












记得刚做javaweb开发的时候被这个编码问题搞得晕头转向,经常稀里糊涂的编码正常了一会编码又乱了。那个时候迫于项目进度大多都是知其然不知其所以然。后来有时间就把整个体系搞了个遍,终于摸通了来龙去脉。
在C++的CGI开发时大家喜欢用latin,这个属于字节方式的编码格式,存储mysql节约空间,而C++也是比较容易控制到byte级别的语言。所以经过框架封装基本也问题不大。
在Java语言中,要涉及修改编码问题的地方还真多。一个地方没有设好就会乱码满天飞。大概总结包括以下这几部分:浏览器、服务器、数据库、操作系统。
浏览器:
如果使用模板语言,html需要设置显示的字符集。这个适用于浏览器判断什么编码显示。
- <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
扩展,浏览器识别编码的顺序:
1.如果HTTP头部申明了charset,则会使用HTTP头部的,
2.让HTTP头部没有设置,则会去解析meta标签的,
3.如果meta也没有的话,浏览器会根据是否设置了auto detect来进行编码识别,
4.否则会使用本地UI的字符编码。
服务器:
对于JSP等动态语言,需要在jsp头部设置编码格式,J2EE服务器解析这个JSP的时候才会把整个页面编码为UTF-8输出,不然就按照系统默认编码格式ISO-8859-1输出了。JSP设置格式如下:
- <%@ page language= "java" contentType = "text/html; charset=UTF-8"
- pageEncoding ="UTF-8" %>
大家都知道,JSP对应的就是servlet。servlet的编码对应如下设置:
- public void service(HttpServletRequest request, HttpServletResponse response)
- throws ServletException,IOException{
- response.setContentType("text/html;charset=utf-8");
- }
还有不要漏掉大家常用的spring工具类,编码转换filter,很实用。在你用struts、spring mvc时这个过滤器帮你转换没有设置的编码过滤。如下设置:
- <filter>
- <filter-name> Set Character Encoding</filter-name>
- <filter-class>
- org.springframework.web.filter.CharacterEncodingFilter
- </filter-class>
- <init-param>
- <param-name> encoding</param-name>
- <param-value> UTF-8</param-value>
- </init-param>
- </filter>
万一还有乱码怎么办呢?doGet方式的参数传递肯定会有乱码问题。只需要在tomcat的监听器里设置编码字符集如下(文件一般存储在 /tomcat安装目录/conf/server.xml ):
- <Connector port="80" protocol="HTTP/1.1"
- connectionTimeout="20000"
- redirectPort="8443" URIEncoding="utf-8" />
大家在开发的时候别忘了java文件本身也是有编码格式的。在类文件右键查看属性。
如果开发时忘记更改文件的编码格式,windows默认是GBK的,后来又要一直到utf8编码的linux怎么办。文件巨多,总不能一个一个去更改吧。其实很简单,只需要在java命令的环境参数设置 -Dfile.encoding=GBK 解决。
编译java代码时,如果使用ant需要在javac里设置编译的字符集。这样打印的log输出到文件或者控制台上就不会乱码了。
- <javac debuglevel= "source,lines" source= "1.6" encoding= "utf-8">
maven编译时设置的字符集:
- < artifactId> maven-compiler-plugin </artifactId >
- < version> 2.5 </version >
- < configuration>
- < optimize> true </optimize >
- < showDeprecation> false </showDeprecation >
- < debuglevel> lines,source </debuglevel >
