MongoDB与Cassandra是两个***人气的NoSQL数据库,MongoDB更是NoSQL领域当之无愧的人气王,而Cassandra则常年霸占着列存储领域的***,相比之下备受关注的HBase却因众多原因一直屈居次席。近日MyDrive Soulutions运营和架构总监分享了这两个人气NoSQL数据库在其公司的实践,并给出了相关对比,以下为译文:
使用Cassandra替换MongoDB来管理时间序列后的飞跃
使用场景
MyDrive拥有一个基于AWS托管的数据处理平台,由Resque工作者负责。作为一个远程信息处理公司,我们需要处理非常多的时间序列数据,初始我们采用了MongoDB。作为初期方案,MongoDB最初定义就是临时性的选择。
MongoDB表现的也是相当不错,然而不同大小负载处理时间的不可预测性带来了很多困扰,同时也让数据处理管道的优化变得非常困难。基于MongoDB的设计(大部分的关系型数据库同样如此),返回30个文档与返回300个文档的作业将触发不同的I/O负载,而返回30个文档的作业肯定要比300个的快。当然不管是30还300,处理的速度都不是很快,即使使用了非常好的索引及非常合适的实例。
此后,我们不得不对MongoDB实例进行一定的纵向扩展;当然如果长期如此,将带来非常多的额外开销。
解决方案
从开始,目标就被锁定在Cassandra上,因为AboutUs 5.0之后的版本都使用了Cassandra。它已经向我们证明了强大的可靠性、可见性以及弹性。这些特色在整合了横向扩展之后,让Cassandra成为一个当之无愧的杀手级数据存储。
一般情况的数据流为写入数据>>读回>>修改>>写入>>再读取,这些操作被不同用户执行。虽然这不是Cassandra的设计理念,但是Cassandra却非常适合我们的查询方式。
Cassandra确实非常适合时间序列数据,因为可以周期性的将时间序列数据写入1列,然后通过部分字符串对比来查询一定时间范围内的数据。这样的话使用列就比使用行更加的高效,而加载单行可以让你获得巨大的I/O性能。然后Cassandra必须至少读取一个数据,而随着数据持久化到磁盘的进行,所有剩余的数据都将被读取。
我们使用时间戳作为ID的前半部分,这样的话就可以做任何时间段的范围查询——每行都体现出了一条数据,而列则体现了时间序列数据的一个周期。这样所有数据都可以通过键及起止时间查询。
鉴于我们工作负载的类型,使用MongoDB时,写操作的数量会严重影响到读的性能,而使用Cassandra就不会有这种情况发生。
前后对比
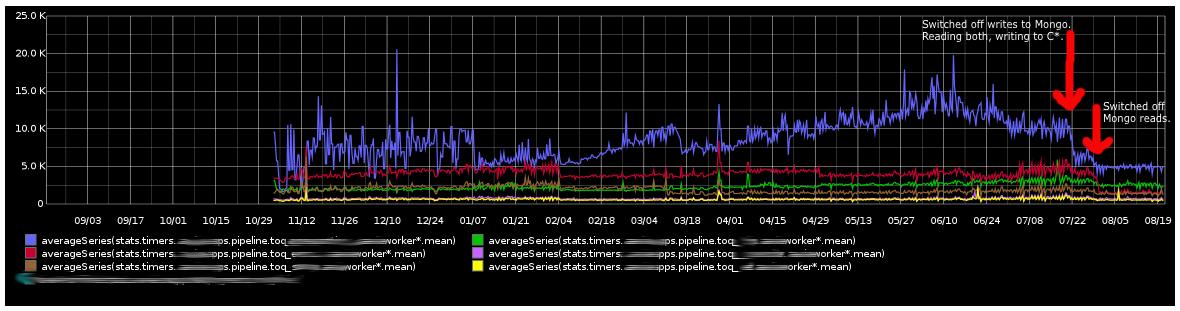
上面的突变显示大半年的性能,蓝线表示的是受数据存储性能影响的部分。很明显在做MongoDB优化及横向扩展硬件时性能的落差很大,然而这些对Cassandra毫无影响。
我们阶段化的关闭了MongoDB,开始是停止了对其写入,***停止了在MongoDB上的读操作(在图片上使用了红色箭头标注),不过图片上没有显示的是在过渡到Cassandra后加入了大量的批处理作业。