm在这个超时的时间内检测不到某个tuple树到底有没有执行成功, 那么topology会把这个tuple标记为执行失败,并且过一会儿重新发射这个tuple。
为了利用Storm的可靠性特性,在你发出一个新的tuple以及你完成处理一个tuple的时候你必须要通知storm。这一切是由OutputCollector来完成的。通过emit方法来通知一个新的tuple产生了,通过ack方法通知一个tuple处理完成了。
Storm的可靠性我们在第四章会深入介绍。
7、Tasks
每一个spout和bolt会被当作很多task在整个集群里执行。每一个executor对应到一个线程,在这个线程上运行多个task,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。你可以调用TopologyBuilder类的setSpout和setBolt来设置并行度(也就是有多少个task)。
8、Workers
一个topology可能会在一个或者多个worker(工作进程)里面执行,每个worker是一个物理JVM并且执行整个topology的一部分。比如,对于并行度是300的topology来说,如果我们使用50个工作进程来执行,那么每个工作进程会处理其中的6个tasks。Storm会尽量均匀的工作分配给所有的worker。
9、Configuration
Storm里面有一堆参数可以配置来调整Nimbus, Supervisor以及正在运行的topology的行为,一些配置是系统级别的,一些配置是topology级别的。default.yaml里面有所有的默认配置。你可以通过定义个storm.yaml在你的classpath里来覆盖这些默认配置。并且你也可以在代码里面设置一些topology相关的配置信息(使用StormSubmitter)。
#p#
二、构建Topology
1. 实现的目标:
我们将设计一个topology,来实现对一个句子里面的单词出现的频率进行统计。这是一个简单的例子,目的是让大家对于topology快速上手,有一个初步的理解。
2. 设计Topology结构:
在开始开发Storm项目的***步,就是要设计topology。确定好你的数据处理逻辑,我们今天将的这个简单的例子,topology也非常简单。整个topology如下:

整个topology分为三个部分:
- KestrelSpout:数据源,负责发送sentence
- Splitsentence:负责将sentence切分
- Wordcount:负责对单词的频率进行累加
3. 设计数据流
这个topology从kestrel queue读取句子,并把句子划分成单词,然后汇总每个单词出现的次数,一个tuple负责读取句子,每一个tuple分别对应计算每一个单词出现的次数,大概样子如下所示:
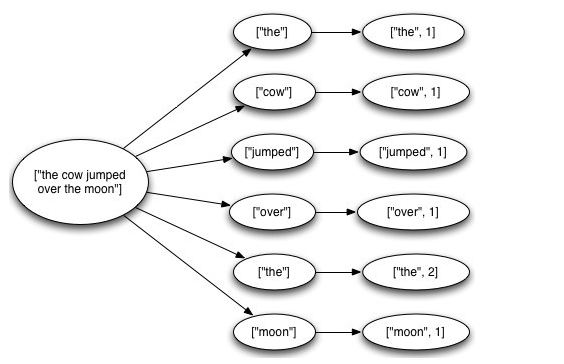
4. 代码实现:
1) 构建maven环境:
为了开发storm topology, 你需要把storm相关的jar包添加到classpath里面去: 要么手动添加所有相关的jar包, 要么使用maven来管理所有的依赖。storm的jar包发布在Clojars(一个maven库), 如果你使用maven的话,把下面的配置添加在你项目的pom.xml里面。
<repository>
<id>clojars.org</id>
<url>http://clojars.org/repo</url>
</repository>
<dependency>
<groupId>storm</groupId>
<artifactId>storm</artifactId>
<version>0.5.3</version>
<scope>test</scope>
</dependency>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
2) 定义topology:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(1, new KestrelSpout(“kestrel.backtype.com”,22133, ”sentence_queue”, new StringScheme()));
builder.setBolt(2, new SplitSentence(), 10)
.shuffleGrouping(1);
builder.setBolt(3, new WordCount(), 20)
.fieldsGrouping(2, new Fields(“word”));
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
这种topology的spout从句子队列中读取句子,在kestrel.backtype.com位于一个Kestrel的服务器端口22133。
Spout用setSpout方法插入一个独特的id到topology。 Topology中的每个节点必须给予一个id,id是由其他bolts用于订阅该节点的输出流。 KestrelSpout在topology中id为1。
setBolt是用于在Topology中插入bolts。 在topology中定义的***个bolts 是切割句子的bolts。 这个bolts 将句子流转成成单词流。
让我们看看SplitSentence实施:
public class SplitSentence implements IBasicBolt{
public void prepare(Map conf, TopologyContext context) {
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(“ ”)) {
collector.emit(new Values(word));