- < source> 1.6 </source >
- < target> 1.6 </target >
- < encoding> UTF-8 </encoding >
- < meminitial> 128m </meminitial >
- < maxmem> 768m </maxmem >
- </ configuration>
sqlmap的sql xml,sping的xml 也是需要设置的,因为涉及到跨平台。 顶上添加:
- <!--?xml version="1.0" encoding="UTF-8"?-->
数据库:
这里列出大家用的最多的Mysql字符集设置。打开mysql的配置文件( linux 一般在 /etc/my.cnf ,windows在mysql的安装目录 my.ini)。设置如下:
- [mysqld]
- default-character-set = utf8
- [ mysql]
- character_set_server = utf8
jdbc需要设置
jdbc : mysql://192.168.0.237:3306/dzh_db?useUnicode=true&characterEncoding=UTF-8
这些都设置了一般的中文是不会有问题的。
不过最近出现了一个问题很搞怪。以前以为所有的字符只要设置好了所有数据都可以录入数据库,结果有些字符就不行,比如●■★这类型的。后来把这些字符变成字节码,居然不是三位utf8的,我擦,大汗淋漓。后来查询可以通过过滤utf8 特殊字符的方式处理。
#p#
- public static String Utf2String (byte buf[]) {
- int len = buf.length ;
- StringBuffer sb = new StringBuffer(len / 2);
- for (int i = 0; i < len; i++) {
- if (by2int(buf[i]) <= 0x7F)
- sb.append(( char ) buf[i]);
- else if (by2int(buf[i]) <= 0xDF && by2int(buf[i]) >= 0xC0) {
- int bh = by2int(buf[i] & 0x1F);
- int bl = by2int(buf[++i] & 0x3F);
- bl = by2int(bh << 6 | bl); bh = by2int(bh >> 2);
- int c = bh << 8 | bl;
- sb.append(( char ) c);
- } else if (by2int(buf[i]) <= 0xEF && by2int(buf[i]) >= 0xE0) {
- int bh = by2int(buf[i] & 0x0F);
- int bl = by2int(buf[++i] & 0x3F);
- int bll = by2int(buf[++i] & 0x3F);
- bh = by2int(bh << 4 | bl >> 2);
- bl = by2int(bl << 6 | bll);
- int c = bh << 8 | bl;
- // 空格转换为半角
- if (c == 58865) {
- c = 32;
- }
- sb.append(( char ) c);
- }
- }
- return sb.toString();
- }
或者把mysql的字符集改为 utf8mb4 ,记得这个只有mysql55支持哦!
- [mysqld]
- default-character-set =utf8mb4
- [ mysql]
- character_set_server = utf8mb4
操作系统:
windows默认是gbk,一般不需要变动。不过大家又想每个文件都要建立为utf8格式怎么办,不可能我们每个文件建立后都去用属性改变一下?太麻烦!直接在eclipse设置后,同种类型的文件建立都会是utf8格式。
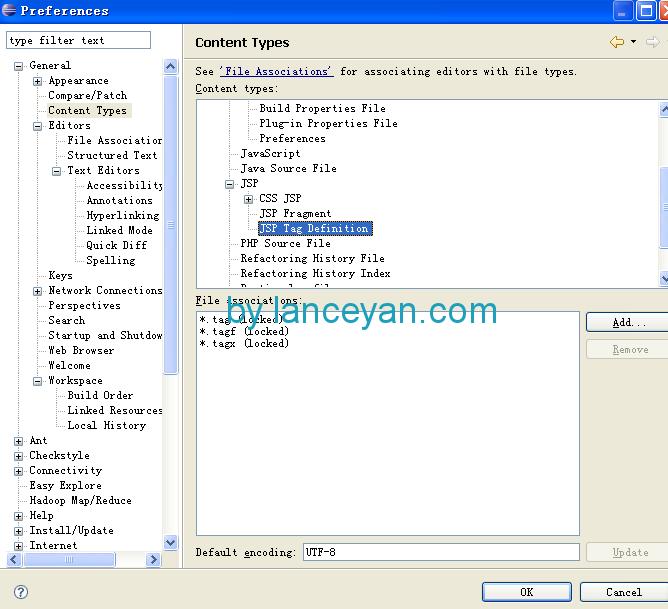
linux,可以有两个地方修改基本就足够了:
vi /etc/sysconfig/i18n
修改
- LANG="zh_CN.GB3212"
- LANGUAGE="zh_CN.GB18030:zh_CN.GB2312:zh_CN"
- SUPPORTED="zh_CN.GB18030:zh_CN:zh:en_US.UTF-8:en_US:en"
vi /etc/profile
- export LC_ALL="zh_CN.GB2312"
- export LANG="zh_CN.GB2312"