}
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields(“word”));
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
关键的方法是 execute方法。 正如你可以看到,它将句子拆分成单词,并发出每个单词作为一个新的元组。 另一个重要的方法是declareOutputFields,其中宣布bolts输出元组的架构。 在这里宣布,它发出一个域为word的元组。
setBolt的***一个参数是你想为bolts的并行量。 SplitSentence bolts 是10个并发,这将导致在storm集群中有十个线程并行执行。 你所要做的的是增加bolts的并行量在遇到topology的瓶颈时。
setBolt方法返回一个对象,用来定义bolts的输入。 例如,SplitSentence螺栓订阅组件“1”使用随机分组的输出流。 “1”是指已经定义KestrelSpout。 我将解释在某一时刻的随机分组的一部分。 到目前为止,最要紧的是,SplitSentence bolts会消耗KestrelSpout发出的每一个元组。
下面在让我们看看wordcount的实现:
public class WordCount implements IBasicBolt {
private Map<String, Integer> _counts = new HashMap<String, Integer>();
public void prepare(Map conf, TopologyContext context) {
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
int count;
if(_counts.containsKey(word)) {
count = _counts.get(word);
} else {
count = 0;
}
count++;
_counts.put(word, count);
collector.emit(new Values(word, count));
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields(“word”, “count”));
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
SplitSentence对于句子里面的每个单词发射一个新的tuple, WordCount在内存里面维护一个单词->次数的mapping, WordCount每收到一个单词, 它就更新内存里面的统计状态。
5. 运行Topology
storm的运行有两种模式: 本地模式和分布式模式.
1) 本地模式:
storm用一个进程里面的线程来模拟所有的spout和bolt. 本地模式对开发和测试来说比较有用。 你运行storm-starter里面的topology的时候它们就是以本地模式运行的, 你可以看到topology里面的每一个组件在发射什么消息。
2) 分布式模式:
storm由一堆机器组成。当你提交topology给master的时候, 你同时也把topology的代码提交了。master负责分发你的代码并且负责给你的topolgoy分配工作进程。如果一个工作进程挂掉了, master节点会把认为重新分配到其它节点。
3) 下面是以本地模式运行的代码:
Config conf = new Config();
conf.setDebug(true);
conf.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(“test”, conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology(“test”);
cluster.shutdown();
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
首先, 这个代码定义通过定义一个LocalCluster对象来定义一个进程内的集群。提交topology给这个虚拟的集群和提交topology给分布式集群是一样的。通过调用submitTopology方法来提交topology, 它接受三个参数:要运行的topology的名字,一个配置对象以及要运行的topology本身。
topology的名字是用来唯一区别一个topology的,这样你然后可以用这个名字来杀死这个topology的。前面已经说过了, 你必须显式的杀掉一个topology, 否则它会一直运行。
Conf对象可以配置很多东西, 下面两个是最常见的:
TOPOLOGY_WORKERS(setNumWorkers) 定义你希望集群分配多少个工作进程给你来执行这个topology. topology里面的每个组件会被需要线程来执行。每个组件到底用多少个线程是通过setBolt和setSpout来指定的。这些线程都运行在工作进程里面. 每一个工作进程包含一些节点的一些工作线程。比如, 如果你指定300个线程,60个进程, 那么每个工作进程里面要执行6个线程, 而这6个线程可能属于不同的组件(Spout, Bolt)。你可以通过调整每个组件的并行度以及这些线程所在的进程数量来调整topology的性能。
TOPOLOGY_DEBUG(setDebug), 当它被设置成true的话, storm会记录下每个组件所发射的每条消息。这在本地环境调试topology很有用, 但是在线上这么做的话会影响性能的。
结论:
本章从storm的基本对象的定义,到广泛的介绍了storm的开发环境,从一个简单的例子讲解了topology的构建和定义。希望大家可以从本章的内容对storm有一个基本的理解和概念,并且已经可以构建一个简单的topology!!